| Identification |
|---|
| HMDB Protein ID
| CDBP04282 |
| Secondary Accession Numbers
| Not Available |
| Name
| Sodium channel protein type 10 subunit alpha |
| Description
| Not Available |
| Synonyms
|
- PN3
- Peripheral nerve sodium channel 3
- Sodium channel protein type X subunit alpha
- Voltage-gated sodium channel subunit alpha Nav1.8
- hPN3
|
| Gene Name
| SCN10A |
| Protein Type
| Transporter |
| Biological Properties |
|---|
| General Function
| Involved in ion channel activity |
| Specific Function
| This protein mediates the voltage-dependent sodium ion permeability of excitable membranes. Assuming opened or closed conformations in response to the voltage difference across the membrane, the protein forms a sodium-selective channel through which sodium ions may pass in accordance with their electrochemical gradient. It is a tetrodotoxin-resistant sodium channel isoform. Its electrophysiological properties vary depending on the type of the associated beta subunits (in vitro). Plays a role in neuropathic pain mechanisms |
| GO Classification
|
| Component |
| macromolecular complex |
| protein complex |
| sodium channel complex |
| voltage-gated sodium channel complex |
| membrane |
| cell part |
| ion channel complex |
| cation channel complex |
| Function |
| transmembrane transporter activity |
| substrate-specific transmembrane transporter activity |
| ion transmembrane transporter activity |
| sodium channel activity |
| transporter activity |
| ion channel activity |
| voltage-gated sodium channel activity |
| cation channel activity |
| Process |
| monovalent inorganic cation transport |
| ion transport |
| cation transport |
| sodium ion transport |
| establishment of localization |
| transport |
| transmembrane transport |
|
| Cellular Location
|
- Membrane
- Multi-pass membrane protein
|
| Pathways
|
| Name | SMPDB/Pathwhiz | KEGG | | Benzocaine Action Pathway | 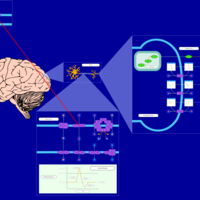 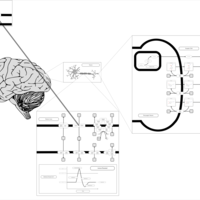  | Not Available | | Bupivacaine Action Pathway | 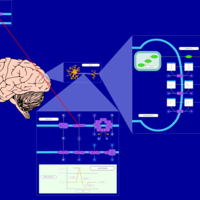   | Not Available | | Chloroprocaine Action Pathway |    | Not Available | | Cocaine Action Pathway |    | Not Available | | Dibucaine Action Pathway |    | Not Available |
