| Identification |
|---|
| HMDB Protein ID
| CDBP04469 |
| Secondary Accession Numbers
| Not Available |
| Name
| DNA-directed RNA polymerase I subunit RPA1 |
| Description
| Not Available |
| Synonyms
|
- A190
- DNA-directed RNA polymerase I largest subunit
- DNA-directed RNA polymerase I subunit A
- RNA polymerase I 194 kDa subunit
- RNA polymerase I subunit A1
- RPA194
|
| Gene Name
| POLR1A |
| Protein Type
| Enzyme |
| Biological Properties |
|---|
| General Function
| Involved in DNA binding |
| Specific Function
| DNA-dependent RNA polymerase catalyzes the transcription of DNA into RNA using the four ribonucleoside triphosphates as substrates. Largest and catalytic core component of RNA polymerase I which synthesizes ribosomal RNA precursors. Forms the polymerase active center together with the second largest subunit. A single stranded DNA template strand of the promoter is positioned within the central active site cleft of Pol I. A bridging helix emanates from RPA1 and crosses the cleft near the catalytic site and is thought to promote translocation of Pol I by acting as a ratchet that moves the RNA-DNA hybrid through the active site by switching from straight to bent conformations at each step of nucleotide addition (By similarity).
|
| GO Classification
|
| Biological Process |
| rRNA transcription |
| termination of RNA polymerase I transcription |
| transcription elongation from RNA polymerase I promoter |
| transcription initiation from RNA polymerase I promoter |
| Cellular Component |
| nucleoplasm |
| DNA-directed RNA polymerase I complex |
| Function |
| binding |
| catalytic activity |
| transferase activity |
| transferase activity, transferring phosphorus-containing groups |
| nucleotidyltransferase activity |
| nucleic acid binding |
| dna binding |
| rna polymerase activity |
| dna-directed rna polymerase activity |
| Molecular Function |
| metal ion binding |
| zinc ion binding |
| DNA-directed RNA polymerase activity |
| DNA binding |
| Process |
| macromolecule biosynthetic process |
