| Identification |
|---|
| HMDB Protein ID
| CDBP04767 |
| Secondary Accession Numbers
| Not Available |
| Name
| ATP-binding cassette sub-family C member 8 |
| Description
| Not Available |
| Synonyms
|
- Sulfonylurea receptor 1
|
| Gene Name
| ABCC8 |
| Protein Type
| Enzyme |
| Biological Properties |
|---|
| General Function
| Involved in ATP binding |
| Specific Function
| Putative subunit of the beta-cell ATP-sensitive potassium channel (KATP). Regulator of ATP-sensitive K(+) channels and insulin release |
| GO Classification
|
| Component |
| membrane |
| cell part |
| membrane part |
| intrinsic to membrane |
| integral to membrane |
| Function |
| atpase activity |
| active transmembrane transporter activity |
| molecular transducer activity |
| primary active transmembrane transporter activity |
| signal transducer activity |
| p-p-bond-hydrolysis-driven transmembrane transporter activity |
| transporter activity |
| atpase activity, coupled to transmembrane movement of substances |
| sulfonylurea receptor activity |
| binding |
| nucleoside-triphosphatase activity |
| nucleotide binding |
| hydrolase activity, acting on acid anhydrides |
| catalytic activity |
| hydrolase activity, acting on acid anhydrides, in phosphorus-containing anhydrides |
| hydrolase activity |
| pyrophosphatase activity |
| nucleoside binding |
| purine nucleoside binding |
| adenyl nucleotide binding |
| adenyl ribonucleotide binding |
| atp binding |
| receptor activity |
| transmembrane receptor activity |
| transmembrane transporter activity |
| Process |
| establishment of localization |
| transport |
| transmembrane transport |
| monovalent inorganic cation transport |
| potassium ion transport |
| ion transport |
| cation transport |
|
| Cellular Location
|
- Membrane
- Multi-pass membrane protein
|
| Pathways
|
