| Identification |
|---|
| HMDB Protein ID
| CDBP04278 |
| Secondary Accession Numbers
| Not Available |
| Name
| Sodium channel protein type 5 subunit alpha |
| Description
| Not Available |
| Synonyms
|
- HH1
- Sodium channel protein cardiac muscle subunit alpha
- Sodium channel protein type V subunit alpha
- Voltage-gated sodium channel subunit alpha Nav1.5
|
| Gene Name
| SCN5A |
| Protein Type
| Transporter |
| Biological Properties |
|---|
| General Function
| Involved in ion channel activity |
| Specific Function
| This protein mediates the voltage-dependent sodium ion permeability of excitable membranes. Assuming opened or closed conformations in response to the voltage difference across the membrane, the protein forms a sodium-selective channel through which Na(+) ions may pass in accordance with their electrochemical gradient. It is a tetrodotoxin-resistant Na(+) channel isoform. This channel is responsible for the initial upstroke of the action potential in the electrocardiogram |
| GO Classification
|
| Component |
| cation channel complex |
| macromolecular complex |
| protein complex |
| sodium channel complex |
| voltage-gated sodium channel complex |
| membrane |
| cell part |
| ion channel complex |
| Function |
| transmembrane transporter activity |
| substrate-specific transmembrane transporter activity |
| ion transmembrane transporter activity |
| sodium channel activity |
| transporter activity |
| ion channel activity |
| voltage-gated sodium channel activity |
| cation channel activity |
| Process |
| transmembrane transport |
| monovalent inorganic cation transport |
| ion transport |
| cation transport |
| sodium ion transport |
| establishment of localization |
| transport |
|
| Cellular Location
|
- Membrane
- Multi-pass membrane protein
|
| Pathways
|
