| Identification |
|---|
| HMDB Protein ID
| CDBP04764 |
| Secondary Accession Numbers
| Not Available |
| Name
| Guanine nucleotide-binding protein G(s) subunit alpha isoforms XLas |
| Description
| Not Available |
| Synonyms
|
- Adenylate cyclase-stimulating G alpha protein
- Extra large alphas protein
- XLalphas
|
| Gene Name
| GNAS |
| Protein Type
| Receptor |
| Biological Properties |
|---|
| General Function
| Involved in signal transducer activity |
| Specific Function
| Guanine nucleotide-binding proteins (G proteins) are involved as modulators or transducers in various transmembrane signaling systems. The G(s) protein is involved in hormonal regulation of adenylate cyclase:it activates the cyclase in response to beta-adrenergic stimuli. XLas isoforms interact with the same set of receptors as Gnas isoforms |
| GO Classification
|
| Function |
| purine nucleotide binding |
| binding |
| nucleotide binding |
| guanyl nucleotide binding |
| guanyl ribonucleotide binding |
| gtp binding |
| molecular transducer activity |
| signal transducer activity |
| Process |
| cell surface receptor linked signaling pathway |
| g-protein coupled receptor protein signaling pathway |
| biological regulation |
| regulation of biological process |
| regulation of cellular process |
| signal transduction |
| signaling |
| signaling pathway |
|
| Cellular Location
|
- Cell membrane
- Peripheral membrane protein
|
| Pathways
|
| Name | SMPDB/Pathwhiz | KEGG | | Lysophosphatidic Acid LPA6 Signalling | 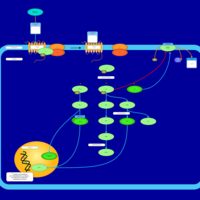 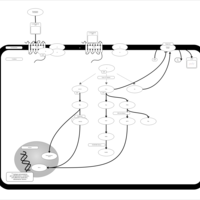 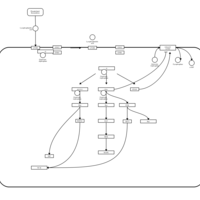 | Not Available | | Lysophosphatidic Acid LPA5 Signalling | 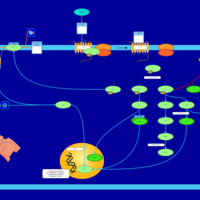 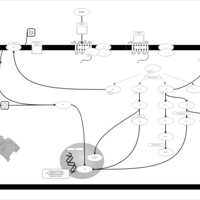 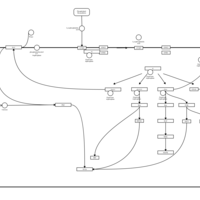 | Not Available | | Lysophosphatidic Acid LPA4 Signalling | 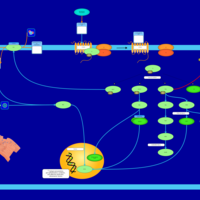 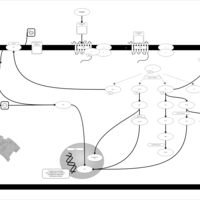  | Not Available | | Lysophosphatidic Acid LPA3 Signalling | 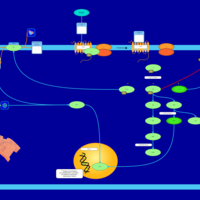 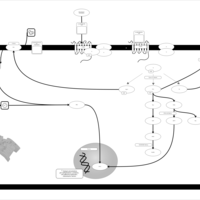 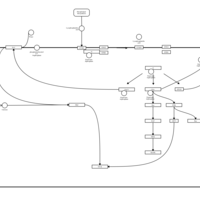 | Not Available |
|
| Gene Properties |
|---|
| Chromosome Location
| Chromosome:2 |
| Locus
| 20q13.3 |
| SNPs
| GNAS |
| Gene Sequence
|
>3114 bp
ATGGGCGTGCGCAACTGCCTCTACGGCAATAATATGTCAGGACAACGCGATATCCCCCCT