| Name | SMPDB/Pathwhiz | KEGG | | Muscle/Heart Contraction | 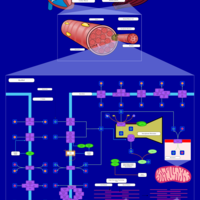 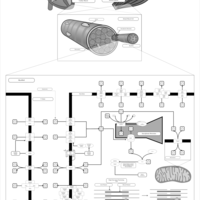  | Not Available | | Acebutolol Action Pathway | 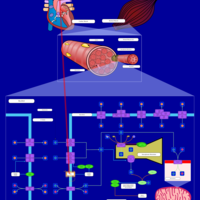 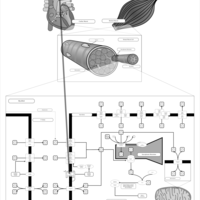  | Not Available | | Alprenolol Action Pathway | 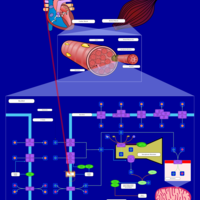 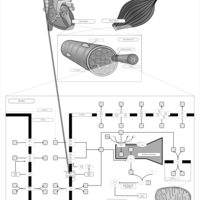  | Not Available | | Atenolol Action Pathway | 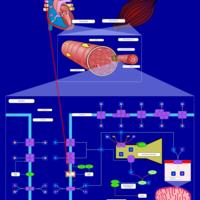   | Not Available | | Betaxolol Action Pathway | 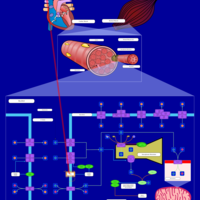   | Not Available |
|
| Gene Properties |
|---|
| Chromosome Location
| Chromosome:1 |
| Locus
| 11p15.1 |
| SNPs
| ABCC8 |
| Gene Sequence
|
>4746 bp
ATGCCCCTGGCCTTCTGCGGCAGCGAGAACCACTCGGCCGCCTACCGGGTGGACCAGGGG
GTCCTCAACAACGGCTGCTTTGTGGACGCGCTCAACGTGGTGCCGCACGTCTTCCTACTC
TTCATCACCTTCCCCATCCTCTTCATTGGATGGGGAAGTCAGAGCTCCAAGGTGCACATC
CACCACAGCACATGGCTTCATTTCCCTGGGCACAACCTGCGGTGGATCCTGACCTTCATG
CTGCTCTTCGTCCTGGTGTGTGAGATTGCAGAGGGCATCCTGTCTGATGGGGTGACCGAA
TCCCACCATCTGCACCTGTACATGCCAGCCGGGATGGCGTTCATGGCTGCTGTCACCTCC
GTGGTCTACTATCACAACATCGAGACTTCCAACTTCCCCAAGCTGCTAATTGCCCTGCTG
GTGTATTGGACCCTGGCCTTCATCACCAAGACCATCAAGTTTGTCAAGTTCTTGGACCAC
GCCATCGGCTTCTCGCAGCTACGCTTCTGCCTCACAGGGCTGCTGGTGATCCTCTATGGG
ATGCTGCTCCTCGTGGAGGTCAATGTCATCAGGGTGAGGAGATACATCTTCTTCAAGACA
CCGAGGGAGGTGAAGCCTCCCGAGGACCTGCAAGACCTGGGGGTACGCTTCCTGCAGCCC
TTCGTGAATCTGCTGTCCAAAGGCACCTACTGGTGGATGAACGCCTTCATCAAGACTGCC
CACAAGAAGCCCATCGACTTGCGAGCCATCGGGAAGCTGCCCATCGCCATGAGGGCCCTC
ACCAACTACCAACGGCTCTGCGAGGCCTTTGACGCCCAGGTGCGGAAGGACATTCAGGGC
ACTCAAGGTGCCCGGGCCATCTGGCAGGCACTCAGCCATGCCTTCGGGAGGCGCCTGGTC
CTCAGCAGCACTTTCCGCATCTTGGCCGACCTGCTGGGCTTCGCCGGGCCACTGTGCATC
TTTGGGATCGTGGACCACCTTGGGAAGGAGAACGACGTCTTCCAGCCCAAGACACAATTT
CTCGGGGTTTACTTTGTCTCATCCCAAGAGTTCCTTGCCAATGCCTACGTCTTAGCTGTG
CTTCTGTTCCTTGCCCTCCTACTGCAAAGGACATTTCTGCAAGCATCCTACTATGTGGCC
ATTGAAACTGGAATTAACTTGAGAGGAGCAATACAGACCAAGATTTACAATAAAATTATG
CACCTGTCCACCTCCAACCTGTCCATGGGAGAAATGACTGCTGGACAGATCTGTAATCTG
GTTGCCATCGACACCAATCAGCTCATGTGGTTTTTCTTCTTGTGCCCAAACCTCTGGGCT