|
| Gene Properties |
|---|
| Chromosome Location
| Chromosome:3 |
| Locus
| 3p22.2 |
| SNPs
| SCN10A |
| Gene Sequence
|
>5871 bp
ATGGAATTCCCCATTGGATCCCTCGAAACTAACAACTTCCGTCGCTTTACTCCGGAGTCA
CTGGTGGAGATAGAGAAGCAAATTGCTGCCAAGCAGGGAACAAAGAAAGCCAGAGAGAAG
CATAGGGAGCAGAAGGACCAAGAAGAGAAGCCTCGGCCCCAGCTGGACTTGAAAGCCTGC
AACCAGCTGCCCAAGTTCTATGGTGAGCTCCCAGCAGAACTGATCGGGGAGCCCCTGGAG
GATCTAGATCCGTTCTACAGCACACACCGGACATTTATGGTGCTGAACAAAGGGAGGACC
ATTTCCCGGTTTAGTGCCACTCGGGCCCTGTGGCTATTCAGTCCTTTCAACCTGATCAGA
AGAACGGCCATCAAAGTGTCTGTCCACTCGTGGTTCAGTTTATTTATTACGGTCACTATT
TTGGTTAATTGTGTGTGCATGACCCGAACTGACCTTCCAGAGAAAATTGAATATGTCTTC
ACTGTCATTTACACCTTTGAAGCCTTGATAAAGATACTGGCAAGAGGATTTTGTCTAAAT
GAGTTCACGTACCTGAGAGATCCTTGGAACTGGCTGGATTTTAGCGTCATTACCCTGGCA
TATGTTGGCACAGCAATAGATCTCCGTGGGATCTCAGGCCTGCGGACATTCAGAGTTCTT
AGAGCATTAAAAACAGTTTCTGTGATCCCAGGCCTGAAGGTCATTGTGGGGGCCCTGATT
CACTCAGTGAAGAAACTGGCTGATGTGACCATCCTCACCATCTTCTGCCTAAGTGTTTTT
GCCTTGGTGGGGCTGCAACTCTTCAAGGGCAACCTCAAAAATAAATGTGTCAAGAATGAC
ATGGCTGTCAATGAGACAACCAACTACTCATCTCACAGAAAACCAGATATCTACATAAAT
AAGCGAGGCACTTCTGACCCCTTACTGTGTGGCAATGGATCTGACTCAGGCCACTGCCCT
GATGGTTATATCTGCCTTAAAACTTCTGACAACCCGGATTTTAACTACACCAGCTTTGAT
TCCTTTGCTTGGGCTTTCCTCTCACTGTTCCGCCTCATGACACAGGATTCCTGGGAACGC
CTCTACCAGCAGACCCTGAGGACTTCTGGGAAAATCTATATGATCTTTTTTGTGCTCGTA
ATCTTCCTGGGATCTTTCTACCTGGTCAACTTGATCTTGGCTGTAGTCACCATGGCGTAT
GAGGAGCAGAACCAGGCAACCACTGATGAAATTGAAGCAAAGGAGAAGAAGTTCCAGGAG
GCCCTCGAGATGCTCCGGAAGGAGCAGGAGGTGCTAGCAGCACTAGGGATTGACACAACC
TCTCTCCACTCCCACAATGGATCACCTTTAACCTCCAAAAATGCCAGTGAGAGAAGGCAT
AGAATAAAGCCAAGAGTGTCAGAGGGCTCCACAGAAGACAACAAATCACCCCGCTCTGAT
CCTTACAACCAGCGCAGGATGTCTTTTCTAGGCCTCGCCTCTGGAAAACGCCGGGCTAGT
CATGGCAGTGTGTTCCATTTCCGGTCCCCTGGCCGAGATATCTCACTCCCTGAGGGAGTC
ACAGATGATGGAGTCTTTCCTGGAGACCACGAAAGCCATCGGGGCTCTCTGCTGCTGGGT
GGGGGTGCTGGCCAGCAAGGCCCCCTCCCTAGAAGCCCTCTTCCTCAACCCAGCAACCCT
GACTCCAGGCATGGAGAAGATGAACACCAACCGCCGCCCACTAGTGAGCTTGCCCCTGGA
GCTGTCGATGTCTCGGCATTCGATGCAGGACAAAAGAAGACTTTCTTGTCAGCAGAATAC
TTAGATGAACCTTTCCGGGCCCAAAGGGCAATGAGTGTTGTCAGTATCATAACCTCCGTC
CTTGAGGAACTCGAGGAGTCTGAACAGAAGTGCCCACCCTGCTTGACCAGCTTGTCTCAG
AAGTATCTGATCTGGGATTGCTGCCCCATGTGGGTGAAGCTCAAGACAATTCTCTTTGGG
CTTGTGACGGATCCCTTTGCAGAGCTCACCATCACCTTGTGCATCGTGGTGAACACCATC
