| Identification |
|---|
| HMDB Protein ID
| CDBP02333 |
| Secondary Accession Numbers
| Not Available |
| Name
| CAD protein |
| Description
| Not Available |
| Synonyms
|
- Aspartate carbamoyltransferase
- Dihydroorotase
- Glutamine-dependent carbamoyl-phosphate synthase
|
| Gene Name
| CAD |
| Protein Type
| Metal Binding |
| Biological Properties |
|---|
| General Function
| Involved in hydrolase activity |
| Specific Function
| This protein is a "fusion" protein encoding four enzymatic activities of the pyrimidine pathway (GATase, CPSase, ATCase and DHOase).
|
| GO Classification
|
| Biological Process |
| glutamine catabolic process |
| 'de novo' pyrimidine nucleobase biosynthetic process |
| 'de novo' UMP biosynthetic process |
| peptidyl-threonine phosphorylation |
| protein autophosphorylation |
| response to caffeine |
| response to amine stimulus |
| embryo development |
| female pregnancy |
| pyrimidine nucleoside biosynthetic process |
| glutamine metabolic process |
| organ regeneration |
| drug metabolic process |
| response to testosterone stimulus |
| carbamoyl phosphate biosynthetic process |
| Cellular Component |
| cytosol |
| terminal button |
| nuclear matrix |
| neuronal cell body |
| protein complex |
| Function |
| transferase activity |
| nucleoside binding |
| purine nucleoside binding |
| adenyl nucleotide binding |
| adenyl ribonucleotide binding |
| atp binding |
| ligase activity |
| carboxyl- or carbamoyltransferase activity |
| carbamoyl-phosphate synthase activity |
| ligase activity, forming carbon-nitrogen bonds |
| carboxylic acid binding |
| amino acid binding |
| binding |
| hydrolase activity, acting on carbon-nitrogen (but not peptide) bonds, in cyclic amides |
| aspartate carbamoyltransferase activity |
| catalytic activity |
| transferase activity, transferring one-carbon groups |
| hydrolase activity |
| hydrolase activity, acting on carbon-nitrogen (but not peptide) bonds |
| Molecular Function |
| ATP binding |
| protein kinase activity |
| aspartate binding |
| aspartate carbamoyltransferase activity |
| carbamoyl-phosphate synthase (glutamine-hydrolyzing) activity |
