| Identification |
|---|
| HMDB Protein ID
| CDBP02711 |
| Secondary Accession Numbers
| Not Available |
| Name
| Voltage-dependent T-type calcium channel subunit alpha-1H |
| Description
| Not Available |
| Synonyms
|
- Low-voltage-activated calcium channel alpha1 3.2 subunit
- Voltage-gated calcium channel subunit alpha Cav3.2
|
| Gene Name
| CACNA1H |
| Protein Type
| Transporter |
| Biological Properties |
|---|
| General Function
| Involved in ion channel activity |
| Specific Function
| Voltage-sensitive calcium channels (VSCC) mediate the entry of calcium ions into excitable cells and are also involved in a variety of calcium-dependent processes, including muscle contraction, hormone or neurotransmitter release, gene expression, cell motility, cell division and cell death. The isoform alpha-1H gives rise to T-type calcium currents. T-type calcium channels belong to the "low-voltage activated (LVA)" group and are strongly blocked by nickel and mibefradil. A particularity of this type of channels is an opening at quite negative potentials, and a voltage-dependent inactivation. T-type channels serve pacemaking functions in both central neurons and cardiac nodal cells and support calcium signaling in secretory cells and vascular smooth muscle. They may also be involved in the modulation of firing patterns of neurons which is important for information processing as well as in cell growth processes |
| GO Classification
|
| Component |
| membrane |
| cell part |
| membrane part |
| intrinsic to membrane |
| integral to membrane |
| Function |
| calcium channel activity |
| voltage-gated calcium channel activity |
| transmembrane transporter activity |
| substrate-specific transmembrane transporter activity |
| ion transmembrane transporter activity |
| transporter activity |
| ion channel activity |
| cation channel activity |
| Process |
| di-, tri-valent inorganic cation transport |