| cellular macromolecule biosynthetic process |
| metabolic process |
| biosynthetic process |
| transcription |
|
| Cellular Location
|
- Nucleus
- nucleolus
|
| Pathways
|
| Name | SMPDB/Pathwhiz | KEGG | | Nucleotide Excision Repair |    | Not Available | | RNA polymerase | Not Available | 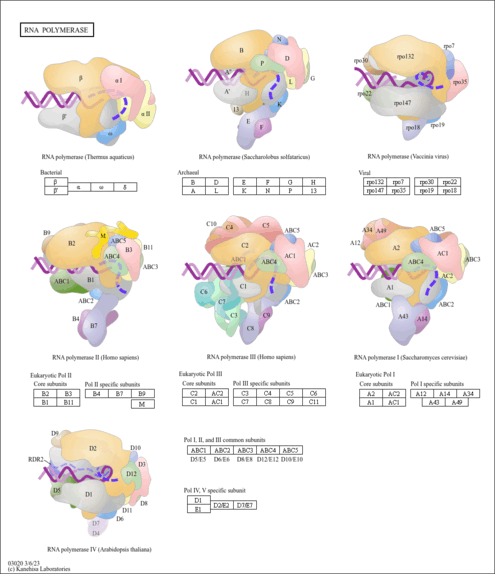 |
|
| Gene Properties |
|---|
| Chromosome Location
| 2 |
| Locus
| 2p11.2 |
| SNPs
| POLR1A |
| Gene Sequence
|
>5163 bp
ATGTTGATCTCCAAGAACATGCCCTGGCGGCGGCTGCAGGGCATTTCCTTCGGGATGTAT
TCGGCTGAAGAGCTCAAGAAATTAAGTGTTAAATCCATTACGAACCCTCGATACCTGGAC
AGCCTGGGGAACCCATCGGCAAACGGCCTGTACGATTTAGCTTTGGGCCCTGCAGATTCC
AAAGAGGTGTGCTCCACCTGCGTGCAGGACTTCAGCAACTGTTCTGGGCACCTGGGCCAC
ATTGAGCTCCCACTCACAGTGTATAACCCTCTCCTCTTCGATAAGCTGTACCTGCTGCTT
CGGGGCTCTTGTTTAAACTGCCACATGCTGACTTGTCCCCGGGCCGTGATTCACCTCTTA
CTCTGCCAGCTGAGGGTTCTGGAAGTCGGGGCCCTACAAGCAGTCTACGAGCTTGAGAGA
ATTCTGAACAGGTTTCTGGAAGAAAATCCCGATCCCTCTGCCTCTGAAATTCGGGAGGAA
TTAGAACAATACACAACTGAAATTGTGCAGAACAACCTCCTGGGGTCCCAGGGCGCACAT
GTAAAGAACGTGTGTGAGAGCAAGAGCAAGCTCATTGCTCTCTTCTGGAAGGCACATATG
AATGCTAAGCGCTGTCCCCACTGCAAGACCGGGCGATCCGTTGTCCGAAAGGAACACAAC
AGCAAGTTGACTATCACGTTTCCAGCCATGGTGCACAGGACAGCTGGCCAGAAGGACTCT
GAGCCCCTGGGAATTGAGGAAGCTCAGATAGGAAAACGAGGATACTTAACACCCACCAGT
GCCCGCGAACACCTTTCTGCCCTGTGGAAGAATGAAGGATTCTTTCTGAACTACCTTTTT
TCGGGAATGGATGATGATGGTATGGAATCCAGATTCAATCCCAGTGTGTTCTTTCTAGAT
TTCTTGGTGGTGCCGCCCTCAAGGTATCGCCCAGTCAGTCGCCTAGGAGACCAGATGTTT
ACTAATGGCCAGACGGTGAACTTGCAGGCTGTCATGAAGGATGTAGTTCTGATTCGAAAA
CTTCTGGCATTGATGGCCCAAGAACAGAAGTTGCCAGAGGAAGTGGCCACACCCACTACA
GATGAGGAAAAAGACTCTTTGATTGCTATTGACCGATCCTTTTTGAGTACACTTCCAGGC
CAGTCCCTCATAGACAAACTTTACAACATTTGGATTCGCCTTCAGAGCCACGTCAATATT
GTGTTTGATAGCGAGATGGACAAACTAATGATGGACAAGTACCCAGGCATTAGGCAGATC
CTGGAGAAGAAAGAAGGCCTGTTCCGAAAACACATGATGGGAAAGCGAGTGGACTACGCT
GCGCGCTCAGTCATCTGCCCAGACATGTACATCAACACCAACGAAATTGGAATTCCCATG
GTGTTTGCCACAAAACTGACCTACCCACAGCCAGTTACCCCATGGAATGTTCAGGAACTT
AGGCAAGCGGTCATCAACGGCCCTAATGTGCACCCAGGAGCCTCCATGGTCATCAATGAG