| Name | SMPDB/Pathwhiz | KEGG | | Muscle/Heart Contraction | 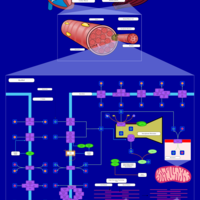 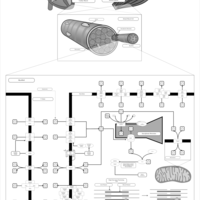  | Not Available | | Acebutolol Action Pathway | 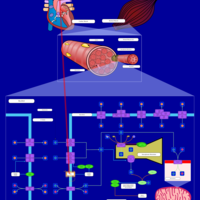 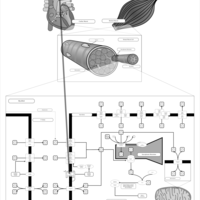  | Not Available | | Alprenolol Action Pathway | 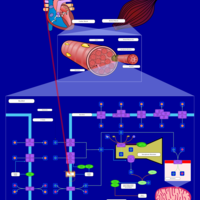 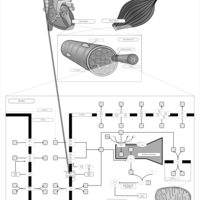  | Not Available | | Atenolol Action Pathway | 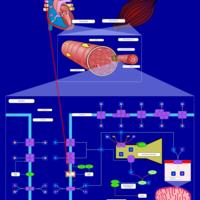   | Not Available | | Betaxolol Action Pathway | 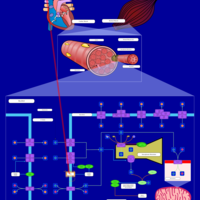   | Not Available |
|
| Gene Properties |
|---|
| Chromosome Location
| Chromosome:3 |
| Locus
| 3p21 |
| SNPs
| SCN5A |
| Gene Sequence
|
>6051 bp
ATGGCAAACTTCCTATTACCTCGGGGCACCAGCAGCTTCCGCAGGTTCACACGGGAGTCC
CTGGCAGCCATCGAGAAGCGCATGGCAGAGAAGCAAGCCCGCGGCTCAACCACCTTGCAG
GAGAGCCGAGAGGGGCTGCCCGAGGAGGAGGCTCCCCGGCCCCAGCTGGACCTGCAGGCC
TCCAAAAAGCTGCCAGATCTCTATGGCAATCCACCCCAAGAGCTCATCGGAGAGCCCCTG
GAGGACCTGGACCCCTTCTATAGCACCCAAAAGACTTTCATCGTACTGAATAAAGGCAAG
ACCATCTTCCGGTTCAGTGCCACCAACGCCTTGTATGTCCTCAGTCCCTTCCACCCCATC
CGGAGAGCGGCTGTGAAGATTCTGGTTCACTCGCTCTTCAACATGCTCATCATGTGCACC
ATCCTCACCAACTGCGTGTTCATGGCCCAGCACGACCCTCCACCCTGGACCAAGTATGTC
GAGTACACCTTCACCGCCATTTACACCTTTGAGTCTCTGGTCAAGATTCTGGCTCGAGGC
TTCTGCCTGCACGCGTTCACTTTCCTTCGGGGCCCATGGAACTGGCTGGACTTTAGTGTG
ATTATCATGGCGTATGTATCAGAAAATATAAAACTAGGCAATTTGTCGGCTCTTCGAACT
TTCAGAGTCCTGAGAGCTCTAAAAACTATTTCAGTTATCCCAGGGCTGAAGACCATCGTG
GGGGCCCTGATCCAGTCTGTGAAGAAGCTGGCTGATGTGATGGTCCTCACAGTCTTCTGC
CTCAGCGTCTTTGCCCTCATCGGCCTGCAGCTCTTCATGGGCAACCTAAGGCACAAGTGC
GTGCGCAACTTCACAGCGCTCAACGGCACCAACGGCTCCGTGGAGGCCGACGGCTTGGTC
TGGGAATCCCTGGACCTTTACCTCAGTGATCCAGAAAATTACCTGCTCAAGAACGGCACC
TCTGATGTGTTACTGTGTGGGAACAGCTCTGACGCTGGGACATGTCCGGAGGGCTACCGG
TGCCTAAAGGCAGGCGAGAACCCCGACCACGGCTACACCAGCTTCGATTCCTTTGCCTGG
GCCTTTCTTGCACTCTTCCGCCTGATGACGCAGGACTGCTGGGAGCGCCTCTATCAGCAG
ACCCTCAGGTCCGCAGGGAAGATCTACATGATCTTCTTCATGCTTGTCATCTTCCTGGGG
TCCTTCTACCTGGTGAACCTGATCCTGGCCGTGGTCGCAATGGCCTATGAGGAGCAAAAC
CAAGCCACCATCGCTGAGACCGAGGAGAAGGAAAAGCGCTTCCAGGAGGCCATGGAAATG