| divalent metal ion transport |
| calcium ion transport |
| establishment of localization |
| transport |
| transmembrane transport |
| ion transport |
| cation transport |
|
| Cellular Location
|
- Membrane
- Multi-pass membrane protein
|
| Pathways
|
| Name | SMPDB/Pathwhiz | KEGG | | Muscle/Heart Contraction | 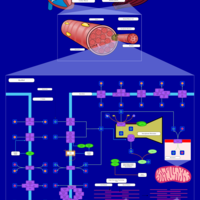 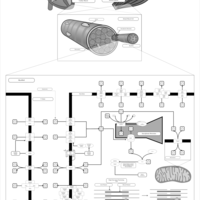  | Not Available | | Acebutolol Action Pathway | 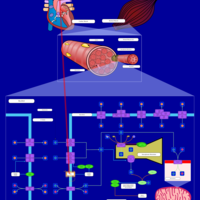 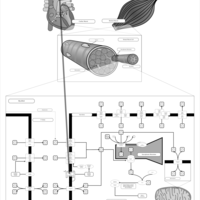  | Not Available | | Alprenolol Action Pathway | 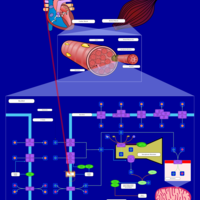 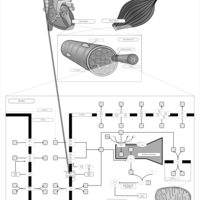  | Not Available | | Atenolol Action Pathway | 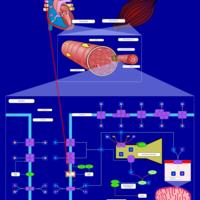 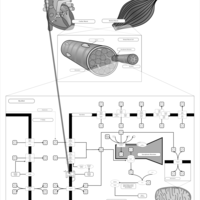  | Not Available | | Betaxolol Action Pathway | 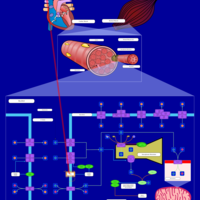   | Not Available |
|
| Gene Properties |
|---|
| Chromosome Location
| Chromosome:1 |
| Locus
| 16p13.3 |
| SNPs
| CACNA1H |
| Gene Sequence
|
>7062 bp
ATGACCGAGGGCGCACGGGCCGCCGACGAGGTCCGGGTGCCCCTGGGCGCGCCGCCCCCT
GGCCCTGCGGCGTTGGTGGGGGCGTCCCCGGAGAGCCCCGGGGCGCCGGGACGCGAGGCG
GAGCGGGGGTCCGAGCTCGGCGTGTCACCCTCCGAGAGCCCGGCGGCCGAGCGCGGCGCG
GAGCTGGGTGCCGACGAGGAGCAGCGCGTCCCGTACCCGGCCTTGGCGGCCACGGTCTTC
TTCTGCCTCGGTCAGACCACGCGGCCGCGCAGCTGGTGCCTCCGGCTGGTCTGCAACCCA
TGGTTCGAGCACGTGAGCATGCTGGTAATCATGCTCAACTGCGTGACCCTGGGCATGTTC
CGGCCCTGTGAGGACGTTGAGTGCGGCTCCGAGCGCTGCAACATCCTGGAGGCCTTTGAC
GCCTTCATTTTCGCCTTTTTTGCGGTGGAGATGGTCATCAAGATGGTGGCCTTGGGGCTG
TTCGGGCAGAAGTGTTACCTGGGTGACACGTGGAACAGGCTGGATTTCTTCATCGTCGTG
GCGGGCATGATGGAGTACTCGTTGGACGGACACAACGTGAGCCTCTCGGCTATCAGGACC
GTGCGGGTGCTGCGGCCCCTCCGCGCCATCAACCGCGTGCCTAGCATGCGGATCCTGGTC
ACTCTGCTGCTGGATACGCTGCCCATGCTCGGGAACGTCCTTCTGCTGTGCTTCTTCGTC
TTCTTCATTTTCGGCATCGTTGGCGTCCAGCTCTGGGCTGGCCTCCTGCGGAACCGCTGC
TTCCTGGACAGTGCCTTTGTCAGGAACAACAACCTGACCTTCCTGCGGCCGTACTACCAG
ACGGAGGAGGGCGAGGAGAACCCGTTCATCTGCTCCTCACGCCGAGACAACGGCATGCAG