TTCATGGCCATGGAGCACCATGGCATGAGCCCTACCTTCGAAGCCATGCTCCAGATAGGC
AACATCGTCTTTACCATATTTTTTACTGCTGAAATGGTCTTCAAAATCATTGCCTTCGAC
CCATACTATTATTTCCAGAAGAAGTGGAATATCTTTGACTGCATCATCGTCACTGTGAGT
CTGCTAGAGCTGGGCGTGGCCAAGAAGGGAAGCCTGTCTGTGCTGCGGAGCTTCCGCTTG
CTGCGCGTATTCAAGCTGGCCAAATCCTGGCCCACCTTAAACACACTCATCAAGATCATC
GGAAACTCAGTGGGGGCACTGGGGAACCTCACCATCATCCTGGCCATCATTGTCTTTGTC
TTTGCTCTGGTTGGCAAGCAGCTCCTAGGGGAAAACTACCGTAACAACCGAAAAAATATC
TCCGCGCCCCATGAAGACTGGCCCCGCTGGCACATGCACGACTTCTTCCACTCTTTCCTC
ATTGTCTTCCGTATCCTCTGTGGAGAGTGGATTGAGAACATGTGGGCCTGCATGGAAGTT
GGCCAAAAATCCATATGCCTCATCCTTTTCTTGACGGTGATGGTGCTAGGGAACCTGGTG
GTGCTTAACCTGTTCATCGCCCTGCTATTGAACTCTTTCAGTGCTGACAACCTCACAGCC
CCGGAGGACGATGGGGAGGTGAACAACCTGCAGGTGGCCCTGGCACGGATCCAGGTCTTT
GGCCATCGTACCAAACAGGCTCTTTGCAGCTTCTTCAGCAGGTCCTGCCCATTCCCCCAG
CCCAAGGCAGAGCCTGAGCTGGTGGTGAAACTCCCACTCTCCAGCTCCAAGGCTGAGAAC
CACATTGCTGCCAACACTGCCAGGGGGAGCTCTGGAGGGCTCCAAGCTCCCAGAGGCCCC
AGGGATGAGCACAGTGACTTCATCGCTAATCCGACTGTGTGGGTCTCTGTGCCCATTGCT
GAGGGTGAATCTGATCTTGATGACTTGGAGGATGATGGTGGGGAAGATGCTCAGAGCTTC
CAGCAGGAAGTGATCCCCAAAGGACAGCAGGAGCAGCTGCAGCAAGTCGAGAGGTGTGGG
GACCACCTGACACCCAGGAGCCCAGGCACTGGAACATCTTCTGAGGACCTGGCTCCATCC
CTGGGTGAGACGTGGAAAGATGAGTCTGTTCCTCAGGCCCCTGCTGAGGGAGTGGACGAC
ACAAGCTCCTCTGAGGGCAGCACGGTGGACTGCCTAGATCCTGAGGAAATCCTGAGGAAG
ATCCCTGAGCTGGCAGATGACCTGGAAGAACCAGATGACTGCTTCACAGAAGGATGCATT
CGCCACTGTCCCTGCTGCAAACTGGATACCACCAAGAGTCCATGGGATGTGGGCTGGCAG
GTGCGCAAGACTTGCTACCGTATCGTGGAGCACAGCTGGTTTGAGAGCTTCATCATCTTC
ATGATCCTGCTCAGCAGTGGATCTCTGGCCTTTGAAGACTATTACCTGGACCAGAAGCCC
ACGGTGAAAGCTTTGCTGGAGTACACTGACAGGGTCTTCACCTTTATCTTTGTGTTCGAG
ATGCTGCTTAAGTGGGTGGCCTATGGCTTCAAAAAGTACTTCACCAATGCCTGGTGCTGG
CTGGACTTCCTCATTGTGAATATCTCACTGATAAGTCTCACAGCGAAGATTCTGGAATAT
TCTGAAGTGGCTCCCATCAAAGCCCTTCGAACCCTTCGCGCTCTGCGGCCACTGCGGGCT
CTTTCTCGATTTGAAGGCATGCGGGTGGTGGTGGATGCCCTGGTGGGCGCCATCCCATCC
ATCATGAATGTCCTCCTCGTCTGCCTCATCTTCTGGCTCATCTTCAGCATCATGGGTGTG
AACCTCTTCGCAGGGAAGTTTTGGAGGTGCATCAACTATACCGATGGAGAGTTTTCCCTT
GTACCTTTGTCGATTGTGAATAACAAGTCTGACTGCAAGATTCAAAACTCCACTGGCAGC
TTCTTCTGGGTCAATGTGAAAGTCAACTTTGATAATGTTGCAATGGGTTACCTTGCACTT
CTGCAGGTGGCAACCTTTAAAGGCTGGATGGACATTATGTATGCAGCTGTTGATTCCCGG
GAGGTCAACATGCAACCCAAGTGGGAGGACAACGTGTACATGTATTTGTACTTTGTCATC
TTCATCATTTTTGGAGGCTTCTTCACACTGAATCTCTTTGTTGGGGTCATAATTGACAAC