| dihydroorotase activity |
| identical protein binding |
| metal ion binding |
| Process |
| cellular amino acid and derivative metabolic process |
| cellular amino acid metabolic process |
| metabolic process |
| nitrogen compound metabolic process |
| cellular aromatic compound metabolic process |
| cellular metabolic process |
| glutamine metabolic process |
| glutamine family amino acid metabolic process |
| nucleobase metabolic process |
| pyrimidine base metabolic process |
| pyrimidine base biosynthetic process |
| 'de novo' pyrimidine base biosynthetic process |
|
| Cellular Location
|
- Cytoplasm
|
| Pathways
|
| Name | SMPDB/Pathwhiz | KEGG | | Pyrimidine Metabolism |  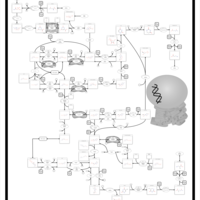  | 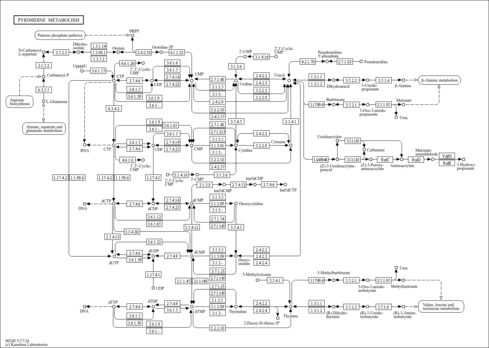 | | Glutamate Metabolism |    | 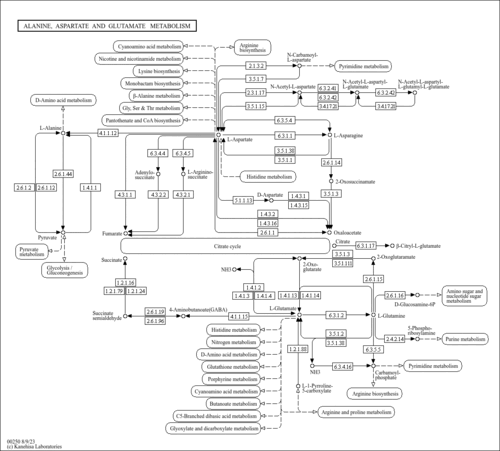 | | Aspartate Metabolism |    | | | UMP biosynthesis via de novo pathway | Not Available | Not Available | | Alanine, aspartate and glutamate metabolism | Not Available | |
|
| Gene Properties |
|---|
| Chromosome Location
| 2 |
| Locus
| 2p22-p21 |
| SNPs
| CAD |
| Gene Sequence
|
>6678 bp
ATGGCGGCCCTAGTGTTGGAGGACGGGTCGGTCCTGCGGGGCCAGCCCTTTGGGGCCGCC
GTGTCGACTGCCGGGGAAGTGGTGTTTCAAACCGGCATGGTCGGCTACCCCGAGGCCCTC
ACTGATCCCTCCTACAAGGCACAGATCTTAGTGCTCACCTATCCTCTGATCGGCAACTAT
GGCATCCCCCCAGATGAAATGGATGAGTTCGGTCTCTGCAAGTGGTTTGAATCCTCGGGC
ATCCACGTAGCAGCACTGGTAGTGGGAGAGTGCTGTCCTACTCCCAGCCACTGGAGTGCC
ACCCGCACCCTGCATGAGTGGCTGCAGCAGCATGGCATCCCTGGCTTGCAAGGAGTAGAC
ACTCGGGAGCTGACCAAGAAGTTGCGGGAACAGGGGTCTCTGCTGGGGAAGCTGGTCCAG
AATGGAACAGAACCTTCATCCCTGCCATTCTTGGACCCCAATGCCCGCCCCCTGGTACCA
GAGGTCTCCATTAAGACTCCACGGGTATTCAATACAGGGGGTGCCCCTCGGATCCTTGCT
TTGGACTGTGGCCTCAAGTATAATCAGATCCGATGCCTCTGCCAGCGTGGGGCTGAGGTC
ACTGTGGTACCCTGGGACCATGCACTAGACAGCCAAGAGTATGAGGGTCTCTTCTTAAGT
AATGGGCCTGGTGACCCTGCCTCCTATCCCAGTGTCGTATCCACACTGAGCCGTGTTTTA
TCTGAGCCTAATCCCCGACCTGTCTTTGGGATCTGCCTGGGACACCAGCTATTGGCCTTA
GCCATTGGGGCCAAGACTTACAAGATGAGATATGGGAACCGAGGCCATAACCAGCCCTGC
TTGTTGGTGGGCTCTGGGCGCTGCTTTCTGACATCCCAGAACCATGGGTTTGCTGTGGAG
ACAGACTCACTGCCAGCAGACTGGGCTCCTCTCTTCACCAACGCCAATGATGGTTCCAAT
GAAGGCATTGTGCACAACAGCTTGCCTTTCTTCAGTGTCCAGTTTCACCCAGAGCACCAA