AAGTGCTCGCACATCCCCGGCCGCCGCGAGCTGCGCATGCCCTGCACCCTGGGCTGGGAG
GCCTACACGCAGCCGCAGGCCGAGGGGGTGGGCGCTGCACGCAACGCCTGCATCAACTGG
AACCAGTACTACAACGTGTGCCGCTCGGGTGACTCCAACCCCCACAACGGTGCCATCAAC
TTCGACAACATCGGCTACGCCTGGATCGCCATCTTCCAGGTGATCACGCTGGAAGGCTGG
GTGGACATCATGTACTACGTCATGGACGCCCACTCATTCTACAACTTCATCTATTTCATC
CTGCTCATCATCGTGGGCTCCTTCTTCATGATCAACCTGTGCCTGGTGGTGATTGCCACG
CAGTTCTCGGAGACGAAGCAGCGGGAGAGTCAGCTGATGCGGGAGCAGCGGGCACGCCAC
CTGTCCAACGACAGCACGCTGGCCAGCTTCTCCGAGCCTGGCAGCTGCTACGAAGAGCTG
CTGAAGTACGTGGGCCACATATTCCGCAAGGTCAAGCGGCGCAGCTTGCGCCTCTACGCC
CGCTGGCAGAGCCGCTGGCGCAAGAAGGTGGACCCCAGTGCTGTGCAAGGCCAGGGTCCC
GGGCACCGCCAGCGCCGGGCAGGCAGGCACACAGCCTCGGTGCACCACCTGGTCTACCAC
CACCATCACCACCACCACCACCACTACCATTTCAGCCATGGCAGCCCCCGCAGGCCCGGC
CCCGAGCCAGGCGCCTGCGACACCAGGCTGGTCCGAGCTGGCGCGCCCCCCTCGCCACCT
TCCCCAGGCCGCGGACCCCCCGACGCAGAGTCTGTGCACAGCATCTACCATGCCGACTGC
CACATAGAGGGGCCGCAGGAGAGGGCCCGGGTGGCACATGCCGCAGCCACTGCTGCTGCC
AGCCTCAGGCTGGCCACAGGGCTGGGCACCATGAACTACCCCACGATCCTGCCCTCAGGG
GTGGGCAGCGGCAAAGGCAGCACCAGCCCCGGACCCAAGGGGAAGTGGGCCGGTGGACCG
CCAGGCACCGGGGGGCACGGCCCGTTGAGCTTGAACAGCCCTGATCCCTACGAGAAGATC
CCGCATGTGGCCGGGGAGCATGGACTGGGCCAAGCCCCTGGCCATCTGTCGGGCCTCAGT
GTGCCCTGCCCCCTGCCCAGCCCCCCAGCGGGCACACTGACCTGTGAGCTGAAGAGCTGC
CCGTACTGCACCCGTGCCCTGGAGGACCCGGAGGGTGAGCTCAGCGGCTCGGAAAGTGGA
GACTCAGATGGCCGTGGCGTCTATGAATTCACGCAGGACGTCCGGCACGGTGACCGCTGG
GACCCCACGCGACCACCCCGTGCGACGGACACACCAGGCCCAGGCCCAGGCAGCCCCCAG
CGGCGGGCACAGCAGAGGGCAGCCCCGGGCGAGCCAGGCTGGATGGGCCGCCTCTGGGTT
ACCTTCAGCGGCAAGCTGCGCCGCATCGTGGACAGCAAGTACTTCAGCCGTGGCATCATG
ATGGCCATCCTTGTCAACACGCTGAGCATGGGCGTGGAGTACCATGAGCAGCCCGAGGAG
CTGACTAATGCTCTGGAGATCAGCAACATCGTGTTCACCAGCATGTTTGCCCTGGAGATG
CTGCTGAAGCTGCTGGCCTGCGGCCCTCTGGGCTACATCCGGAACCCGTACAACATCTTC
GACGGCATCATCGTGGTCATCAGCGTCTGGGAGATCGTGGGGCAGGCGGACGGTGGCTTG
TCTGTGCTGCGCACCTTCCGGCTGCTGCGTGTGCTGAAGCTGGTGCGCTTTCTGCCAGCC
CTGCGGCGCCAGCTCGTGGTGCTGGTGAAGACCATGGACAACGTGGCTACCTTCTGCACG