TTCAATCAACAGAAAAAAAAGTTAGGGGGCCAGGACATCTTCATGACAGAGGAGCAGAAG
AAATACTACAATGCCATGAAGAAGTTGGGCTCCAAGAAGCCCCAGAAGCCCATCCCACGG
CCCCTGAACAAGTTCCAGGGTTTTGTCTTTGACATCGTGACCAGACAAGCTTTTGACATC
ACCATCATGGTCCTCATCTGCCTCAACATGATCACCATGATGGTGGAGACTGATGACCAA
AGTGAAGAAAAGACGAAAATTCTGGGCAAAATCAACCAGTTCTTTGTGGCCGTCTTCACA
GGCGAATGTGTCATGAAGATGTTCGCTTTGAGGCAGTACTACTTCACAAATGGCTGGAAT
GTGTTTGACTTCATTGTGGTGGTTCTCTCCATTGCGAGCCTGATTTTTTCTGCAATTCTT
AAGTCACTTCAAAGTTACTTCTCCCCAACGCTCTTCAGAGTCATCCGCCTGGCCCGAATT
GGCCGCATCCTCAGACTGATCCGAGCGGCCAAGGGGATCCGCACACTGCTCTTTGCCCTC
ATGATGTCCCTGCCTGCCCTCTTCAACATCGGGCTGTTGCTATTCCTTGTCATGTTCATC
TACTCCATCTTCGGTATGTCCAGCTTTCCCCATGTGAGGTGGGAGGCTGGCATCGACGAC
ATGTTCAACTTCCAGACCTTCGCCAACAGCATGCTGTGCCTCTTCCAGATTACCACGTCG
GCCGGCTGGGATGGCCTCCTCAGCCCCATCCTCAACACAGGGCCCCCCTACTGTGACCCC
AATCTGCCCAACAGCAATGGCACCAGAGGGGACTGTGGGAGCCCAGCCGTAGGCATCATC
TTCTTCACCACCTACATCATCATCTCCTTCCTCATCGTGGTCAACATGTACATTGCAGTG
ATTCTGGAGAACTTCAATGTGGCCACGGAGGAGAGCACTGAGCCTCTGAGTGAGGACGAC
TTTGACATGTTCTATGAGACCTGGGAGAAGTTTGACCCAGAGGCCACTCAGTTTATTACC
TTTTCTGCTCTCTCGGACTTTGCAGACACTCTCTCTGGTCCCCTGAGAATCCCAAAACCC
AATCGAAATATACTGATCCAGATGGACCTGCCTTTGGTCCCTGGAGATAAGATCCACTGC
TTGGACATCCTTTTTGCTTTCACCAAGAATGTCCTAGGAGAATCCGGGGAGTTGGATTCT
CTGAAGGCAAATATGGAGGAGAAGTTTATGGCAACTAATCTTTCAAAATCATCCTATGAA
CCAATAGCAACCACTCTCCGATGGAAGCAAGAAGACATTTCAGCCACTGTCATTCAAAAG
GCCTATCGGAGCTATGTGCTGCACCGCTCCATGGCACTCTCTAACACCCCATGTGTGCCC
AGAGCTGAGGAGGAGGCTGCATCACTCCCAGATGAAGGTTTTGTTGCATTCACAGCAAAT
GAAAATTGTGTACTCCCAGACAAATCTGAAACTGCTTCTGCCACATCATTCCCACCGTCC
TATGAGAGTGTCACTAGAGGCCTTAGTGATAGAGTCAACATGAGGACATCTAGCTCAATA
CAAAATGAAGATGAAGCCACCAGTATGGAGCTGATTGCCCCTGGGCCCTAG
|
| Protein Properties |
|---|
| Number of Residues
| 1956 |
| Molecular Weight
| 220623.6 |
| Theoretical pI
| 5.77 |
| Pfam Domain Function
|
|
| Signals
|
|
|
Transmembrane Regions
|
- ["126-149", "155-174", "188-206", "213-232", "249-272", "374-399", "660-684", "696-719", "728-747", "754-773", "790-810", "865-890", "1148-1171", "1185-1210", "1217-1238", "1243-1264", "1284-1311", "1392-1418", "1472-1495", "1507-1530", "1537-1560", "1573-1594", "1610-1632", "1698-1722"]
|
| Protein Sequence
|
>Sodium channel protein type 10 subunit alpha
MEFPIGSLETNNFRRFTPESLVEIEKQIAAKQGTKKAREKHREQKDQEEKPRPQLDLKAC