GAAATCGGGGAACAGCCCGAGCAACCACCTTTGGAGGCCCCAGGGGCAGCTGCCCCCGGT
GCTGGGCCTAGCCCAGCCGAAGAGATGGAGACCGAACCGCCTCACAACGAGCCCATCCCC
GTCGAGAATGATGGCGAGGCCTGTGGACCCCCAGAGGTCTCCAGACCCAACTTTCAGGTC
CTCAACCCGGCATTCAGGGAAGCTGGAGCCCATGGAAGCTACAGCCCACCTCCTGAGGAA
GCAATGCCCTTCGAGGCTGAACAGCCCAGCTTGGGAGGCTTCTGGCCTACACTGGAGCAG
CCTGGATTCCCCAGTGGGGTCCATGCAGGCCTTGAGGCCTTCGGCCCAGCACTCATGGAG
CCCGGAGCCTTCAGTGGTGCCAGACCAGGCCTGGGAGGATACAGCCCTCCACCAGAAGAA
GCTATGCCCTTTGAGTTTGACCAGCCTGCCCAGAGAGGCTGCAGTCAACTTCTCTTACAG
GTCCCAGACCTTGCTCCAGGAGGCCCAGGTGCTGCAGGGGTCCCCGGAGCTCCTCCCGAG
GAGCCCCAAGCCCTCAGGCCTGCAAAGGCTGGCTCCAGAGGAGGCTACAGCCCTCCCCCT
GAGGAGACTATGCCATTTGAGCTTGATGGAGAAGGATTTGGGGACGACAGCCCACCCCCG
GGGCTTTCCCGAGTTATCGCACAAGTCGACGGCAGCAGCCAGTTCGCGGCAGTCGCGGCC
TCGAGTGCGGTCCGCCTCACTCCCGCCGCGAACGCGCCTCCCCTCTGGGTCCCAGGCGCC
ATCGGCAGCCCATCCCAAGAGGCTGTCAGACCTCCTTCTAACTTCACGGGCAGCAGCCCC
TGGATGGAGATCTCCGGACCCCCGTTCGAGATTGGCAGCGCCCCCGCTGGGGTCGACGAC
ACTCCCGTCAACATGGACAGCCCCCCAATCGCGCTTGACGGCCCGCCCATCAAGGTCTCC
GGAGCCCCAGATAAGAGAGAGCGAGCAGAGAGACCCCCAGTTGAGGAGGAAGCAGCAGAG
ATGGAAGGAGCCGCTGATGCCGCGGAGGGAGGAAAAGTACCCTCTCCGGGGTACGGATCC
CCTGCCGCCGGGGCAGCCTCAGCGGATACCGCTGCCAGGGCAGCCCCTGCAGCCCCAGCC
GATCCTGACTCCGGGGCAACCCCAGAAGATCCCGACTCCGGGACAGCACCAGCCGATCCT
GACTCCGGGGCATTCGCAGCCGATCCCGACTCCGGGGCAGCCCCTGCCGCCCCAGCCGAT
CCCGACTCCGGGGCGGCCCCTGACGCCCCAGCCGATCCCGACTCCGGGGCGGCCCCTGAC
GCCCCAGCCGATCCAGATGCCGGGGCGGCCCCTGAGGCTCCCGCCGCCCCTGCGGCTGCT
GAGACCCGGGCAGCCCATGTCGCCCCAGCTGCGCCAGACGCAGGGGCTCCCACTGCCCCA
GCCGCTTCTGCCACCCGGGCAGCCCAAGTCCGCCGGGCGGCCTCTGCAGCCCCTGCCTCC
GGGGCCAGACGCAAGATCCATCTCAGACCCCCCAGCCCCGAGATCCAGGCTGCCGATCCG
CCTACTCCGCGGCCTACTCGCGCGTCTGCCTGGCGGGGCAAGTCCGAGAGCAGCCGCGGC
CGCCGCGTGTACTACGATGAAGGGGTGGCCAGCAGCGACGATGACTCCAGCGGAGACGAG
TCCGACGATGGGACCTCCGGATGCCTCCGCTGGTTTCAGCATCGGCGAAATCGCCGCCGC
CGAAAGCCCCAGCGCAACTTACTCCGCAACTTTCTCGTGCAAGCCTTCGGGGGCTGCTTC
GGTCGATCTGAGAGTCCCCAGCCCAAAGCCTCGCGCTCTCTCAAGGTCAAGAAGGTACCC
CTGGCGGAGAAGCGCAGACAGATGCGCAAAGAAGCCCTGGAGAAGCGGGCCCAGAAGCGC
GCAGAGAAGAAACGCAGTAAGCTCATCGACAAACAACTCCAGGACGAAAAGATGGGCTAC
ATGTGTACGCACCGCCTGCTGCTTCTAGGTGCTGGAGAATCTGGTAAAAGCACCATTGTG
AAGCAGATGAGGATCCTGCATGTTAATGGGTTTAATGGAGAGGGCGGCGAAGAGGACCCG
CAGGCTGCAAGGAGCAACAGCGATGGTGAGAAGGCAACCAAAGTGCAGGACATCAAAAAC
AACCTGAAAGAGGCGATTGAAACCATTGTGGCCGCCATGAGCAACCTGGTGCCCCCCGTG
GAGCTGGCCAACCCCGAGAACCAGTTCAGAGTGGACTACATCCTGAGTGTGATGAACGTG
CCTGACTTTGACTTCCCTCCCGAATTCTATGAGCATGCCAAGGCTCTGTGGGAGGATGAA