CTGCTCATGCTCTTCATTTTCATCTTCAGCATCCTGGGCATGCACCTTTTCGGCTGCAAG
TTCAGCCTGAAGACAGACACCGGAGACACCGTGCCTGACAGGAAGAACTTCGACTCCCTG
CTGTGGGCCATCGTCACCGTGTTCCAGATCCTGACCCAGGAGGACTGGAACGTGGTCCTG
TACAACGGCATGGCCTCCACCTCCTCCTGGGCCGCCCTCTACTTCGTGGCCCTCATGACC
TTCGGCAACTATGTGCTCTTCAACCTGCTGGTGGCCATCCTCGTGGAGGGCTTCCAGGCG
GAGGGCGATGCCAACAGATCCGACACGGACGAGGACAAGACGTCGGTCCACTTCGAGGAG
GACTTCCACAAGCTCAGAGAACTCCAGACCACAGAGCTGAAGATGTGTTCCCTGGCCGTG
ACCCCCAACGGGCACCTGGAGGGACGAGGCAGCCTGTCCCCTCCCCTCATCATGTGCACA
GCTGCCACGCCCATGCCTACCCCCAAGAGCTCACCATTCCTGGATGCAGCCCCCAGCCTC
CCAGACTCTCGGCGTGGCAGCAGCAGCTCCGGGGACCCGCCACTGGGAGACCAGAAGCCT
CCGGCCAGCCTCCGAAGTTCTCCCTGTGCCCCCTGGGGCCCCAGTGGCGCCTGGAGCAGC
CGGCGCTCCAGCTGGAGCAGCCTGGGCCGTGCCCCCAGCCTCAAGCGCCGCGGCCAGTGT
GGGGAACGTGAGTCCCTGCTGTCTGGCGAGGGCAAGGGCAGCACCGACGACGAAGCTGAG
GACGGCAGGGCCGCGCCCGGGCCCCGTGCCACCCCACTGCGGCGGGCCGAGTCCCTGGAC
CCACGGCCCCTGCGGCCGGCCGCCCTCCCGCCTACCAAGTGCCGCGATCGCGACGGGCAG
GTGGTGGCCCTGCCCAGCGACTTCTTCCTGCGCATCGACAGCCACCGTGAGGATGCAGCC
GAGCTTGACGACGACTCGGAGGACAGCTGCTGCCTCCGCCTGCATAAAGTGCTGGAGCCC
TACAAGCCCCAGTGGTGCCGGAGCCGCGAGGCCTGGGCCCTCTACCTCTTCTCCCCACAG
AACCGGTTCCGCGTCTCCTGCCAGAAGGTCATCACACACAAGATGTTTGATCACGTGGTC
CTCGTCTTCATCTTCCTCAACTGCGTCACCATCGCCCTGGAGAGGCCTGACATTGATCCC
GGCAGCACCGAGCGGGTCTTCCTCAGCGTCTCCAATTACATCTTCACGGCCATCTTCGTG
GCGGAGATGATGGTGAAGGTGGTGGCCCTGGGGCTGCTGTCCGGCGAGCACGCCTACCTG
CAGAGCAGCTGGAACCTGCTGGATGGGCTGCTGGTGCTGGTGTCCCTGGTGGACATTGTC
GTGGCCATGGCCTCGGCTGGTGGCGCCAAGATCCTGGGTGTTCTGCGCGTGCTGCGTCTG
CTGCGGACCCTGCGGCCTCTGAGGGTCATCAGCCGGGCCCCGGGCCTCAAGCTGGTGGTG
GAGACGCTGATATCATCACTCAGGCCCATTGGGAACATCGTCCTCATCTGCTGCGCCTTC
TTCATCATTTTTGGCATTTTGGGTGTGCAGCTCTTCAAAGGGAAGTTCTACTACTGCGAG
GGCCCCGACACCAGGAACATCTCCACCAAGGCACAGTGCCGGGCCGCCCACTACCGCTGG
GTGCGACGCAAGTACAACTTCGACAACCTGGGCCAGGCCCTGATGTCGCTGTTCGTGCTG
TCATCCAAGGATGGATGGGTGAACATCATGTACGACGGGCTGGATGCCGTGGGTGTCGAC
CAGCAGCCTGTGCAGAACCACAACCCCTGGATGCTGCTGTACTTCATCTCCTTCCTGCTC
