| Identification |
|---|
| HMDB Protein ID
| CDBP02710 |
| Secondary Accession Numbers
| Not Available |
| Name
| Voltage-dependent T-type calcium channel subunit alpha-1G |
| Description
| Not Available |
| Synonyms
|
- Cav3.1c
- NBR13
- Voltage-gated calcium channel subunit alpha Cav3.1
|
| Gene Name
| CACNA1G |
| Protein Type
| Transporter |
| Biological Properties |
|---|
| General Function
| Involved in ion channel activity |
| Specific Function
| Voltage-sensitive calcium channels (VSCC) mediate the entry of calcium ions into excitable cells and are also involved in a variety of calcium-dependent processes, including muscle contraction, hormone or neurotransmitter release, gene expression, cell motility, cell division and cell death. The isoform alpha-1G gives rise to T-type calcium currents. T-type calcium channels belong to the "low-voltage activated (LVA)" group and are strongly blocked by mibefradil. A particularity of this type of channels is an opening at quite negative potentials and a voltage-dependent inactivation. T-type channels serve pacemaking functions in both central neurons and cardiac nodal cells and support calcium signaling in secretory cells and vascular smooth muscle. They may also be involved in the modulation of firing patterns of neurons which is important for information processing as well as in cell growth processes |
| GO Classification
|
| Component |
| cell part |
| membrane part |
| ion channel complex |
| cation channel complex |
| macromolecular complex |
| intrinsic to membrane |
| protein complex |
| integral to membrane |
| calcium channel complex |
| voltage-gated calcium channel complex |
| membrane |
| Function |
| calcium channel activity |
| voltage-gated calcium channel activity |
| transmembrane transporter activity |
| substrate-specific transmembrane transporter activity |
| ion transmembrane transporter activity |
| transporter activity |
| ion channel activity |