GCTGGCCCTTCAGATATGGAACTGCTTTTCGATATCTTTCTGGAAACTGTGAAAGAGGCC
ACAGCTGGGAACCCTGGGGGCCAGACAGTTAGAGAGCGGCTGACTGAGCGCCTCTGTCCC
CCTGGGATTCCCACTCCCGGCTCTGGACTTCCACCACCACGAAAGGTTCTGATCCTGGGC
TCAGGGGGCCTCTCCATTGGCCAAGCTGGAGAATTTGACTACTCGGGCTCTCAGGCAATT
AAGGCCCTGAAGGAGGAAAACATCCAGACGTTGCTGATCAACCCCAATATTGCCACAGTG
CAGACCTCCCAGGGGCTGGCCGACAAGGTCTATTTTCTTCCCATAACACCTCATTATGTA
ACCCAGGTGATACGTAATGAACGCCCCGATGGTGTGTTACTGACTTTTGGGGGCCAGACT
GCTCTGAACTGTGGTGTGGAGCTGACCAAGGCCGGGGTGCTGGCTCGGTATGGGGTCCGG
GTCCTGGGCACAACAGTGGAGACCATTGAGCTGACCGAGGATCGACGGGCCTTTGCTGCC
AGAATGGCAGAGATCGGAGAGCATGTGGCCCCGAGCGAGGCAGGAAATTCTCTTGAACAG
GCCCAGGCAGCCGCTGAACGGCTGGGGTACCCTGTGCTAGTGCGTGCAGCCTTTGCCGTG
GGTGGCCTGGGCTCTGGCTTTGCCTCTAACAGGGAGGAGCTCTCTGCTCTCGTGGCCCCA
GCTTTTGCCCATACCAGCCAAGTGCTAGTAGACAAGTCTCTGAAGGGATGGAAGGAGATT
GAGTACGAGGTGGTGAGAGACGCCTATGGCAACTGTGTCACGGTGTGTAACATGGAGAAC
TTGGACCCACTGGGCATCCACACTGGTGAGTCCATAGTGGTGGCCCCTAGCCAGACACTG
AATGACAGGGAGTATCAGCTCCTGAGGCAGACAGCTATCAAGGTGACCCAGCACCTGGGA
ATTGTTGGGGAGTGCAATGTGCAGTATGCCTTGAACCCTGAGTCTGAGCAGTATTACATC
ATTGAAGTGAATGCCAGGCTCTCTCGCAGCTCTGCCCTGGCCAGTAAGGCCACAGGTTAT
CCACTGGCTTATGTGGCAGCCAAGCTAGCATTGGGCATCCCTTTGCCTGAGCTCAGGAAC
TCTGTGACAGGGGGTACAGCAGCCTTTGAACCCAGCGTGGATTATTGTGTGGTGAAGATT
CCTCGATGGGACCTTAGCAAGTTCCTGCGAGTCAGCACAAAGATTGGGAGCTGCATGAAG
AGCGTTGGTGAAGTCATGGGCATTGGGCGTTCATTTGAGGAGGCCTTCCAGAAGGCCCTG
CGCATGGTGGATGAGAACTGTGTGGGCTTTGATCACACAGTGAAACCAGTCAGCGATATG
GAGTTGGAGACTCCAACAGATAAGCGGATTTTTGTGGTGGCAGCTGCTTTGTGGGCTGGT
TATTCAGTGGACCGCCTGTATGAGCTCACACGCATCGACCGCTGGTTCCTGCACCGAATG
AAGCGTATCATCGCACATGCCCAGCTGCTAGAACAACACCGTGGACAGCCTTTGCCGCCA
GACCTGCTGCAACAGGCCAAGTGTCTTGGCTTCTCAGACAAACAGATTGCCCTTGCAGTT
CTGAGCACAGAGCTGGCTGTTCGCAAGCTGCGTCAGGAACTGGGGATCTGTCCAGCAGTG
AAACAGATTGACACAGTTGCAGCTGAGTGGCCAGCCCAGACAAATTACCTATACCTAACG
TATTGGGGCACCACCCATGACCTCACCTTTCGAACACCTCATGTCCTAGTCCTTGGCTCT
GGCGTCTACCGTATTGGCTCCAGTGTTGAGTTTGACTGGTGTGCTGTAGGCTGCATCCAG
CAGCTCCGAAAGATGGGATATAAGACCATCATGGTGAACTATAACCCAGAGACAGTCAGC
ACCGACTATGACATGTGTGATCGACTCTACTTTGATGAGATCTCTTTTGAGGTGGTGATG
GACATCTATGAGCTCGAGAACCCTGAAGGTGTGATCCTATCCATGGGTGGACAGCTGCCC
AACAACATGGCCATGGCGTTGCATCGGCAGCAGTGCCGGGTGCTGGGCACCTCCCCTGAA