ATGCCAGTACAGATCATTGTGGGTGTGATTCTCCTCTACTACATACTCGGAGTCAGTGCC
TTAATTGGAGCAGCTGTCATCATTCTACTGGCTCCTGTCCAGTACTTCGTGGCCACCAAG
CTGTCTCAGGCCCAGCGGAGCACACTGGAGTATTCCAATGAGCGGCTGAAGCAGACCAAC
GAGATGCTCCGCGGCATCAAGCTGCTGAAGCTGTACGCCTGGGAGAACATCTTCCGCACG
CGGGTGGAGACGACCCGCAGGAAGGAGATGACCAGCCTCAGGGCCTTTGCCATCTATACC
TCCATCTCCATTTTCATGAACACGGCCATCCCCATTGCAGCTGTCCTCATAACTTTCGTG
GGCCACGTCAGCTTCTTCAAAGAGGCCGACTTCTCGCCCTCCGTGGCCTTTGCCTCCCTC
TCCCTCTTCCATATCTTGGTCACACCGCTGTTCCTGCTGTCCAGTGTGGTCCGATCTACC
GTCAAAGCTCTAGTGAGCGTGCAAAAGCTAAGCGAGTTCCTGTCCAGTGCAGAGATCCGT
GAGGAGCAGTGTGCCCCCCATGAGCCCACACCTCAGGGCCCAGCCAGCAAGTACCAGGCG
GTGCCCCTCAGGGTTGTGAACCGCAAGCGTCCAGCCCGGGAGGATTGTCGGGGCCTCACC
GGCCCACTGCAGAGCCTGGTCCCCAGTGCAGATGGCGATGCTGACAACTGCTGTGTCCAG
ATCATGGGAGGCTACTTCACGTGGACCCCAGATGGAATCCCCACACTGTCCAACATCACC
ATTCGTATCCCCCGAGGCCAGCTGACTATGATCGTGGGGCAGGTGGGCTGCGGCAAGTCC
TCGCTCCTTCTAGCCGCACTGGGGGAGATGCAGAAGGTCTCAGGGGCTGTCTTCTGGAGC
AGCCTTCCTGACAGCGAGATAGGAGAGGACCCCAGCCCAGAGCGGGAGACAGCGACCGAC
TTGGATATCAGGAAGAGAGGCCCCGTGGCCTATGCTTCGCAGAAACCATGGCTGCTAAAT
GCCACTGTGGAGGAGAACATCATCTTTGAGAGTCCCTTCAACAAACAACGGTACAAGATG
GTCATTGAAGCCTGCTCTCTGCAGCCAGACATCGACATCCTGCCCCATGGAGACCAGACC
CAGATTGGGGAACGGGGCATCAACCTGTCTGGTGGTCAACGCCAGCGAATCAGTGTGGCC
CGAGCCCTCTACCAGCACGCCAACGTTGTCTTCTTGGATGACCCCTTCTCAGCTCTGGAT
ATCCATCTGAGTGACCACTTAATGCAGGCCGGCATCCTTGAGCTGCTCCGGGACGACAAG
AGGACAGTGGTCTTAGTGACCCACAAGCTACAGTACCTGCCCCATGCAGACTGGATCATT
GCCATGAAGGATGGCACCATCCAGAGGGAGGGTACCCTCAAGGACTTCCAGAGGTCTGAA
TGCCAGCTCTTTGAGCACTGGAAGACCCTCATGAACCGACAGGACCAAGAGCTGGAGAAG
GAGACTGTCACAGAGAGAAAAGCCACAGAGCCACCCCAGGGCCTATCTCGTGCCATGTCC
TCGAGGGATGGCCTTCTGCAGGATGAGGAAGAGGAGGAAGAGGAGGCAGCTGAGAGCGAG
GAGGATGACAACCTGTCGTCCATGCTGCACCAGCGTGCTGAGATCCCATGGCGAGCCTGC
GCCAAGTACCTGTCCTCCGCCGGCATCCTGCTCCTGTCGTTGCTGGTCTTCTCACAGCTG
CTCAAGCACATGGTCCTGGTGGCCATCGACTACTGGCTGGCCAAGTGGACCGACAGCGCC
CTGACCCTGACCCCTGCAGCCAGGAACTGCTCCCTCAGCCAGGAGTGCACCCTCGACCAG
ACTGTCTATGCCATGGTGTTCACGGTGCTCTGCAGCCTGGGCATTGTGCTGTGCCTCGTC