| cation channel activity |
| Process |
| di-, tri-valent inorganic cation transport |
| divalent metal ion transport |
| calcium ion transport |
| establishment of localization |
| transport |
| transmembrane transport |
| ion transport |
| cation transport |
|
| Cellular Location
|
- Membrane
- Multi-pass membrane protein
|
| Pathways
|
| Name | SMPDB/Pathwhiz | KEGG | | Muscle/Heart Contraction | 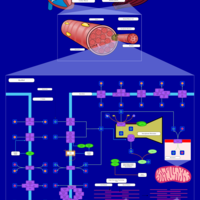 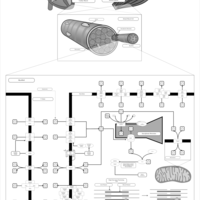  | Not Available | | Acebutolol Action Pathway | 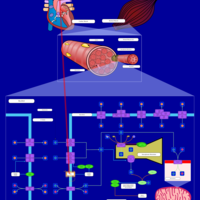 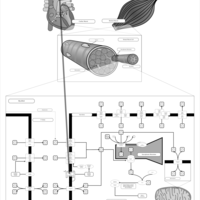  | Not Available | | Alprenolol Action Pathway | 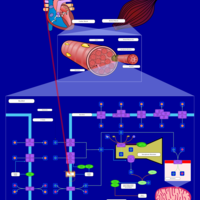 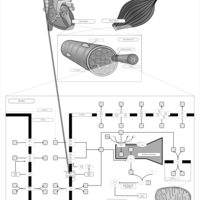  | Not Available | | Atenolol Action Pathway | 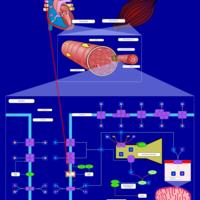 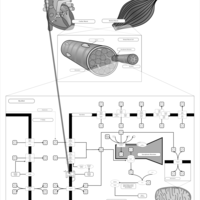  | Not Available | | Betaxolol Action Pathway | 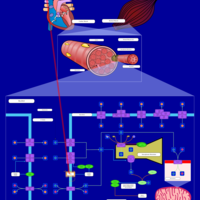   | Not Available |
|
| Gene Properties |
|---|
| Chromosome Location
| Chromosome:1 |
| Locus
| 17q22 |
| SNPs
| CACNA1G |
| Gene Sequence
|
>7134 bp
ATGGACGAGGAGGAGGATGGAGCGGGCGCCGAGGAGTCGGGACAGCCCCGGAGCTTCATG
CGGCTCAACGACCTGTCGGGGGCCGGGGGCCGGCCGGGGCCGGGGTCAGCAGAAAAGGAC
CCGGGCAGCGCGGACTCCGAGGCGGAGGGGCTGCCGTACCCGGCGCTGGCCCCGGTGGTT
TTCTTCTACTTGAGCCAGGACAGCCGCCCGCGGAGCTGGTGTCTCCGCACGGTCTGTAAC
CCCTGGTTTGAGCGCATCAGCATGTTGGTCATCCTTCTCAACTGCGTGACCCTGGGCATG
TTCCGGCCATGCGAGGACATCGCCTGTGACTCCCAGCGCTGCCGGATCCTGCAGGCCTTT
GATGACTTCATCTTTGCCTTCTTTGCCGTGGAGATGGTGGTGAAGATGGTGGCCTTGGGC
ATCTTTGGGAAAAAGTGTTACCTGGGAGACACTTGGAACCGGCTTGACTTTTTCATCGTC
ATCGCAGGGATGCTGGAGTACTCGCTGGACCTGCAGAACGTCAGCTTCTCAGCTGTCAGG
ACAGTCCGTGTGCTGCGACCGCTCAGGGCCATTAACCGGGTGCCCAGCATGCGCATCCTT
GTCACGTTGCTGCTGGATACGCTGCCCATGCTGGGCAACGTCCTGCTGCTCTGCTTCTTC
GTCTTCTTCATCTTCGGCATCGTCGGCGTCCAGCTGTGGGCAGGGCTGCTTCGGAACCGA
TGCTTCCTACCTGAGAATTTCAGCCTCCCCCTGAGCGTGGACCTGGAGCGCTATTACCAG
ACAGAGAACGAGGATGAGAGCCCCTTCATCTGCTCCCAGCCACGCGAGAACGGCATGCGG