GACGGCAGCCGCACAGCCCTGAGCGCTGTGGACATGACCCAGCGAGAGGCCGTGGCCAAG
CAGCTTCTGACCCCAGCCACGGGGGCACCTAAGCCCCAGGGGACAAAAATTGTGTGCCGG
CATGTGAAGAATGGGGACATTCTGCTACTGAACCGACAGCCCACACTGCACAGACCCTCC
ATCCAGGCCCACCGTGCCCGCATCCTGCCTGAAGAGAAAGTGCTGCGGCTCCACTATGCC
AACTGCAAGGCCTATAATGCCGACTTTGATGGAGACGAGATGAATGCCCATTTCCCCCAG
AGTGAGCTGGGCCGGGCCGAGGCCTACGTCCTGGCCTGCACTGATCAGCAGTACCTTGTT
CCCAAGGATGGCCAACCATTGGCGGGACTGATCCAGGATCACATGGTTTCAGGGGCAAGC
ATGACTACTCGGGGTTGCTTTTTCACCCGGGAGCACTATATGGAGCTGGTGTACCGAGGA
CTCACGGACAAAGTGGGGCGCGTGAAGCTCCTTTCTCCTTCCATCCTGAAGCCCTTTCCG
CTGTGGACAGGAAAACAGGTTGTGTCAACGCTGCTCATAAATATAATCCCAGAGGACCAC
ATCCCACTGAACTTATCTGGAAAGGCGAAAATCACTGGGAAAGCCTGGGTGAAGGAAACT
CCTCGATCCGTTCCTGGCTTTAACCCTGACTCGATGTGCGAGTCCCAGGTGATCATCAGG
GAAGGGGAGCTGCTCTGCGGAGTGCTGGACAAGGCGCACTATGGGAGCTCCGCCTACGGC
CTGGTCCACTGCTGCTATGAGATCTATGGAGGCGAGACCAGCGGCAAGGTTCTAACCTGC
CTGGCCCGCCTCTTCACCGCCTACCTGCAGCTCTACAGAGGCTTCACCTTGGGCGTGGAA
GACATTTTGGTGAAGCCAAAGGCAGATGTCAAGAGGCAACGTATCATTGAAGAATCCACC
CACTGCGGGCCCCAGGCTGTCAGGGCTGCATTAAACCTGCCAGAAGCCGCATCATATGAT
GAGGTCCGAGGAAAATGGCAGGATGCCCATCTGGGCAAGGACCAGAGGGATTTTAACATG
ATTGATCTGAAGTTCAAGGAGGAAGTGAACCATTACAGCAATGAGATTAACAAGGCATGC
ATGCCTTTTGGCCTACACAGACAGTTCCCAGAGAACAGCCTGCAGATGATGGTGCAGTCG
GGAGCCAAAGGTTCAACTGTGAACACGATGCAGATCTCGTGCCTGCTGGGCCAGATTGAA
CTGGAAGGTCGGAGACCCCCGCTGATGGCGTCTGGCAAGTCACTGCCCTGCTTTGAGCCT
TATGAGTTCACCCCCAGGGCTGGTGGCTTTGTCACTGGCAGGTTCCTTACCGGCATCAAA
CCTCCTGAGTTCTTCTTCCACTGCATGGCAGGACGAGAAGGCCTGGTGGACACTGCTGTG
AAAACCAGCCGCTCAGGCTATCTCCAAAGGTGCATCATCAAGCACCTAGAGGGGCTGGTC
GTGCAGTATGATCTCACGGTCCGTGACAGTGACGGCAGTGTGGTGCAGTTCCTGTATGGG
GAGGATGGCCTGGACATCCCCAAGACACAGTTCCTGCAGCCCAAGCAGTTCCCCTTCCTG
GCCAGCAACTACGAGGTGATAATGAAATCACAGCATCTCCATGAAGTTTTATCCAGAGCA
GATCCCAAAAAAGCTCTCCACCACTTCAGAGCTATCAAAAAATGGCAAAGCAAGCACCCC
AACACCCTGCTGAGAAGAGGCGCCTTCTTGAGTTATTCCCAGAAAATTCAGGAAGCTGTG
AAAGCCCTGAAACTTGAGAGTGAAAACCGCAATGGCCGCAGCCCTGGGACTCAGGAGATG
CTGAGGATGTGGTATGAGTTGGATGAGGAAAGCCGAAGGAAATACCAGAAGAAGGCGGCC
GCTTGTCCTGACCCCAGTCTGTCTGTCTGGCGTCCTGACATCTACTTTGCATCAGTGTCA
GAAACATTTGAAACAAAGGTTGATGACTACAGTCAAGAGTGGGCAGCTCAAACAGAGAAG