GCCATTGACTCGGCTGAGAACCGTTTCAAGTTTTCCCGGCTCCTTGACACCATTGGTATC
AGCCAGCCTCAGTGGAGGGAGCTCAGTGACCTCGAGTCTGCTCGCCAATTCTGCCAGACC
GTGGGGTACCCCTGTGTGGTGCGCCCCTCCTATGTGCTGAGCGGTGCTGCTATGAATGTG
GCCTACGCGGATGGAGACCTGGAGCGCTTCCTGAGCAGCGCAGCAGCCGTCTCCAAAGAG
CATCCCGTGGTCATCTCCAAGTTCATCCAGGAGGCTAAGGAGATTGACGTGGATGCCGTG
GCCTCTGATGGTGTGGTGGCAGCCATCGCCATCTCTGAGCATGTGGAGAATGCAGGTGTG
CATTCAGGTGATGCGACGCTGGTGACCCCCCCACAAGATATCACTGCCAAAACCCTGGAG
CGGATCAAAGCCATTGTGCATGCTGTGGGCCAGGAGCTACAGGTCACAGGACCCTTCAAT
CTGCAGCTCATTGCCAAGGATGACCAGCTGAAAGTTATTGAATGCAACGTACGTGTCTCT
CGCTCCTTCCCCTTCGTTTCCAAGACACTGGGTGTGGACCTAGTAGCCTTGGCCACGCGG
GTCATCATGGGGGAAGAAGTGGAACCTGTGGGGCTAATGACTGGTTCTGGAGTCGTGGGA
GTAAAGGTGCCTCAGTTCTCCTTCTCCCGCTTGGCGGGTGCTGACGTGGTGTTGGGTGTG
GAAATGACCAGTACTGGGGAGGTGGCCGGCTTTGGGGAGAGCCGCTGTGAGGCATACCTC
AAGGCCATGCTAAGCACTGGCTTTAAGATCCCCAAGAAGAATATCCTGCTGACCATTGGC
AGCTATAAGAACAAAAGCGAGCTGCTCCCAACTGTGCGGCTACTGGAGAGCCTGGGCTAC
AGCCTCTATGCCAGTCTCGGCACAGCTGACTTCTACACTGAGCATGGCGTCAAGGTAACA
GCTGTGGACTGGCACTTTGAGGAGGCTGTGGATGGTGAGTGCCCACCACAGCGGAGCATC
CTGGAGCAGCTAGCTGAGAAAAACTTTGAGCTGGTGATTAACCTGTCAATGCGTGGAGCT
GGGGGCCGGCGTCTCTCCTCCTTTGTCACCAAGGGCTACCGCACCCGACGCTTGGCCGCT
GACTTCTCCGTGCCCCTAATCATCGATATCAAGTGCACCAAACTCTTTGTGGAGGCCCTA
GGCCAGATCGGGCCAGCCCCTCCTTTGAAGGTGCATGTTGACTGTATGACCTCCCAAAAG
CTTGTGCGACTGCCGGGATTGATTGATGTCCATGTGCACCTGCGGGAACCAGGTGGGACA
CATAAGGAGGACTTTGCTTCAGGCACAGCCGCTGCCCTGGCTGGGGGTATCACCATGGTG
TGTGCCATGCCTAATACCCGGCCCCCCATCATTGACGGCCCTGCTCTGGCCCTGGCCCAG
AAGCTGGCAGAGGCTGGCGCCCGGTGCGACTTTGCGCTATTCCTTGGGGCCTCGTCTGAA
AATGCAGGAACCTTGGGCACCGTGGCCGGGTCTGCAGCCGGGCTGAAGCTTTACCTCAAT
GAGACCTTCTCTGAGCTGCGGCTGGACAGCGTGGTCCAGTGGATGGAGCATTTCGAGACA
TGGCCCTCCCACCTCCCCATTGTGGCTCACGCAGAGCAGCAAACCGTGGCTGCTGTCCTC
ATGGTGGCTCAGCTCACTCAGCGCTCAGTGCACATATGTCACGTGGCACGGAAGGAGGAG
ATCCTGCTAATTAAAGCTGCAAAGGCACGGGGCTTGCCAGTGACCTGCGAGGTGGCTCCC
CACCACCTGTTCCTAAGCCATGATGACCTGGAGCGCCTGGGGCCTGGGAAGGGGGAGGTC
CGGCCTGAGCTTGGCTCCCGCCAGGATGTGGAAGCCCTGTGGGAGGACATGGCTGTCATC
GACTGCTTTGCCTCAGACCATGCTCCCCATACCTTGGAGGAGAAGTGTGGGTCCAGGCCC
CCACCTGGGTTCCCAGGGTTAGAGACCATGCTGCCACTACTCCTGACGGCTGTAAGCGAG
GGCCGGCTCAGCCTGGACGACCTGCTGCAGCGATTGCACCACAATCCTCGGCGCATCTTT