TCCTGCAGAAGCGTGCCCACGCTGCGCGGGGACGGGGGCGGTGGCCCACCTTGCGGTCTG
GACTATGAGGCCTACAACAGCTCCAGCAACACCACCTGTGTCAACTGGAACCAGTACTAC
ACCAACTGCTCAGCGGGGGAGCACAACCCCTTCAAGGGCGCCATCAACTTTGACAACATT
GGCTATGCCTGGATCGCCATCTTCCAGGTCATCACGCTGGAGGGCTGGGTCGACATCATG
TACTTTGTGATGGATGCTCATTCCTTCTACAATTTCATCTACTTCATCCTCCTCATCATC
GTGGGCTCCTTCTTCATGATCAACCTGTGCCTGGTGGTGATTGCCACGCAGTTCTCAGAG
ACCAAGCAGCGGGAAAGCCAGCTGATGCGGGAGCAGCGTGTGCGGTTCCTGTCCAACGCC
AGCACCCTGGCTAGCTTCTCTGAGCCCGGCAGCTGCTATGAGGAGCTGCTCAAGTACCTG
GTGTACATCCTTCGTAAGGCAGCCCGCAGGCTGGCTCAGGTCTCTCGGGCAGCAGGTGTG
CGGGTTGGGCTGCTCAGCAGCCCAGCACCCCTCGGGGGCCAGGAGACCCAGCCCAGCAGC
AGCTGCTCTCGCTCCCACCGCCGCCTATCCGTCCACCACCTGGTGCACCACCACCACCAC
CATCACCACCACTACCACCTGGGCAATGGGACGCTCAGGGCCCCCCGGGCCAGCCCGGAG
ATCCAGGACAGGGATGCCAATGGGTCCCGCAGGCTCATGCTGCCACCACCCTCGACGCCT
GCCCTCTCCGGGGCCCCCCCTGGTGGCGCAGAGTCTGTGCACAGCTTCTACCATGCCGAC
TGCCACTTAGAGCCAGTCCGCTGCCAGGCGCCCCCTCCCAGGTCCCCATCTGAGGCATCC
GGCAGGACTGTGGGCAGCGGGAAGGTGTATCCCACCGTGCACACCAGCCCTCCACCGGAG
ACGCTGAAGGAGAAGGCACTAGTAGAGGTGGCTGCCAGCTCTGGGCCCCCAACCCTCACC
AGCCTCAACATCCCACCCGGGCCCTACAGCTCCATGCACAAGCTGCTGGAGACACAGAGT
ACAGGTGCCTGCCAAAGCTCTTGCAAGATCTCCAGCCCTTGCTTGAAAGCAGACAGTGGA
GCCTGTGGTCCAGACAGCTGCCCCTACTGTGCCCGGGCCGGGGCAGGGGAGGTGGAGCTC
GCCGACCGTGAAATGCCTGACTCAGACAGCGAGGCAGTTTATGAGTTCACACAGGATGCC
CAGCACAGCGACCTCCGGGACCCCCACAGCCGGCGGCAACGGAGCCTGGGCCCAGATGCA
GAGCCCAGCTCTGTGCTGGCCTTCTGGAGGCTAATCTGTGACACCTTCCGAAAGATTGTG
GACAGCAAGTACTTTGGCCGGGGAATCATGATCGCCATCCTGGTCAACACACTCAGCATG
GGCATCGAATACCACGAGCAGCCCGAGGAGCTTACCAACGCCCTAGAAATCAGCAACATC
GTCTTCACCAGCCTCTTTGCCCTGGAGATGCTGCTGAAGCTGCTTGTGTATGGTCCCTTT
GGCTACATCAAGAATCCCTACAACATCTTCGATGGTGTCATTGTGGTCATCAGCGTGTGG
GAGATCGTGGGCCAGCAGGGGGGCGGCCTGTCGGTGCTGCGGACCTTCCGCCTGATGCGT
GTGCTGAAGCTGGTGCGCTTCCTGCCGGCGCTGCAGCGGCAGCTGGTGGTGCTCATGAAG
ACCATGGACAACGTGGCCACCTTCTGCATGCTGCTTATGCTCTTCATCTTCATCTTCAGC
ATCCTGGGCATGCATCTCTTCGGCTGCAAGTTTGCCTCTGAGCGGGATGGGGACACCCTG
CCAGACCGGAAGAATTTTGACTCCTTGCTCTGGGCCATCGTCACTGTCTTTCAGATCCTG