CTCAAGAAAGAACACGAGGCCCTCACCATCAGGGGTGTGGATACCGTGTCCCGTAGCTCC
TTGGAGATGTCCCCTTTGGCCCCAGTAAACAGCCATGAGAGAAGAAGCAAGAGGAGAAAA
CGGATGTCTTCAGGAACTGAGGAGTGTGGGGAGGACAGGCTCCCCAAGTCTGACTCAGAA
GATGGTCCCAGAGCAATGAATCATCTCAGCCTCACCCGTGGCCTCAGCAGGACTTCTATG
AAGCCACGTTCCAGCCGCGGGAGCATTTTCACCTTTCGCAGGCGAGACCTGGGTTCTGAA
GCAGATTTTGCAGATGATGAAAACAGCACAGCGGGGGAGAGCGAGAGCCACCACACATCA
CTGCTGGTGCCCTGGCCCCTGCGCCGGACCAGTGCCCAGGGACAGCCCAGTCCCGGAACC
TCGGCTCCTGGCCACGCCCTCCATGGCAAAAAGAACAGCACTGTGGACTGCAATGGGGTG
GTCTCATTACTGGGGGCAGGCGACCCAGAGGCCACATCCCCAGGAAGCCACCTCCTCCGC
CCTGTGATGCTAGAGCACCCGCCAGACACGACCACGCCATCGGAGGAGCCAGGCGGCCCC
CAGATGCTGACCTCCCAGGCTCCGTGTGTAGATGGCGTCGAGGAGCCAGGAGCACGGCAG
CGGGCCCTCAGCGCAGTCAGCGTCCTCACCAGCGCACTGGAAGAGTTAGAGGAGTCTCGC
CACAAGTGTCCACCATGCTGGAACCGTCTCGCCCAGCGCTACCTGATCTGGGAGTGCTGC
CCGCTGTGGATGTCCATCAAGCAGGGAGTGAAGTTGGTGGTCATGGACCCGTTTACTGAC
CTCACCATCACTATGTGCATCGTACTCAACACACTCTTCATGGCGCTGGAGCACTACAAC
ATGACAAGTGAATTCGAGGAGATGCTGCAGGTCGGAAACCTGGTCTTCACAGGGATTTTC
ACAGCAGAGATGACCTTCAAGATCATTGCCCTCGACCCCTACTACTACTTCCAACAGGGC
TGGAACATCTTCGACAGCATCATCGTCATCCTTAGCCTCATGGAGCTGGGCCTGTCCCGC
ATGAGCAACTTGTCGGTGCTGCGCTCCTTCCGCCTGCTGCGGGTCTTCAAGCTGGCCAAA
TCATGGCCCACCCTGAACACACTCATCAAGATCATCGGGAACTCAGTGGGGGCACTGGGG
AACCTGACACTGGTGCTAGCCATCATCGTGTTCATCTTTGCTGTGGTGGGCATGCAGCTC
TTTGGCAAGAACTACTCGGAGCTGAGGGACAGCGACTCAGGCCTGCTGCCTCGCTGGCAC
ATGATGGACTTCTTTCATGCCTTCCTCATCATCTTCCGCATCCTCTGTGGAGAGTGGATC
GAGACCATGTGGGACTGCATGGAGGTGTCGGGGCAGTCATTATGCCTGCTGGTCTTCTTG
CTTGTTATGGTCATTGGCAACCTTGTGGTCCTGAATCTCTTCCTGGCCTTGCTGCTCAGC
TCCTTCAGTGCAGACAACCTCACAGCCCCTGATGAGGACAGAGAGATGAACAACCTCCAG
CTGGCCCTGGCCCGCATCCAGAGGGGCCTGCGCTTTGTCAAGCGGACCACCTGGGATTTC
TGCTGTGGTCTCCTGCGGCACCGGCCTCAGAAGCCCGCAGCCCTTGCCGCCCAGGGCCAG
CTGCCCAGCTGCATTGCCACCCCCTACTCCCCGCCACCCCCAGAGACGGAGAAGGTGCCT
CCCACCCGCAAGGAAACACGGTTTGAGGAAGGCGAGCAACCAGGCCAGGGCACCCCCGGG
GATCCAGAGCCCGTGTGTGTGCCCATCGCTGTGGCCGAGTCAGACACAGATGACCAAGAA
GAGGATGAGGAGAACAGCCTGGGCACGGAGGAGGAGTCCAGCAAGCAGCAGGAATCCCAG