CACCTGCCCCCGCAGGAGGACACCTATGTGGAGGTGGATCTGGAGCATGAGTGGACAATT
CCCAGCCACATGCCCTTCTCCAAGGCCCACTGGACACCTTTTGAAGGGCAGAAAGTGAAG
GGCACCGTCCGCCGTGTGGTCCTGCGAGGGGAGGTTGCCTATATCGATGGGCAGGTTCTG
GTACCCCCGGGCTATGGACAGGATGTACGGAAGTGGCCACAGGGGGCTGTTCCTCAGCTC
CCACCCTCAGCCCCTGCCACTAGTGAGATGACCACGACACCTGAAAGACCCCGCCGTGGC
ATCCCAGGGCTTCCTGATGGCCGCTTCCATCTGCCGCCCCGAATCCATCGAGCCTCCGAC
CCAGGTTTGCCAGCTGAGGAGCCAAAGGAGAAGTCCTCTCGGAAGGTAGCCGAGCCAGAG
CTGATGGGAACCCCTGATGGCACCTGCTACCCTCCACCACCAGTACCGAGACAGGCATCT
CCCCAGAACCTGGGGACCCCTGGCTTGCTGCACCCCCAGACCTCACCCCTGCTGCACTCA
TTAGTGGGCCAACATATCCTGTCCGTCCAGCAGTTCACCAAGGATCAGATGTCTCACCTG
TTCAATGTGGCACACACACTGCGTATGATGGTGCAGAAGGAGCGGAGCCTCGACATCCTG
AAGGGGAAGGTCATGGCCTCCATGTTCTATGAAGTGAGCACACGGACCAGCAGCTCCTTT
GCAGCAGCCATGGCCCGGCTGGGAGGTGCTGTGCTCAGCTTCTCGGAAGCCACATCGTCC
GTCCAGAAGGGCGAATCCCTGGCTGACTCCGTGCAGACCATGAGCTGCTATGCCGACGTC
GTCGTGCTCCGGCACCCCCAGCCTGGAGCAGTGGAGCTGGCCGCCAAGCACTGCCGGAGG
CCAGTGATCAATGCTGGGGATGGGGTCGGAGAGCACCCCACCCAGGCCCTGCTGGACATC
TTCACCATCCGTGAGGAGCTGGGAACTGTCAATGGCATGACGATCACGATGGTGGGTGAC
CTGAAGCACGGACGCACAGTACATTCCCTGGCCTGCCTGCTCACCCAGTATCGTGTCAGC
CTGCGCTACGTGGCACCTCCCAGCCTGCGCATGCCACCCACTGTGCGGGCCTTCGTGGCC
TCCCGCGGCACCAAGCAGGAGGAATTCGAGAGCATTGAGGAGGCGCTGCCTGACACTGAT
GTGCTCTACATGACTCGAATCCAGAAGGAACGATTTGGCTCTACCCAGGAGTACGAAGCT
TGCTTTGGTCAGTTCATCCTCACTCCCCACATCATGACCCGGGCCAAGAAGAAGATGGTG
GTGATGCACCCGATGCCCCGTGTCAACGAGATAAGCGTGGAAGTGGACTCGGATCCCCGC
GCAGCCTACTTCCGCCAGGCTGAGAACGGCATGTACATCCGCATGGCTCTGTTAGCCACC
GTGCTGGGCCGTTTCTAG
|
| Protein Properties |
|---|
| Number of Residues
| 2225 |
| Molecular Weight
| 242981.73 |
| Theoretical pI
| 6.451 |
| Pfam Domain Function
|
|
| Signals
|
Not Available
|
|
Transmembrane Regions
|
Not Available
|
| Protein Sequence
|
>CAD protein
MAALVLEDGSVLRGQPFGAAVSTAGEVVFQTGMVGYPEALTDPSYKAQILVLTYPLIGNY
GIPPDEMDEFGLCKWFESSGIHVAALVVGECCPTPSHWSATRTLHEWLQQHGIPGLQGVD
TRELTKKLREQGSLLGKLVQNGTEPSSLPFLDPNARPLVPEVSIKTPRVFNTGGAPRILA
LDCGLKYNQIRCLCQRGAEVTVVPWDHALDSQEYEGLFLSNGPGDPASYPSVVSTLSRVL
SEPNPRPVFGICLGHQLLALAIGAKTYKMRYGNRGHNQPCLLVGSGRCFLTSQNHGFAVE
TDSLPADWAPLFTNANDGSNEGIVHNSLPFFSVQFHPEHQAGPSDMELLFDIFLETVKEA
TAGNPGGQTVRERLTERLCPPGIPTPGSGLPPPRKVLILGSGGLSIGQAGEFDYSGSQAI