ACCCAGGAGGACTGGAACAAAGTCCTCTACAATGGTATGGCCTCCACGTCGTCCTGGGCG
GCCCTTTATTTCATTGCCCTCATGACCTTCGGCAACTACGTGCTCTTCAATTTGCTGGTC
GCCATTCTGGTGGAGGGCTTCCAGGCGGAGGAAATCAGCAAACGGGAAGATGCGAGTGGA
CAGTTAAGCTGTATTCAGCTGCCTGTCGACTCCCAGGGGGGAGATGCCAACAAGTCCGAA
TCAGAGCCCGATTTCTTCTCACCCAGCCTGGATGGTGATGGGGACAGGAAGAAGTGCTTG
GCCTTGGTGTCCCTGGGAGAGCACCCGGAGCTGCGGAAGAGCCTGCTGCCGCCTCTCATC
ATCCACACGGCCGCCACACCCATGTCGCTGCCCAAGAGCACCAGCACGGGCCTGGGCGAG
GCGCTGGGCCCTGCGTCGCGCCGCACCAGCAGCAGCGGGTCGGCAGAGCCTGGGGCGGCC
CACGAGATGAAGTCACCGCCCAGCGCCCGCAGCTCTCCGCACAGCCCCTGGAGCGCTGCA
AGCAGCTGGACCAGCAGGCGCTCCAGCCGGAACAGCCTCGGCCGTGCACCCAGCCTGAAG
CGGAGAAGCCCAAGTGGAGAGCGGCGGTCCCTGTTGTCGGGAGAAGGCCAGGAGAGCCAG
GATGAAGAGGAGAGCTCAGAAGAGGAGCGGGCCAGCCCTGCGGGCAGTGACCATCGCCAC
AGGGGGTCCCTGGAGCGGGAGGCCAAGAGTTCCTTTGACCTGCCAGACACACTGCAGGTG
CCAGGGCTGCATCGCACTGCCAGTGGCCGAGGGTCTGCTTCTGAGCACCAGGACTGCAAT
GGCAAGTCGGCTTCAGGGCGCCTGGCCCGGGCCCTGCGGCCTGATGACCCCCCACTGGAT
GGGGATGACGCCGATGACGAGGGCAACCTGAGCAAAGGGGAACGGGTCCGCGCGTGGATC
CGAGCCCGACTCCCTGCCTGCTGCCTCGAGCGAGACTCCTGGTCAGCCTACATCTTCCCT
CCTCAGTCCAGGTTCCGCCTCCTGTGTCACCGGATCATCACCCACAAGATGTTCGACCAC
GTGGTCCTTGTCATCATCTTCCTTAACTGCATCACCATCGCCATGGAGCGCCCCAAAATT
GACCCCCACAGCGCTGAACGCATCTTCCTGACCCTCTCCAATTACATCTTCACCGCAGTC
TTTCTGGCTGAAATGACAGTGAAGGTGGTGGCACTGGGCTGGTGCTTCGGGGAGCAGGCG
TACCTGCGGAGCAGTTGGAACGTGCTGGACGGGCTGTTGGTGCTCATCTCCGTCATCGAC
ATTCTGGTGTCCATGGTCTCTGACAGCGGCACCAAGATCCTGGGCATGCTGAGGGTGCTG
CGGCTGCTGCGGACCCTGCGCCCGCTCAGGGTGATCAGCCGGGCGCAGGGGCTGAAGCTG
GTGGTGGAGACGCTGATGTCCTCACTGAAACCCATCGGCAACATTGTAGTCATCTGCTGT
GCCTTCTTCATCATTTTCGGCATCTTGGGGGTGCAGCTCTTCAAAGGGAAGTTTTTCGTG
TGCCAGGGCGAGGATACCAGGAACATCACCAATAAATCGGACTGTGCCGAGGCCAGTTAC
CGGTGGGTCCGGCACAAGTACAACTTTGACAACCTTGGCCAGGCCCTGATGTCCCTGTTC
GTTTTGGCCTCCAAGGATGGTTGGGTGGACATCATGTACGATGGGCTGGATGCTGTGGGC
GTGGACCAGCAGCCCATCATGAACCACAACCCCTGGATGCTGCTGTACTTCATCTCGTTC
CTGCTCATTGTGGCCTTCTTTGTCCTGAACATGTTTGTGGGTGTGGTGGTGGAGAACTTC