ATCGTCAGCTTCTTCGTGCTCAACATGTTCGTGGGCGTCGTGGTCGAGAACTTCCACAAG
TGCCGGCAGCACCAGGAGGCGGAGGAGGCGCGGCGGCGAGAGGAGAAGCGGCTGCGGCGC
CTAGAGAGGAGGCGCAGGAGCACTTTCCCCAGCCCAGAGGCCCAGCGCCGGCCCTACTAT
GCCGACTACTCGCCCACGCGCCGCTCCATTCACTCGCTGTGCACCAGCCACTATCTCGAC
CTCTTCATCACCTTCATCATCTGTGTCAACGTCATCACCATGTCCATGGAGCACTATAAC
CAACCCAAGTCGCTGGACGAGGCCCTCAAGTACTGCAACTACGTCTTCACCATCGTGTTT
GTCTTCGAGGCTGCACTGAAGCTGGTAGCATTTGGGTTCCGTCGGTTCTTCAAGGACAGG
TGGAACCAGCTGGACCTGGCCATCGTGCTGCTGTCACTCATGGGCATCACGCTGGAGGAG
ATAGAGATGAGCGCCGCGCTGCCCATCAACCCCACCATCATCCGCATCATGCGCGTGCTT
CGCATTGCCCGTGTGCTGAAGCTGCTGAAGATGGCTACGGGCATGCGCGCCCTGCTGGAC
ACTGTGGTGCAAGCTCTCCCCCAGGTGGGGAACCTGGGCCTTCTTTTCATGCTCCTGTTT
TTTATCTATGCTGCGCTGGGAGTGGAGCTGTTCGGGAGGCTGGAGTGCAGTGAAGACAAC
CCCTGCGAGGGCCTGAGCAGGCACGCCACCTTCAGCAACTTCGGCATGGCCTTCCTCACG
CTGTTCCGCGTGTCCACGGGGGACAACTGGAACGGGATCATGAAGGACACGCTGCGCGAG
TGCTCCCGTGAGGACAAGCACTGCCTGAGCTACCTGCCGGCCCTGTCGCCCGTCTACTTC
GTGACCTTCGTGCTGGTGGCCCAGTTCGTGCTGGTGAACGTGGTGGTGGCCGTGCTCATG
AAGCACCTGGAGGAGAGCAACAAGGAGGCACGGGAGGATGCGGAGCTGGACGCCGAGATC
GAGCTGGAGATGGCGCAGGGCCCCGGGAGTGCACGCCGGGTGGACGCGGACAGGCCTCCC
TTGCCCCAGGAGAGTCCGGGCGCCAGGGATGCCCCAAACCTGGTTGCACGCAAGGTGTCC
GTGTCCAGGATGCTCTCGCTGCCCAACGACAGCTACATGTTCAGGCCCGTGGTGCCTGCC
TCGGCGCCCCACCCCCGCCCGCTGCAGGAGGTGGAGATGGAGACCTATGGGGCCGGCACC
CCCTTGGGCTCCGTTGCCTCTGTGCACTCTCCGCCCGCAGAGTCCTGTGCCTCCCTCCAG
ATCCCACTGGCTGTGTCGTCCCCAGCCAGGAGCGGCGAGCCCCTCCACGCCCTGTCCCCT
CGGGGCACAGCCCGCTCCCCCAGTCTCAGCCGGCTGCTCTGCAGACAGGAGGCTGTGCAC
ACCGATTCCTTGGAAGGGAAGATTGACAGCCCTAGGGACACCCTGGATCCTGCAGAGCCT
GGTGAGAAAACCCCGGTGAGGCCGGTGACCCAGGGGGGCTCCCTGCAGTCCCCACCACGC
TCCCCACGGCCCGCCAGCGTCCGCACTCGTAAGCATACCTTCGGACAGCGCTGCGTCTCC
AGCCGGCCGGCGGCCCCAGGCGGAGAGGAGGCCGAGGCCTCGGACCCAGCCGACGAGGAG
GTCAGCCACATCACCAGCTCCGCCTGCCCCTGGCAGCCCACAGCCGAGCCCCATGGCCCC
GAAGCCTCTCCGGTGGCCGGCGGCGAGCGGGACCTGCGCAGGCTCTACAGCGTGGATGCT
CAGGGCTTCCTGGACAAGCCGGGCCGGGCAGACGAGCAGTGGCGGCCCTCGGCGGAGCTG
GGCAGCGGGGAGCCTGGGGAGGCGAAGGCCTGGGGCCCTGAGGCCGAGCCCGCTCTGGGT