ACGTCTGTCACTGTGGAGTGGACAGGGCTGAAGGTGGCCAAGAGACTGCACCGCAGCCTG
CTAAACCGGATCATCCTAGCCCCCATGAGGTTTTTTGAGACCACGCCCCTTGGGAGCATC
CTGAACAGATTTTCATCTGACTGTAACACCATCGACCAGCACATCCCATCCACGCTGGAG
TGCCTGAGCCGCTCCACCCTGCTCTGTGTCTCAGCCCTGGCCGTCATCTCCTATGTCACA
CCTGTGTTCCTCGTGGCCCTCTTGCCCCTGGCCATCGTGTGCTACTTCATCCAGAAGTAC
TTCCGGGTGGCGTCCAGGGACCTGCAGCAGCTGGATGACACCACCCAGCTTCCACTTCTC
TCACACTTTGCCGAAACCGTAGAAGGACTCACCACCATCCGGGCCTTCAGGTATGAGGCC
CGGTTCCAGCAGAAGCTTCTCGAATACACAGACTCCAACAACATTGCTTCCCTCTTCCTC
ACAGCTGCCAACAGATGGCTGGAAGTCCGAATGGAGTACATCGGTGCATGTGTGGTGCTC
ATCGCAGCGGTGACCTCCATCTCCAACTCCCTGCACAGGGAGCTCTCTGCTGGCCTGGTG
GGCCTGGGCCTTACCTACGCCCTAATGGTCTCCAACTACCTCAACTGGATGGTGAGGAAC
CTGGCAGACATGGAGCTCCAGCTGGGGGCTGTGAAGCGCATCCATGGGCTCCTGAAAACC
GAGGCAGAGAGCTACGAGGGGCTCCTGGCACCATCGCTGATCCCAAAGAACTGGCCAGAC
CAAGGGAAGATCCAGATCCAGAACCTGAGCGTGCGCTACGACAGCTCCCTGAAGCCGGTG
CTGAAGCACGTCAATGCCCTCATCGCCCCTGGACAGAAGATCGGGATCTGCGGCCGCACC
GGCAGTGGGAAGTCCTCCTTCTCTCTTGCCTTCTTCCGCATGGTGGACACGTTCGAAGGG
CACATCATCATTGATGGCATTGACATCGCCAAACTGCCGCTGCACACCCTGCGCTCACGC
CTCTCCATCATCCTGCAGGACCCCGTCCTCTTCAGCGGCACCATCCGATTTAACCTGGAC
CCTGAGAGGAAGTGCTCAGATAGCACACTGTGGGAGGCCCTGGAAATCGCCCAGCTGAAG
CTGGTGGTGAAGGCACTGCCAGGAGGCCTCGATGCCATCATCACAGAAGGCGGGGAGAAT
TTCAGCCAGGGACAGAGGCAGCTGTTCTGCCTGGCCCGGGCCTTCGTGAGGAAGACCAGC
ATCTTCATCATGGACGAGGCCACGGCTTCCATTGACATGGCCACGGAAAACATCCTCCAA
AAGGTGGTGATGACAGCCTTCGCAGACCGCACTGTGGTCACCATCGCGCATCGAGTGCAC
ACCATCCTGAGTGCAGACCTGGTGATCGTCCTGAAGCGGGGTGCCATCCTTGAGTTCGAT
AAGCCAGAGAAGCTGCTCAGCCGGAAGGACAGCGTCTTCGCCTCCTTCGTCCGTGCAGAC
AAGTGA
|
| Protein Properties |
|---|
| Number of Residues
| 1581 |
| Molecular Weight
| 177006.4 |
| Theoretical pI
| 7.86 |
| Pfam Domain Function
|
|
| Signals
|
|
|
Transmembrane Regions
|
- ["35-55", "76-96", "102-122", "135-154", "168-194", "312-331", "356-376", "435-455", "459-479", "542-562", "585-605", "1005-1025", "1073-1093", "1138-1158", "1160-1180", "1252-1272", "1277-1297"]
|
| Protein Sequence
|
>ATP-binding cassette sub-family C member 8