CACAAGTGTCGGCAGCACCAGGAGGAAGAGGAGGCCCGGCGGCGGGAGGAGAAGCGCCTA
CGAAGACTGGAGAAAAAGAGAAGGAATCTAATGCTGGACGATGTAATTGCTTCCGGCAGC
TCAGCCAGCGCTGCGTCAGAAGCCCAGTGCAAACCTTACTACTCCGACTACTCCCGCTTC
CGGCTCCTCGTCCACCACTTGTGCACCAGCCACTACCTGGACCTCTTCATCACAGGTGTC
ATCGGGCTGAACGTGGTCACCATGGCCATGGAGCACTACCAGCAGCCCCAGATTCTGGAT
GAGGCTCTGAAGATCTGCAACTACATCTTCACTGTCATCTTTGTCTTGGAGTCAGTTTTC
AAACTTGTGGCCTTTGGTTTCCGTCGGTTCTTCCAGGACAGGTGGAACCAGCTGGACCTG
GCCATTGTGCTGCTGTCCATCATGGGCATCACGCTGGAGGAAATCGAGGTCAACGCCTCG
CTGCCCATCAACCCCACCATCATCCGCATCATGAGGGTGCTGCGCATTGCCCGAGTGCTG
AAGCTGCTGAAGATGGCTGTGGGCATGCGGGCGCTGCTGGACACGGTGATGCAGGCCCTG
CCCCAGGTGGGGAACCTGGGACTTCTCTTCATGTTGTTGTTTTTCATCTTTGCAGCTCTG
GGCGTGGAGCTCTTTGGAGACCTGGAGTGTGACGAGACACACCCCTGTGAGGGCCTGGGC
CGTCATGCCACCTTTCGGAACTTTGGCATGGCCTTCCTAACCCTCTTCCGAGTCTCCACA
GGTGACAATTGGAATGGCATTATGAAGGACACCCTCCGGGACTGTGACCAGGAGTCCACC
TGCTACAACACGGTCATCTCGCCTATCTACTTTGTGTCCTTCGTGCTGACGGCCCAGTTC
GTGCTAGTCAACGTGGTGATCGCCGTGCTGATGAAGCACCTGGAGGAGAGCAACAAGGAG
GCCAAGGAGGAGGCCGAGCTAGAGGCTGAGCTGGAGCTGGAGATGAAGACCCTCAGCCCC
CAGCCCCACTCGCCACTGGGCAGCCCCTTCCTCTGGCCTGGGGTCGAGGGCCCCGACAGC
CCCGACAGCCCCAAGCCTGGGGCTCTGCACCCAGCGGCCCACGCGAGATCAGCCTCCCAC
TTTTCCCTGGAGCACCCCACGGACAGGCAGCTGTTTGACACCATATCCCTGCTGATCCAG
GGCTCCCTGGAGTGGGAGCTGAAGCTGATGGACGAGCTGGCAGGCCCAGGGGGCCAGCCC
TCTGCCTTCCCTTCTGCCCCCAGCCTGGGAGGCTCCGACCCACAGATCCCTCTAGCTGAG
ATGGAGGCTCTGTCTCTGACGTCAGAGATTGTGTCTGAACCGTCCTGCTCTCTAGCTCTG
ACGGATGACTCTTTGCCTGATGACATGCACACACTCTTACTTAGTGCCCTGGAGAGCAAT
ATGCAGCCCCACCCCACGGAGCTGCCAGGACCAGACTTACTGACTGTGCGGAAGTCTGGG
GTCAGCCGAACGCACTCTCTGCCCAATGACAGCTACATGTGTCGGCATGGGAGCACTGCC
GAGGGGCCCCTGGGACACAGGGGCTGGGGGCTCCCCAAAGCTCAGTCAGGCTCCGTCTTG
TCCGTTCACTCCCAGCCAGCAGATACCAGCTACATCCTGCAGCTTCCCAAAGATGCACCT
CATCTGCTCCAGCCCCACAGCGCCCCAACCTGGGGCACCATCCCCAAACTGCCCCCACCA
GGACGCTCCCCTTTGGCTCAGAGGCCACTCAGGCGCCAGGCAGCAATAAGGACTGACTCC
TTGGACGTTCAGGGTCTGGGCAGCCGGGAAGACCTGCTGGCAGAGGTGAGTGGGCCCTCC
CCGCCCCTGGCCCGGGCCTACTCTTTCTGGGGCCAGTCAAGTACCCAGGCACAGCAGCAC