GCGCGCAGAAAGAAGAAGATGAGCCCCCCCTGCATCTCGGTGGAACCCCCTGCGGAGGAC
GAGGGCTCTGCGCGGCCCTCCGCGGCAGAGGGCGGCAGCACCACACTGAGGCGCAGGACC
CCGTCCTGTGAGGCCACGCCTCACAGGGACTCCCTGGAGCCCACAGAGGGCTCAGGCGCC
GGGGGGGACCCTGCAGCCAAGGGGGAGCGCTGGGGCCAGGCCTCCTGCCGGGCTGAGCAC
CTGACCGTCCCCAGCTTTGCCTTTGAGCCGCTGGACCTCGGGGTCCCCAGTGGAGACCCT
TTCTTGGACGGTAGCCACAGTGTGACCCCAGAATCCAGAGCTTCCTCTTCAGGGGCCATA
GTGCCCCTGGAACCCCCAGAATCAGAGCCTCCCATGCCCGTCGGTGACCCCCCAGAGAAG
AGGCGGGGGCTGTACCTCACAGTCCCCCAGTGTCCTCTGGAGAAACCAGGGTCCCCCTCA
GCCACCCCTGCCCCAGGGGGTGGTGCAGATGACCCCGTGTAG
|
| Protein Properties |
|---|
| Number of Residues
| 2353 |
| Molecular Weight
| 259160.2 |
| Theoretical pI
| 7.38 |
| Pfam Domain Function
|
|
| Signals
|
|
|
Transmembrane Regions
|
- ["101-119", "140-160", "170-184", "194-212", "233-253", "395-419", "794-814", "828-849", "856-874", "883-906", "918-938", "991-1015", "1291-1313", "1332-1352", "1363-1382", "1397-1418", "1429-1452", "1530-1555", "1617-1637", "1652-1673", "1681-1699", "1714-1737", "1752-1772", "1836-1863"]
|
| Protein Sequence
|
>Voltage-dependent T-type calcium channel subunit alpha-1H
MTEGARAADEVRVPLGAPPPGPAALVGASPESPGAPGREAERGSELGVSPSESPAAERGA
ELGADEEQRVPYPALAATVFFCLGQTTRPRSWCLRLVCNPWFEHVSMLVIMLNCVTLGMF
RPCEDVECGSERCNILEAFDAFIFAFFAVEMVIKMVALGLFGQKCYLGDTWNRLDFFIVV
AGMMEYSLDGHNVSLSAIRTVRVLRPLRAINRVPSMRILVTLLLDTLPMLGNVLLLCFFV
FFIFGIVGVQLWAGLLRNRCFLDSAFVRNNNLTFLRPYYQTEEGEENPFICSSRRDNGMQ
KCSHIPGRRELRMPCTLGWEAYTQPQAEGVGAARNACINWNQYYNVCRSGDSNPHNGAIN
FDNIGYAWIAIFQVITLEGWVDIMYYVMDAHSFYNFIYFILLIIVGSFFMINLCLVVIAT
QFSETKQRESQLMREQRARHLSNDSTLASFSEPGSCYEELLKYVGHIFRKVKRRSLRLYA
RWQSRWRKKVDPSAVQGQGPGHRQRRAGRHTASVHHLVYHHHHHHHHHYHFSHGSPRRPG
PEPGACDTRLVRAGAPPSPPSPGRGPPDAESVHSIYHADCHIEGPQERARVAHAAATAAA
SLRLATGLGTMNYPTILPSGVGSGKGSTSPGPKGKWAGGPPGTGGHGPLSLNSPDPYEKI
PHVVGEHGLGQAPGHLSGLSVPCPLPSPPAGTLTCELKSCPYCTRALEDPEGELSGSESG
DSDGRGVYEFTQDVRHGDRWDPTRPPRATDTPGPGPGSPQRRAQQRAAPGEPGWMGRLWV