CCTGTGTCCGGCTGGCCCAGAGGCCCTCCGGATTCCAGGACCTGGAGCCAGGTGTCAGCG
ACTGCCTCCTCTGAGGCCGAGGCCAGTGCATCTCAGGCCGACTGGCGGCAGCAGTGGAAA
GCGGAACCCCAGGCCCCAGGGTGCGGTGAGACCCCAGAGGACAGTTGCTCCGAGGGCAGC
ACAGCAGACATGACCAACACCGCTGAGCTCCTGGAGCAGATCCCTGACCTCGGCCAGGAT
GTCAAGGACCCAGAGGACTGCTTCACTGAAGGCTGTGTCCGGCGCTGTCCCTGCTGTGCG
GTGGACACCACACAGGCCCCAGGGAAGGTCTGGTGGCGGTTGCGCAAGACCTGCTACCAC
ATCGTGGAGCACAGCTGGTTCGAGACATTCATCATCTTCATGATCCTACTCAGCAGTGGA
GCGCTGGCCTTCGAGGACATCTACCTAGAGGAGCGGAAGACCATCAAGGTTCTGCTTGAG
TATGCCGACAAGATGTTCACATATGTCTTCGTGCTGGAGATGCTGCTCAAGTGGGTGGCC
TACGGCTTCAAGAAGTACTTCACCAATGCCTGGTGCTGGCTCGACTTCCTCATCGTAGAC
GTCTCTCTGGTCAGCCTGGTGGCCAACACCCTGGGCTTTGCCGAGATGGGCCCCATCAAG
TCACTGCGGACGCTGCGTGCACTCCGTCCTCTGAGAGCTCTGTCACGATTTGAGGGCATG
AGGGTGGTGGTCAATGCCCTGGTGGGCGCCATCCCGTCCATCATGAACGTCCTCCTCGTC
TGCCTCATCTTCTGGCTCATCTTCAGCATCATGGGCGTGAACCTCTTTGCGGGGAAGTTT
GGGAGGTGCATCAACCAGACAGAGGGAGACTTGCCTTTGAACTACACCATCGTGAACAAC
AAGAGCCAGTGTGAGTCCTTGAACTTGACCGGAGAATTGTACTGGACCAAGGTGAAAGTC
AACTTTGACAACGTGGGGGCCGGGTACCTGGCCCTTCTGCAGGTGGCAACATTTAAAGGC
TGGATGGACATTATGTATGCAGCTGTGGACTCCAGGGGGTATGAAGAGCAGCCTCAGTGG
GAATACAACCTCTACATGTACATCTATTTTGTCATTTTCATCATCTTTGGGTCTTTCTTC
ACCCTGAACCTCTTTATTGGTGTCATCATTGACAACTTCAACCAACAGAAGAAAACGTTA
GGGGGCCAGGACATCTTCATGACAGAGGAGCAGAAGAAGTACTACAATGCCACGAAGAAG
CTGGGCTCCAAGAAGCCCCAGAAGCCCATCCCACGGCCCCTGAACAAGTACCAGGGCTTC
ATATTCGACATTGTGACCAAGCAGGCCTTTGACGTCACCATCATGTTTCTGATCTGCTTG
AATATGGTGACCATGATGGTGGAGACAGATGACCAAAGTCCTGAGAAAATCAACATCTTG
GCCAAGATCAACCTGCTCTTTGTGGCCATCTTCACAGGCGAGTGTATTGTCAAGCTGGCT
GCCCTGCGCCACTACTACTTCACCAACAGCTGGAATATCTTCGACTTCGTGGTTGTCATC
CTCTCCATCGTGGGCACTGTGCTCTCGGACATCATCCAGAAGTACTTCTTCTCCCCGACG
CTCTTCCGAGTCATCCGCCTGGCCCGAATAGGCCGCATCCTCAGACTGATCCGAGGGGCC
AAGGGGATCCGCACGCTGCTCTTTGCCCTCATGATGTCCCTGCCTGCCCTCTTCAACATC
GGGCTGCTGCTCTTCCTCGTCATGTTCATCTACTCCATCTTTGGCATGGCCAACTTCGCT
TATGTCAAGTGGGAGGCTGGCATCGACGACATGTTCAACTTCCAGACCTTCGCCAACAGC