TCCCGCAGCCACAGCAAGATCTCCAAGCACATGACCCCGCCAGCCCCTTGCCCAGGCCCA
GAACCCAACTGGGGCAAGGGCCCTCCAGAGACCAGAAGCAGCTTAGAGTTGGACACGGAG
CTGAGCTGGATTTCAGGAGACCTCCTGCCCCCTGGCGGCCAGGAGGAGCCCCCATCCCCA
CGGGACCTGAAGAAGTGCTACAGCGTGGAGGCCCAGAGCTGCCAGCGCCGGCCTACGTCC
TGGCTGGATGAGCAGAGGAGACACTCTATCGCCGTCAGCTGCCTGGACAGCGGCTCCCAA
CCCCACCTGGGCACAGACCCCTCTAACCTTGGGGGCCAGCCTCTTGGGGGGCCTGGGAGC
CGGCCCAAGAAAAAACTCAGCCCGCCTAGTATCACCATAGACCCCCCCGAGAGCCAAGGT
CCTCGGACCCCGCCCAGCCCTGGTATCTGCCTCCGGAGGAGGGCTCCGTCCAGCGACTCC
AAGGATCCCTTGGCCTCTGGCCCCCCTGACAGCATGGCTGCCTCGCCCTCCCCAAAGAAA
GATGTGCTGAGTCTCTCCGGTTTATCCTCTGACCCAGCAGACCTGGACCCCTGA
|
| Protein Properties |
|---|
| Number of Residues
| 2377 |
| Molecular Weight
| 262468.6 |
| Theoretical pI
| 6.57 |
| Pfam Domain Function
|
|
| Signals
|
|
|
Transmembrane Regions
|
- ["81-101", "120-141", "151-170", "176-193", "214-234", "371-395", "744-764", "778-799", "806-824", "833-856", "868-888", "940-964", "1273-1295", "1314-1334", "1345-1364", "1379-1400", "1411-1434", "1512-1537", "1611-1631", "1646-1667", "1675-1693", "1708-1731", "1746-1766", "1827-1854"]
|
| Protein Sequence
|
>Voltage-dependent T-type calcium channel subunit alpha-1G
MDEEEDGAGAEESGQPRSFMRLNDLSGAGGRPGPGSAEKDPGSADSEAEGLPYPALAPVV
FFYLSQDSRPRSWCLRTVCNPWFERISMLVILLNCVTLGMFRPCEDIACDSQRCRILQAF
DDFIFAFFAVEMVVKMVALGIFGKKCYLGDTWNRLDFFIVIAGMLEYSLDLQNVSFSAVR
TVRVLRPLRAINRVPSMRILVTLLLDTLPMLGNVLLLCFFVFFIFGIVGVQLWAGLLRNR
CFLPENFSLPLSVDLERYYQTENEDESPFICSQPRENGMRSCRSVPTLRGDGGGGPPCGL
DYEAYNSSSNTTCVNWNQYYTNCSAGEHNPFKGAINFDNIGYAWIAIFQVITLEGWVDIM
YFVMDAHSFYNFIYFILLIIVGSFFMINLCLVVIATQFSETKQRESQLMREQRVRFLSNA
STLASFSEPGSCYEELLKYLVYILRKAARRLAQVSRAAGVRVGLLSSPAPLGGQETQPSS
SCSRSHRRLSVHHLVHHHHHHHHHYHLGNGTLRAPRASPEIQDRDANGSRRLMLPPPSTP
ALSGAPPGGAESVHSFYHADCHLEPVRCQAPPPRSPSEASGRTVGSGKVYPTVHTSPPPE
TLKEKALVEVAASSGPPTLTSLNIPPGPYSSMHKLLETQSTGACQSSCKISSPCLKADSG
ACGPDSCPYCARAGAGEVELADREMPDSDSEAVYEFTQDAQHSDLRDPHSRRQRSLGPDA
EPSSVLAFWRLICDTFRKIVDSKYFGRGIMIAILVNTLSMGIEYHEQPEELTNALEISNI