NQLPKFYGELPAELIGEPLEDLDPFYSTHRTFMVLNKGRTISRFSATRALWLFSPFNLIR
RTAIKVSVHSWFSLFITVTILVNCVCMTRTDLPEKIEYVFTVIYTFEALIKILARGFCLN
EFTYLRDPWNWLDFSVITLAYVGTAIDLRGISGLRTFRVLRALKTVSVIPGLKVIVGALI
HSVKKLADVTILTIFCLSVFALVGLQLFKGNLKNKCVKNDMAVNETTNYSSHRKPDIYIN
KRGTSDPLLCGNGSDSGHCPDGYICLKTSDNPDFNYTSFDSFAWAFLSLFRLMTQDSWER
LYQQTLRTSGKIYMIFFVLVIFLGSFYLVNLILAVVTMAYEEQNQATTDEIEAKEKKFQE
ALEMLRKEQEVLAALGIDTTSLHSHNGSPLTSKNASERRHRIKPRVSEGSTEDNKSPRSD
PYNQRRMSFLGLASGKRRASHGSVFHFRSPGRDISLPEGVTDDGVFPGDHESHRGSLLLG
GGAGQQGPLPRSPLPQPSNPDSRHGEDEHQPPPTSELAPGAVDVSAFDAGQKKTFLSAEY
LDEPFRAQRAMSVVSIITSVLEELEESEQKCPPCLTSLSQKYLIWDCCPMWVKLKTILFG
LVTDPFAELTITLCIVVNTIFMAMEHHGMSPTFEAMLQIGNIVFTIFFTAEMVFKIIAFD
PYYYFQKKWNIFDCIIVTVSLLELGVAKKGSLSVLRSFRLLRVFKLAKSWPTLNTLIKII
GNSVGALGNLTIILAIIVFVFALVGKQLLGENYRNNRKNISAPHEDWPRWHMHDFFHSFL
IVFRILCGEWIENMWACMEVGQKSICLILFLTVMVLGNLVVLNLFIALLLNSFSADNLTA
PEDDGEVNNLQVALARIQVFGHRTKQALCSFFSRSCPFPQPKAEPELVVKLPLSSSKAEN
HIAANTARGSSGGLQAPRGPRDEHSDFIANPTVWVSVPIAEGESDLDDLEDDGGEDAQSF
QQEVIPKGQQEQLQQVERCGDHLTPRSPGTGTSSEDLAPSLGETWKDESVPQVPAEGVDD
TSSSEGSTVDCLDPEEILRKIPELADDLEEPDDCFTEGCIRHCPCCKLDTTKSPWDVGWQ
VRKTCYRIVEHSWFESFIIFMILLSSGSLAFEDYYLDQKPTVKALLEYTDRVFTFIFVFE
MLLKWVAYGFKKYFTNAWCWLDFLIVNISLISLTAKILEYSEVAPIKALRTLRALRPLRA
LSRFEGMRVVVDALVGAIPSIMNVLLVCLIFWLIFSIMGVNLFAGKFWRCINYTDGEFSL
VPLSIVNNKSDCKIQNSTGSFFWVNVKVNFDNVAMGYLALLQVATFKGWMDIMYAAVDSR
EVNMQPKWEDNVYMYLYFVIFIIFGGFFTLNLFVGVIIDNFNQQKKKLGGQDIFMTEEQK
KYYNAMKKLGSKKPQKPIPRPLNKFQGFVFDIVTRQAFDITIMVLICLNMITMMVETDDQ
SEEKTKILGKINQFFVAVFTGECVMKMFALRQYYFTNGWNVFDFIVVVLSIASLIFSAIL
KSLQSYFSPTLFRVIRLARIGRILRLIRAAKGIRTLLFALMMSLPALFNIGLLLFLVMFI
YSIFGMSSFPHVRWEAGIDDMFNFQTFANSMLCLFQITTSAGWDGLLSPILNTGPPYCDP
NLPNSNGTRGDCGSPAVGIIFFTTYIIISFLIMVNMYIAVILENFNVATEESTEPLSEDD
FDMFYETWEKFDPEATQFITFSALSDFADTLSGPLRIPKPNRNILIQMDLPLVPGDKIHC
LDILFAFTKNVLGESGELDSLKANMEEKFMATNLSKSSYEPIATTLRWKQEDISATVIQK
AYRSYVLHRSMALSNTPCVPRAEEEAASLPDEGFVAFTANENCVLPDKSETASATSFPPS
YESVTRGLSDRVNMRTSSSIQNEDEATSMELIAPGP
|
| External Links |
|---|
| GenBank ID Protein
| 4838145 |
| UniProtKB/Swiss-Prot ID
| Q9Y5Y9 |
| UniProtKB/Swiss-Prot Entry Name
| SCNAA_HUMAN |
| PDB IDs
|
Not Available |
| GenBank Gene ID
| AF117907 |
| GeneCard ID
| SCN10A |
| GenAtlas ID
| SCN10A |
| HGNC ID
| HGNC:10582 |
| References |
|---|
| General References
| Not Available |