ATGCTGTGCCTCTTCCAGATCACCACGTCGGCCGGCTGGGATGGCCTCCTCAGCCCCATC
CTCAACACTGGGCCGCCCTACTGCGACCCCACTCTGCCCAACAGCAATGGCTCTCGGGGG
GACTGCGGGAGCCCAGCCGTGGGCATCCTCTTCTTCACCACCTACATCATCATCTCCTTC
CTCATCGTGGTCAACATGTACATTGCCATCATCCTGGAGAACTTCAGCGTGGCCACGGAG
GAGAGCACCGAGCCCCTGAGTGAGGACGACTTCGATATGTTCTATGAGATCTGGGAGAAA
TTTGACCCAGAGGCCACTCAGTTTATTGAGTATTCGGTCCTGTCTGACTTTGCCGACGCC
CTGTCTGAGCCACTCCGTATCGCCAAGCCCAACCAGATAAGCCTCATCAACATGGACCTG
CCCATGGTGAGTGGGGACCGCATCCATTGCATGGACATTCTCTTTGCCTTCACCAAAAGG
GTCCTGGGGGAGTCTGGGGAGATGGACGCCCTGAAGATCCAGATGGAGGAGAAGTTCATG
GCAGCCAACCCATCCAAGATCTCCTACGAGCCCATCACCACCACACTCCGGCGCAAGCAC
GAAGAGGTGTCGGCCATGGTTATCCAGAGAGCCTTCCGCAGGCACCTGCTGCAACGCTCT
TTGAAGCATGCCTCCTTCCTCTTCCGTCAGCAGGCGGGCAGCGGCCTCTCCGAAGAGGAT
GCCCCTGAGCGAGAGGGCCTCATCGCCTACGTGATGAGTGAGAACTTCTCCCGACCCCTT
GGCCCACCCTCCAGCTCCTCCATCTCCTCCACTTCCTTCCCACCCTCCTATGACAGTGTC
ACTAGAGCCACCAGCGATAACCTCCAGGTGCGGGGGTCTGACTACAGCCACAGTGAAGAT
CTCGCCGACTTCCCCCCTTCTCCGGACAGGGACCGTGAGTCCATCGTGTGA
|
| Protein Properties |
|---|
| Number of Residues
| 2016 |
| Molecular Weight
| 226937.5 |
| Theoretical pI
| 5.15 |
| Pfam Domain Function
|
|
| Signals
|
|
|
Transmembrane Regions
|
- ["127-150", "159-178", "192-210", "217-236", "253-276", "390-415", "712-736", "748-771", "780-799", "806-825", "842-862", "914-939", "1201-1224", "1238-1263", "1270-1291", "1296-1317", "1337-1359", "1444-1470", "1524-1547", "1559-1582", "1589-1612", "1623-1644", "1660-1682", "1748-1772"]
|
| Protein Sequence
|
>Sodium channel protein type 5 subunit alpha
MANFLLPRGTSSFRRFTRESLAAIEKRMAEKQARGSTTLQESREGLPEEEAPRPQLDLQA
SKKLPDLYGNPPQELIGEPLEDLDPFYSTQKTFIVLNKGKTIFRFSATNALYVLSPFHPI
RRAAVKILVHSLFNMLIMCTILTNCVFMAQHDPPPWTKYVEYTFTAIYTFESLVKILARG
FCLHAFTFLRDPWNWLDFSVIIMAYTTEFVDLGNVSALRTFRVLRALKTISVISGLKTIV
GALIQSVKKLADVMVLTVFCLSVFALIGLQLFMGNLRHKCVRNFTALNGTNGSVEADGLV
WESLDLYLSDPENYLLKNGTSDVLLCGNSSDAGTCPEGYRCLKAGENPDHGYTSFDSFAW
AFLALFRLMTQDCWERLYQQTLRSAGKIYMIFFMLVIFLGSFYLVNLILAVVAMAYEEQN