VFTSLFALEMLLKLLVYGPFGYIKNPYNIFDGVIVVISVWEIVGQQGGGLSVLRTFRLMR
VLKLVRFLPALQRQLVVLMKTMDNVATFCMLLMLFIFIFSILGMHLFGCKFASERDGDTL
PDRKNFDSLLWAIVTVFQILTQEDWNKVLYNGMASTSSWAALYFIALMTFGNYVLFNLLV
AILVEGFQAEEISKREDASGQLSCIQLPVDSQGGDANKSESEPDFFSPSLDGDGDRKKCL
ALVSLGEHPELRKSLLPPLIIHTAATPMSLPKSTSTGLGEALGPASRRTSSSGSAEPGAA
HEMKSPPSARSSPHSPWSAASSWTSRRSSRNSLGRAPSLKRRSPSGERRSLLSGEGQESQ
DEEESSEEERASPAGSDHRHRGSLEREAKSSFDLPDTLQVPGLHRTASGRGSASEHQDCN
GKSASGRLARALRPDDPPLDGDDADDEGNLSKGERVRAWIRARLPACCLERDSWSAYIFP
PQSRFRLLCHRIITHKMFDHVVLVIIFLNCITIAMERPKIDPHSAERIFLTLSNYIFTAV
FLAEMTVKVVALGWCFGEQAYLRSSWNVLDGLLVLISVIDILVSMVSDSGTKILGMLRVL
RLLRTLRPLRVISRAQGLKLVVETLMSSLKPIGNIVVICCAFFIIFGILGVQLFKGKFFV
CQGEDTRNITNKSDCAEASYRWVRHKYNFDNLGQALMSLFVLASKDGWVDIMYDGLDAVG
VDQQPIMNHNPWMLLYFISFLLIVAFFVLNMFVGVVVENFHKCRQHQEEEEARRREEKRL
RRLEKKRRNLMLDDVIASGSSASAASEAQCKPYYSDYSRFRLLVHHLCTSHYLDLFITGV
IGLNVVTMAMEHYQQPQILDEALKICNYIFTVIFVLESVFKLVAFGFRRFFQDRWNQLDL
AIVLLSIMGITLEEIEVNASLPINPTIIRIMRVLRIARVLKLLKMAVGMRALLDTVMQAL
PQVGNLGLLFMLLFFIFAALGVELFGDLECDETHPCEGLGRHATFRNFGMAFLTLFRVST
GDNWNGIMKDTLRDCDQESTCYNTVISPIYFVSFVLTAQFVLVNVVIAVLMKHLEESNKE
AKEEAELEAELELEMKTLSPQPHSPLGSPFLWPGVEGPDSPDSPKPGALHPAAHARSASH
FSLEHPTDRQLFDTISLLIQGSLEWELKLMDELAGPGGQPSAFPSAPSLGGSDPQIPLAE
MEALSLTSEIVSEPSCSLALTDDSLPDDMHTLLLSALESNMQPHPTELPGPDLLTVRKSG
VSRTHSLPNDSYMCRHGSTAEGPLGHRGWGLPKAQSGSVLSVHSQPADTSYILQLPKDAP
HLLQPHSAPTWGTIPKLPPPGRSPLAQRPLRRQAAIRTDSLDVQGLGSREDLLAEVSGPS
PPLARAYSFWGQSSTQAQQHSRSHSKISKHMTPPAPCPGPEPNWGKGPPETRSSLELDTE
LSWISGDLLPPGGQEEPPSPRDLKKCYSVEAQSCQRRPTSWLDEQRRHSIAVSCLDSGSQ
PHLGTDPSNLGGQPLGGPGSRPKKKLSPPSITIDPPESQGPRTPPSPGICLRRRAPSSDS
KDPLASGPPDSMAASPSPKKDVLSLSGLSSDPADLDP
|
| External Links |
|---|
| GenBank ID Protein
| 6625659 |
| UniProtKB/Swiss-Prot ID
| O43497 |
| UniProtKB/Swiss-Prot Entry Name
| CAC1G_HUMAN |
| PDB IDs
|
Not Available |
| GenBank Gene ID
| AF134986 |
| GeneCard ID
| CACNA1G |
| GenAtlas ID
| CACNA1G |
| HGNC ID
| HGNC:1394 |
| References |
|---|
| General References
| Not Available |