TFSGKLRRIVDSKYFSRGIMMAILVNTLSMGVEYHEQPEELTNALEISNIVFTSMFALEM
LLKLLACGPLGYIRNPYNIFDGIIVVISVWEIVGQADGGLSVLRTFRLLRVLKLVRFLPA
LRRQLVVLVKTMDNVATFCTLLMLFIFIFSILGMHLFGCKFSLKTDTGDTVPDRKNFDSL
LWAIVTVFQILTQEDWNVVLYNGMASTSSWAALYFVALMTFGNYVLFNLLVAILVEGFQA
EGDANRSDTDEDKTSVHFEEDFHKLRELQTTELKMCSLAVTPNGHLEGRGSLSPPLIMCT
AATPMPTPKSSPFLDAAPSLPDSRRGSSSSGDPPLGDQKPPASLRSSPCAPWGPSGAWSS
RRSSWSSLGRAPSLKRRGQCGERESLLSGEGKGSTDDEAEDGRAAPGPRATPLRRAESLD
PRPLRPAALPPTKCRDRDGQVVALPSDFFLRIDSHREDAAELDDDSEDSCCLRLHKVLEP
YKPQWCRSREAWALYLFSPQNRFRVSCQKVITHKMFDHVVLVFIFLNCVTIALERPDIDP
GSTERVFLSVSNYIFTAIFVAEMMVKVVALGLLSGEHAYLQSSWNLLDGLLVLVSLVDIV
VAMASAGGAKILGVLRVLRLLRTLRPLRVISRAPGLKLVVETLISSLRPIGNIVLICCAF
FIIFGILGVQLFKGKFYYCEGPDTRNISTKAQCRAAHYRWVRRKYNFDNLGQALMSLFVL
SSKDGWVNIMYDGLDAVGVDQQPVQNHNPWMLLYFISFLLIVSFFVLNMFVGVVVENFHK
CRQHQEAEEARRREEKRLRRLERRRRSTFPSPEAQRRPYYADYSPTRRSIHSLCTSHYLD
LFITFIICVNVITMSMEHYNQPKSLDEALKYCNYVFTIVFVFEAALKLVAFGFRRFFKDR
WNQLDLAIVLLSLMGITLEEIEMSAALPINPTIIRIMRVLRIARVLKLLKMATGMRALLD
TVVQALPQVGNLGLLFMLLFFIYAALGVELFGRLECSEDNPCEGLSRHATFSNFGMAFLT
LFRVSTGDNWNGIMKDTLRECSREDKHCLSYLPALSPVYFVTFVLVAQFVLVNVVVAVLM
KHLEESNKEAREDAELDAEIELEMAQGPGSARRVDADRPPLPQESPGARDAPNLVARKVS
VSRMLSLPNDSYMFRPVVPASAPHPRPLQEVEMETYGAGTPLGSVASVHSPPAESCASLQ
IPLAVSSPARSGEPLHALSPRGTARSPSLSRLLCRQEAVHTDSLEGKIDSPRDTLDPAEP
GEKTPVRPVTQGGSLQSPPRSPRPASVRTRKHTFGQRCVSSRPAAPGGEEAEASDPADEE
VSHITSSACPWQPTAEPHGPEASPVAGGERDLRRLYSVDAQGFLDKPGRADEQWRPSAEL
GSGEPGEAKAWGPEAEPALGARRKKKMSPPCISVEPPAEDEGSARPSAAEGGSTTLRRRT
PSCEATPHRDSLEPTEGSGAGGDPAAKGERWGQASCRAEHLTVPSFAFEPLDLGVPSGDP
FLDGSHSVTPESRASSSGAIVPLEPPESEPPMPVGDPPEKRRGLYLTVPQCPLEKPGSPS
ATPAPGGGADDPV
|
| External Links |
|---|
| GenBank ID Protein
| 14670397 |
| UniProtKB/Swiss-Prot ID
| O95180 |
| UniProtKB/Swiss-Prot Entry Name
| CAC1H_HUMAN |
| PDB IDs
|
Not Available |
| GenBank Gene ID
| AF051946 |
| GeneCard ID
| CACNA1H |
| GenAtlas ID
| CACNA1H |
| HGNC ID
| HGNC:1395 |
| References |
|---|
| General References
| Not Available |