QATIAETEEKEKRFQEAMEMLKKEHEALTIRGVDTVSRSSLEMSPLAPVNSHERRSKRRK
RMSSGTEECGEDRLPKSDSEDGPRAMNHLSLTRGLSRTSMKPRSSRGSIFTFRRRDLGSE
ADFADDENSTAGESESHHTSLLVPWPLRRTSAQGQPSPGTSAPGHALHGKKNSTVDCNGV
VSLLGAGDPEATSPGSHLLRPVMLEHPPDTTTPSEEPGGPQMLTSQAPCVDGFEEPGARQ
RALSAVSVLTSALEELEESRHKCPPCWNRLAQRYLIWECCPLWMSIKQGVKLVVMDPFTD
LTITMCIVLNTLFMALEHYNMTSEFEEMLQVGNLVFTGIFTAEMTFKIIALDPYYYFQQG
WNIFDSIIVILSLMELGLSRMSNLSVLRSFRLLRVFKLAKSWPTLNTLIKIIGNSVGALG
NLTLVLAIIVFIFAVVGMQLFGKNYSELRDSDSGLLPRWHMMDFFHAFLIIFRILCGEWI
ETMWDCMEVSGQSLCLLVFLLVMVIGNLVVLNLFLALLLSSFSADNLTAPDEDREMNNLQ
LALARIQRGLRFVKRTTWDFCCGLLRQRPQKPAALAAQGQLPSCIATPYSPPPPETEKVP
PTRKETRFEEGEQPGQGTPGDPEPVCVPIAVAESDTDDQEEDEENSLGTEEESSKQQESQ
PVSGGPEAPPDSRTWSQVSATASSEAEASASQADWRQQWKAEPQAPGCGETPEDSCSEGS
TADMTNTAELLEQIPDLGQDVKDPEDCFTEGCVRRCPCCAVDTTQAPGKVWWRLRKTCYH
IVEHSWFETFIIFMILLSSGALAFEDIYLEERKTIKVLLEYADKMFTYVFVLEMLLKWVA
YGFKKYFTNAWCWLDFLIVDVSLVSLVANTLGFAEMGPIKSLRTLRALRPLRALSRFEGM
RVVVNALVGAIPSIMNVLLVCLIFWLIFSIMGVNLFAGKFGRCINQTEGDLPLNYTIVNN
KSQCESLNLTGELYWTKVKVNFDNVGAGYLALLQVATFKGWMDIMYAAVDSRGYEEQPQW
EYNLYMYIYFVIFIIFGSFFTLNLFIGVIIDNFNQQKKKLGGQDIFMTEEQKKYYNAMKK
LGSKKPQKPIPRPLNKYQGFIFDIVTKQAFDVTIMFLICLNMVTMMVETDDQSPEKINIL
AKINLLFVAIFTGECIVKLAALRHYYFTNSWNIFDFVVVILSIVGTVLSDIIQKYFFSPT
LFRVIRLARIGRILRLIRGAKGIRTLLFALMMSLPALFNIGLLLFLVMFIYSIFGMANFA
YVKWEAGIDDMFNFQTFANSMLCLFQITTSAGWDGLLSPILNTGPPYCDPTLPNSNGSRG
DCGSPAVGILFFTTYIIISFLIVVNMYIAIILENFSVATEESTEPLSEDDFDMFYEIWEK
FDPEATQFIEYSVLSDFADALSEPLRIAKPNQISLINMDLPMVSGDRIHCMDILFAFTKR
VLGESGEMDALKIQMEEKFMAANPSKISYEPITTTLRRKHEEVSAMVIQRAFRRHLLQRS
LKHASFLFRQQAGSGLSEEDAPEREGLIAYVMSENFSRPLGPPSSSSISSTSFPPSYDSV
TRATSDNLQVRGSDYSHSEDLADFPPSPDRDRESIV
|
| External Links |
|---|
| GenBank ID Protein
| 44886082 |
| UniProtKB/Swiss-Prot ID
| Q14524 |
| UniProtKB/Swiss-Prot Entry Name
| SCN5A_HUMAN |
| PDB IDs
|
Not Available |
| GenBank Gene ID
| AB158469 |
| GeneCard ID
| SCN5A |
| GenAtlas ID
| SCN5A |
| HGNC ID
| HGNC:10593 |
| References |
|---|
| General References
| Not Available |