KALKEENIQTLLINPNIATVQTSQGLADKVYFLPITPHYVTQVIRNERPDGVLLTFGGQT
ALNCGVELTKAGVLARYGVRVLGTPVETIELTEDRRAFAARMAEIGEHVAPSEAANSLEQ
AQAAAERLGYPVLVRAAFALGGLGSGFASNREELSALVAPAFAHTSQVLVDKSLKGWKEI
EYEVVRDAYGNCVTVCNMENLDPLGIHTGESIVVAPSQTLNDREYQLLRQTAIKVTQHLG
IVGECNVQYALNPESEQYYIIEVNARLSRSSALASKATGYPLAYVAAKLALGIPLPELRN
SVTGGTAAFEPSVDYCVVKIPRWDLSKFLRVSTKIGSCMKSVGEVMGIGRSFEEAFQKAL
RMVDENCVGFDHTVKPVSDMELETPTDKRIFVVAAALWAGYSVDRLYELTRIDRWFLHRM
KRIIAHAQLLEQHRGQPLPPDLLQQAKCLGFSDKQIALAVLSTELAVRKLRQELGICPAV
KQIDTVAAEWPAQTNYLYLTYWGTTHDLTFRTPHVLVLGSGVYRIGSSVEFDWCAVGCIQ
QLRKMGYKTIMVNYNPETVSTDYDMCDRLYFDEISFEVVMDIYELENPEGVILSMGGQLP
NNMAMALHRQQCRVLGTSPEAIDSAENRFKFSRLLDTIGISQPQWRELSDLESARQFCQT
VGYPCVVRPSYVLSGAAMNVAYTDGDLERFLSSAAAVSKEHPVVISKFIQEAKEIDVDAV
ASDGVVAAIAISEHVENAGVHSGDATLVTPPQDITAKTLERIKAIVHAVGQELQVTGPFN
LQLIAKDDQLKVIECNVRVSRSFPFVSKTLGVDLVALATRVIMGEEVEPVGLMTGSGVVG
VKVPQFSFSRLAGADVVLGVEMTSTGEVAGFGESRCEAYLKAMLSTGFKIPKKNILLTIG
SYKNKSELLPTVRLLESLGYSLYASLGTADFYTEHGVKVTAVDWHFEEAVDGECPPQRSI
LEQLAEKNFELVINLSMRGAGGRRLSSFVTKGYRTRRLAADFSVPLIIDIKCTKLFVEAL
GQIGPAPPLKVHVDCMTSQKLVRLPGLIDVHVHLREPGGTHKEDFASGTAAALAGGITMV
CAMPNTRPPIIDAPALALAQKLAEAGARCDFALFLGASSENAGTLGTVAGSAAGLKLYLN
ETFSELRLDSVVQWMEHFETWPSHLPIVAHAEQQTVAAVLMVAQLTQRSVHICHVARKEE
ILLIKAAKARGLPVTCEVAPHHLFLSHDDLERLGPGKGEVRPELGSRQDVEALWENMAVI
DCFASDHAPHTLEEKCGSRPPPGFPGLETMLPLLLTAVSEGRLSLDDLLQRLHHNPRRIF
HLPPQEDTYVEVDLEHEWTIPSHMPFSKAHWTPFEGQKVKGTVRRVVLRGEVAYIDGQVL
VPPGYGQDVRKWPQGAVPQLPPSAPATSEMTTTPERPRRGIPGLPDGRFHLPPRIHRASD
PGLPAEEPKEKSSRKVAEPELMGTPDGTCYPPPPVPRQASPQNLGTPGLLHPQTSPLLHS
LVGQHILSVQQFTKDQMSHLFNVAHTLRMMVQKERSLDILKGKVMASMFYEVSTRTSSSF
AAAMARLGGAVLSFSEATSSVQKGESLADSVQTMSCYADVVVLRHPQPGAVELAAKHCRR
PVINAGDGVGEHPTQALLDIFTIREELGTVNGMTITMVGDLKHGRTVHSLACLLTQYRVS
LRYVAPPSLRMPPTVRAFVASRGTKQEEFESIEEALPDTDVLYMTRIQKERFGSTQEYEA
CFGQFILTPHIMTRAKKKMVVMHPMPRVNEISVEVDSDPRAAYFRQAENGMYIRMALLAT
VLGRF
|
| External Links |
|---|
| GenBank ID Protein
| 1228049 |
| UniProtKB/Swiss-Prot ID
| P27708 |
| UniProtKB/Swiss-Prot Entry Name
| PYR1_HUMAN |
| PDB IDs
|
Not Available |
| GenBank Gene ID
| D78586 |
| GeneCard ID
| CAD |
| GenAtlas ID
| CAD |
| HGNC ID
| HGNC:1424 |
| References |
|---|
| General References
| Not Available |