MPLAFCGSENHSAAYRVDQGVLNNGCFVDALNVVPHVFLLFITFPILFIGWGSQSSKVHI
HHSTWLHFPGHNLRWILTFMLLFVLVCEIAEGILSDGVTESHHLHLYMPAGMAFMAAVTS
VVYYHNIETSNFPKLLIALLVYWTLAFITKTIKFVKFLDHAIGFSQLRFCLTGLLVILYG
MLLLVEVNVIRVRRYIFFKTPREVKPPEDLQDLGVRFLQPFVNLLSKGTYWWMNAFIKTA
HKKPIDLRAIGKLPIAMRALTNYQRLCEAFDAQVRKDIQGTQGARAIWQALSHAFGRRLV
LSSTFRILADLLGFAGPLCIFGIVDHLGKENDVFQPKTQFLGVYFVSSQEFLANAYVLAV
LLFLALLLQRTFLQASYYVAIETGINLRGAIQTKIYNKIMHLSTSNLSMGEMTAGQICNL
VAIDTNQLMWFFFLCPNLWAMPVQIIVGVILLYYILGVSALIGAAVIILLAPVQYFVATK
LSQAQRSTLEYSNERLKQTNEMLRGIKLLKLYAWENIFRTRVETTRRKEMTSLRAFAIYT
SISIFMNTAIPIAAVLITFVGHVSFFKEADFSPSVAFASLSLFHILVTPLFLLSSVVRST
VKALVSVQKLSEFLSSAEIREEQCAPHEPTPQGPASKYQAVPLRVVNRKRPAREDCRGLT
GPLQSLVPSADGDADNCCVQIMGGYFTWTPDGIPTLSNITIRIPRGQLTMIVGQVGCGKS
SLLLAALGEMQKVSGAVFWSSLPDSEIGEDPSPERETATDLDIRKRGPVAYASQKPWLLN
ATVEENIIFESPFNKQRYKMVIEACSLQPDIDILPHGDQTQIGERGINLSGGQRQRISVA
RALYQHANVVFLDDPFSALDIHLSDHLMQAGILELLRDDKRTVVLVTHKLQYLPHADWII
AMKDGTIQREGTLKDFQRSECQLFEHWKTLMNRQDQELEKETVTERKATEPPQGLSRAMS
SRDGLLQDEEEEEEEAAESEEDDNLSSMLHQRAEIPWRACAKYLSSAGILLLSLLVFSQL
LKHMVLVAIDYWLAKWTDSALTLTPAARNCSLSQECTLDQTVYAMVFTVLCSLGIVLCLV
TSVTVEWTGLKVAKRLHRSLLNRIILAPMRFFETTPLGSILNRFSSDCNTIDQHIPSTLE
CLSRSTLLCVSALAVISYVTPVFLVALLPLAIVCYFIQKYFRVASRDLQQLDDTTQLPLL
SHFAETVEGLTTIRAFRYEARFQQKLLEYTDSNNIASLFLTAANRWLEVRMEYIGACVVL
IAAVTSISNSLHRELSAGLVGLGLTYALMVSNYLNWMVRNLADMELQLGAVKRIHGLLKT
EAESYEGLLAPSLIPKNWPDQGKIQIQNLSVRYDSSLKPVLKHVNALISPGQKIGICGRT
GSGKSSFSLAFFRMVDTFEGHIIIDGIDIAKLPLHTLRSRLSIILQDPVLFSGTIRFNLD
PERKCSDSTLWEALEIAQLKLVVKALPGGLDAIITEGGENFSQGQRQLFCLARAFVRKTS
IFIMDEATASIDMATENILQKVVMTAFADRTVVTIAHRVHTILSADLVIVLKRGAILEFD
KPEKLLSRKDSVFASFVRADK
|
| External Links |
|---|
| GenBank ID Protein
| 118582255 |
| UniProtKB/Swiss-Prot ID
| Q09428 |
| UniProtKB/Swiss-Prot Entry Name
| ABCC8_HUMAN |
| PDB IDs
|
Not Available |
| GenBank Gene ID
| NM_000352.3 |
| GeneCard ID
| ABCC8 |
| GenAtlas ID
| ABCC8 |
| HGNC ID
| HGNC:59 |
| References |
|---|
| General References
| Not Available |