AGTTATGAGAAATCAGAGCTTTCTCTCGACAGGTTGAGGACCTTGCTGCAGCTGAAGTGG
CAGCGCTCACTGTGTGAGCCGGGCGAGGCTGTGGGCCTGCTGGCTGCCCAGAGCATCGGA
GAGCCCTCCACCCAGATGACCCTCAACACCTTCCACTTTGCAGGCAGAGGCGAGATGAAC
GTCACCCTGGGCATTCCAAGGTTGCGGGAGATTCTCATGGTGGCCAGCGCCAACATCAAG
ACACCCATGATGAGCGTGCCCGTGCTCAACACCAAGAAAGCCCTGAAGAGAGTGAAAAGC
CTGAAGAAGCAACTCACCAGGGTGTGCTTGGGGGAGGTGTTGCAGAAAATTGACGTCCAG
GAGTCCTTCTGTATGGAAGAAAAACAGAACAAATTCCAGGTGTACCAGCTGCGGTTTCAG
TTCCTGCCACATGCATATTACCAGCAGGAGAAGTGCCTGAGACCCGAGGACATCCTGCGC
TTCATGGAAACAAGATTCTTTAAACTTCTGATGGAATCCATCAAAAAGAAGAATAATAAA
GCATCAGCTTTCAGGAACGTAAACACTCGAAGAGCTACACAGCGGGATCTGGACAACGCT
GGGGAGTTGGGGAGGAGTCGGGGAGAGCAGGAGGGTGATGAGGAAGAGGAGGGGCACATT
GTGGATGCTGAAGCTGAGGAGGGAGACGCCGATGCCTCTGATGCCAAACGCAAGGAGAAG
CAGGAGGAGGAGGTTGATTATGAGAGTGAGGAAGAGGAGGAGAGGGAGGGCGAGGAGAAC
GACGATGAAGACATGCAGGAGGAACGAAATCCCCACAGGGAAGGTGCTCGAAAGACCCAA
GAGCAAGATGAAGAGGTGGGCTTAGGCACTGAGGAGGACCCGTCCCTTCCCGCCCTCCTG
ACGCAGCCCCGGAAACCCACCCACAGCCAGGAGCCCCAGGGGCCCGAGGCCATGGAGCGC
CGGGTCCAGGCTGTGCGTGAGATCCACCCGTTCATAGATGACTACCAGTACGACACCGAG
GAGAGCCTGTGGTGCCAGGTGACAGTGAAGCTCCCTCTGATGAAGATCAACTTTGACATG
AGCTCCCTGGTAGTATCTTTGGCCCATGGTGCCGTCATCTATGCGACCAAGGGCATCACT
CGGTGCCTCCTGAATGAAACAACCAACAATAAGAACGAGAAGGAGCTTGTGCTAAACACA
GAAGGAATCAACCTCCCAGAGCTATTCAAGTATGCAGAGGTCCTGGATCTGCGCCGCCTC
TACTCCAACGACATCCACGCCATAGCCAACACGTATGGCATTGAGGCCGCGCTGCGGGTG
ATCGAGAAGGAGATCAAGGATGTGTTTGCCGTGTATGGCATCGCGGTCGACCCTCGCCAT
CTCTCCCTGGTTGCTGATTATATGTGCTTCGAGGGTGTTTACAAGCCACTGAATCGCTTT
GGGATCCGGTCAAACTCTTCCCCGCTACAGCAGATGACATTTGAAACCAGCTTCCAGTTT
CTGAAGCAAGCCACCATGCTGGGATCCCACGATGAGCTGAGGTCTCCTTCTGCCTGCCTT
GTGGTCGGGAAGGTCGTCAGGGGCGGGACAGGCCTGTTCGAGCTCAAGCAGCCTCTGAGA
TAG
|
| Protein Properties |
|---|
| Number of Residues
| 1720 |
| Molecular Weight
| 194809.645 |
| Theoretical pI
| 7.036 |
| Pfam Domain Function
|
|
| Signals
|
Not Available
|
|
Transmembrane Regions
|
Not Available
|
| Protein Sequence
|
>DNA-directed RNA polymerase I subunit RPA1
MLISKNMPWRRLQGISFGMYSAEELKKLSVKSITNPRYLDSLGNPSANGLYDLALGPADS