GGAGTGCGTGCCTGCTACGAACGCTCCAACGAGTACCAGCTGATTGACTGTGCCCAGTAC
TTCCTGGACAAGATCGACGTGATCAAGCAGGCTGACTATGTGCCGAGCGATCAGGACCTG
CTTCGCTGCCGTGTCCTGACTTCTGGAATCTTTGAGACCAAGTTCCAGGTGGACAAAGTC
AACTTCCACATGTTTGACGTGGGTGGCCAGCGCGATGAACGCCGCAAGTGGATCCAGTGC
TTCAACGATGTGACTGCCATCATCTTCGTGGTGGCCAGCAGCAGCTACAACATGGTCATC
CGGGAGGACAACCAGACCAACCGCCTGCAGGAGGCTCTGAACCTCTTCAAGAGCATCTGG
AACAACAGATGGCTGCGCACCATCTCTGTGATCCTGTTCCTCAACAAGCAAGATCTGCTC
GCTGAGAAAGTCCTTGCTGGGAAATCGAAGATTGAGGACTACTTTCCAGAATTTGCTCGC
TACACTACTCCTGAGGATGCTACTCCCGAGCCCGGAGAGGACCCACGCGTGACCCGGGCC
AAGTACTTCATTCGAGATGAGTTTCTGAGGATCAGCACTGCCAGTGGAGATGGGCGTCAC
TACTGCTACCCTCATTTCACCTGCGCTGTGGACACTGAGAACATCCGCCGTGTGTTCAAC
GACTGCCGTGACATCATTCAGCGCATGCACCTTCGTCAGTACGAGCTGCTCTAA
|
| Protein Properties |
|---|
| Number of Residues
| 1037 |
| Molecular Weight
| 111023.3 |
| Theoretical pI
| 4.65 |
| Pfam Domain Function
|
|
| Signals
|
|
|
Transmembrane Regions
|
|
| Protein Sequence
|
>Guanine nucleotide-binding protein G(s) subunit alpha isoforms XLas
MGVRNCLYGNNMSGQRDIPPEIGEQPEQPPLEAPGAAAPGAGPSPAEEMETEPPHNEPIP
VENDGEACGPPEVSRPNFQVLNPAFREAGAHGSYSPPPEEAMPFEAEQPSLGGFWPTLEQ
PGFPSGVHAGLEAFGPALMEPGAFSGARPGLGGYSPPPEEAMPFEFDQPAQRGCSQLLLQ
VPDLAPGGPGAAGVPGAPPEEPQALRPAKAGSRGGYSPPPEETMPFELDGEGFGDDSPPP
GLSRVIAQVDGSSQFAAVAASSAVRLTPAANAPPLWVPGAIGSPSQEAVRPPSNFTGSSP
WMEISGPPFEIGSAPAGVDDTPVNMDSPPIALDGPPIKVSGAPDKRERAERPPVEEEAAE
MEGAADAAEGGKVPSPGYGSPAAGAASADTAARAAPAAPADPDSGATPEDPDSGTAPADP
DSGAFAADPDSGAAPAAPADPDSGAAPDAPADPDSGAAPDAPADPDAGAAPEAPAAPAAA
ETRAAHVAPAAPDAGAPTAPAASATRAAQVRRAASAAPASGARRKIHLRPPSPEIQAADP
PTPRPTRASAWRGKSESSRGRRVYYDEGVASSDDDSSGDESDDGTSGCLRWFQHRRNRRR
RKPQRNLLRNFLVQAFGGCFGRSESPQPKASRSLKVKKVPLAEKRRQMRKEALEKRAQKR
AEKKRSKLIDKQLQDEKMGYMCTHRLLLLGAGESGKSTIVKQMRILHVNGFNGEGGEEDP
QAARSNSDGEKATKVQDIKNNLKEAIETIVAAMSNLVPPVELANPENQFRVDYILSVMNV
PDFDFPPEFYEHAKALWEDEGVRACYERSNEYQLIDCAQYFLDKIDVIKQADYVPSDQDL
LRCRVLTSGIFETKFQVDKVNFHMFDVGGQRDERRKWIQCFNDVTAIIFVVASSSYNMVI
REDNQTNRLQEALNLFKSIWNNRWLRTISVILFLNKQDLLAEKVLAGKSKIEDYFPEFAR
YTTPEDATPEPGEDPRVTRAKYFIRDEFLRISTASGDGRHYCYPHFTCAVDTENIRRVFN
DCRDIIQRMHLRQYELL
|
| External Links |
|---|
| GenBank ID Protein
| 117938759 |
| UniProtKB/Swiss-Prot ID
| Q5JWF2 |
| UniProtKB/Swiss-Prot Entry Name
| GNAS1_HUMAN |
| PDB IDs
|
|
| GenBank Gene ID
| NM_080425.2 |
| GeneCard ID
| GNAS |
| GenAtlas ID
| GNAS |
| HGNC ID
| HGNC:4392 |
| References |
|---|
| General References
| Not Available |