KEVCSTCVQDFSNCSGHLGHIELPLTVYNPLLFDKLYLLLRGSCLNCHMLTCPRAVIHLL
LCQLRVLEVGALQAVYELERILNRFLEENPDPSASEIREELEQYTTEIVQNNLLGSQGAH
VKNVCESKSKLIALFWKAHMNAKRCPHCKTGRSVVRKEHNSKLTITFPAMVHRTAGQKDS
EPLGIEEAQIGKRGYLTPTSAREHLSALWKNEGFFLNYLFSGMDDDGMESRFNPSVFFLD
FLVVPPSRYRPVSRLGDQMFTNGQTVNLQAVMKDVVLIRKLLALMAQEQKLPEEVATPTT
DEEKDSLIAIDRSFLSTLPGQSLIDKLYNIWIRLQSHVNIVFDSEMDKLMMDKYPGIRQI
LEKKEGLFRKHMMGKRVDYAARSVICPDMYINTNEIGIPMVFATKLTYPQPVTPWNVQEL
RQAVINGPNVHPGASMVINEDGSRTALSAVDMTQREAVAKQLLTPATGAPKPQGTKIVCR
HVKNGDILLLNRQPTLHRPSIQAHRARILPEEKVLRLHYANCKAYNADFDGDEMNAHFPQ
SELGRAEAYVLACTDQQYLVPKDGQPLAGLIQDHMVSGASMTTRGCFFTREHYMELVYRG
LTDKVGRVKLLSPSILKPFPLWTGKQVVSTLLINIIPEDHIPLNLSGKAKITGKAWVKET
PRSVPGFNPDSMCESQVIIREGELLCGVLDKAHYGSSAYGLVHCCYEIYGGETSGKVLTC
LARLFTAYLQLYRGFTLGVEDILVKPKADVKRQRIIEESTHCGPQAVRAALNLPEAASYD
EVRGKWQDAHLGKDQRDFNMIDLKFKEEVNHYSNEINKACMPFGLHRQFPENSLQMMVQS
GAKGSTVNTMQISCLLGQIELEGRRPPLMASGKSLPCFEPYEFTPRAGGFVTGRFLTGIK
PPEFFFHCMAGREGLVDTAVKTSRSGYLQRCIIKHLEGLVVQYDLTVRDSDGSVVQFLYG
EDGLDIPKTQFLQPKQFPFLASNYEVIMKSQHLHEVLSRADPKKALHHFRAIKKWQSKHP
NTLLRRGAFLSYSQKIQEAVKALKLESENRNGRSPGTQEMLRMWYELDEESRRKYQKKAA
ACPDPSLSVWRPDIYFASVSETFETKVDDYSQEWAAQTEKSYEKSELSLDRLRTLLQLKW
QRSLCEPGEAVGLLAAQSIGEPSTQMTLNTFHFAGRGEMNVTLGIPRLREILMVASANIK
TPMMSVPVLNTKKALKRVKSLKKQLTRVCLGEVLQKIDVQESFCMEEKQNKFQVYQLRFQ
FLPHAYYQQEKCLRPEDILRFMETRFFKLLMESIKKKNNKASAFRNVNTRRATQRDLDNA
GELGRSRGEQEGDEEEEGHIVDAEAEEGDADASDAKRKEKQEEEVDYESEEEEEREGEEN
DDEDMQEERNPHREGARKTQEQDEEVGLGTEEDPSLPALLTQPRKPTHSQEPQGPEAMER
RVQAVREIHPFIDDYQYDTEESLWCQVTVKLPLMKINFDMSSLVVSLAHGAVIYATKGIT
RCLLNETTNNKNEKELVLNTEGINLPELFKYAEVLDLRRLYSNDIHAIANTYGIEAALRV
IEKEIKDVFAVYGIAVDPRHLSLVADYMCFEGVYKPLNRFGIRSNSSPLQQMTFETSFQF
LKQATMLGSHDELRSPSACLVVGKVVRGGTGLFELKQPLR
|
| External Links |
|---|
| GenBank ID Protein
| 221044078 |
| UniProtKB/Swiss-Prot ID
| O95602 |
| UniProtKB/Swiss-Prot Entry Name
| RPA1_HUMAN |
| PDB IDs
|
Not Available |
| GenBank Gene ID
| AK302458 |
| GeneCard ID
| POLR1A |
| GenAtlas ID
| POLR1A |
| HGNC ID
| HGNC:17264 |
| References |
|---|
| General References
| Not Available |