| Identification |
|---|
| HMDB Protein ID
| CDBP01845 |
| Secondary Accession Numbers
| Not Available |
| Name
| Voltage-dependent L-type calcium channel subunit alpha-1C |
| Description
| Not Available |
| Synonyms
|
- Calcium channel, L type, alpha-1 polypeptide, isoform 1, cardiac muscle
- Voltage-gated calcium channel subunit alpha Cav1.2
|
| Gene Name
| CACNA1C |
| Protein Type
| Transporter |
| Biological Properties |
|---|
| General Function
| Involved in ion channel activity |
| Specific Function
| Voltage-sensitive calcium channels (VSCC) mediate the entry of calcium ions into excitable cells and are also involved in a variety of calcium-dependent processes, including muscle contraction, hormone or neurotransmitter release, gene expression, cell motility, cell division and cell death. The isoform alpha-1C gives rise to L-type calcium currents. Long-lasting (L-type) calcium channels belong to the 'high-voltage activated' (HVA) group. They are blocked by dihydropyridines (DHP), phenylalkylamines, benzothiazepines, and by omega-agatoxin-IIIA (omega-Aga-IIIA). They are however insensitive to omega-conotoxin- GVIA (omega-CTx-GVIA) and omega-agatoxin-IVA (omega-Aga-IVA). Calcium channels containing the alpha-1C subunit play an important role in excitation-contraction coupling in the heart. The various isoforms display marked differences in the sensitivity to DHP compounds. Binding of calmodulin or CABP1 at the same regulatory sites results in an opposit effects on the channel function |
| GO Classification
|
| Component |
| membrane |
| cell part |
| membrane part |
| ion channel complex |
| cation channel complex |
| macromolecular complex |
| intrinsic to membrane |
| protein complex |
| integral to membrane |
| calcium channel complex |
| voltage-gated calcium channel complex |
| Function |
| ion transmembrane transporter activity |
| transporter activity |
| ion channel activity |
| cation channel activity |
| calcium channel activity |
| voltage-gated calcium channel activity |
| transmembrane transporter activity |
| substrate-specific transmembrane transporter activity |
| Process |
| di-, tri-valent inorganic cation transport |
| divalent metal ion transport |
| calcium ion transport |
| establishment of localization |
| transport |
| transmembrane transport |
| ion transport |
| cation transport |
|
| Cellular Location
|
- Cell membrane
- Membrane
- Multi-pass membrane protein
|
| Pathways
|
| Name | SMPDB/Pathwhiz | KEGG | | Muscle/Heart Contraction | 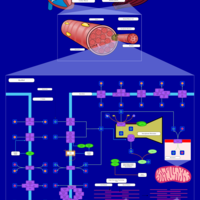 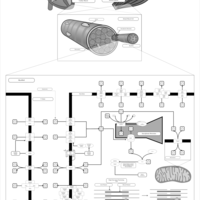  | Not Available | | Acebutolol Action Pathway | 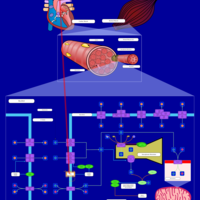 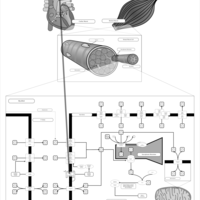  | Not Available | | Alprenolol Action Pathway | 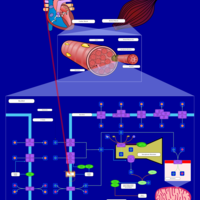 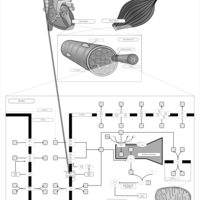  | Not Available | | Atenolol Action Pathway | 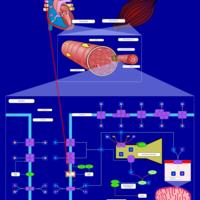   | Not Available | | Betaxolol Action Pathway | 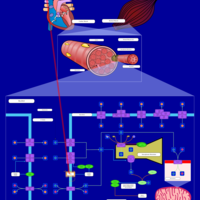   | Not Available |
|
| Gene Properties |
|---|
| Chromosome Location
| Chromosome:1 |
| Locus
| 12p13.3 |
| SNPs
| CACNA1C |
| Gene Sequence
|
>6666 bp
ATGGTCAATGAGAATACGAGGATGTACATTCCAGAGGAAAACCACCAAGGTTCCAACTAT
GGGAGCCCACGCCCCGCCCATGCCAACATGAATGCCAATGCGGCAGCGGGGCTGGCCCCT
GAGCACATCCCCACCCCGGGGGCTGCCCTGTCGTGGCAGGCGGCCATCGACGCAGCCCGG
CAGGCTAAGCTGATGGGCAGCGCTGGCAATGCGACCATCTCCACAGTCAGCTCCACGCAG
CGGAAGCGGCAGCAATATGGGAAACCCAAGAAGCAGGGCAGCACCACGGCCACACGCCCG
CCCCGAGCCCTGCTCTGCCTGACCCTGAAGAACCCCATCCGGAGGGCCTGCATCAGCATT
GTCGAATGGAAACCATTTGAAATAATTATTTTACTGACTATTTTTGCCAATTGTGTGGCC
TTAGCGATCTATATTCCCTTTCCAGAAGATGATTCCAACGCCACCAATTCCAACCTGGAA
CGAGTGGAATATCTCTTTCTCATAATTTTTACGGTGGAAGCGTTTTTAAAAGTAATCGCC
TATGGACTCCTCTTTCACCCCAATGCCTACCTCCGCAACGGCTGGAACCTACTAGATTTT
ATAATTGTGGTTGTGGGGCTTTTTAGTGCAATTTTAGAACAAGCAACCAAAGCAGATGGG
GCAAACGCTCTCGGAGGGAAAGGGGCCGGATTTGATGTGAAGGCGCTGAGGGCCTTCCGC
GTGCTGCGCCCCCTGCGGCTGGTGTCCGGAGTCCCAAGTCTCCAGGTGGTCCTGAATTCC
ATCATCAAGGCCATGGTCCCCCTGCTGCACATCGCCCTGCTTGTGCTGTTTGTCATCATC
ATCTACGCCATCATCGGCTTGGAGCTCTTCATGGGGAAGATGCACAAGACCTGCTACAAC
CAGGAGGGCATAGCAGATGTTCCAGCAGAAGATGACCCTTCCCCTTGTGCGCTGGAAACG
GGCCACGGGCGGCAGTGCCAGAACGGCACGGTGTGCAAGCCCGGCTGGGATGGTCCCAAG
CACGGCATCACCAACTTTGACAACTTTGCCTTCGCCATGCTCACGGTGTTCCAGTGCATC
ACCATGGAGGGCTGGACGGACGTGCTGTACTGGGTCAATGATGCCGTAGGAAGGGACTGG
CCCTGGATCTATTTTGTTACACTAATCATCATAGGGTCATTTTTTGTACTTAACTTGGTT
CTCGGTGTGCTTAGCGGAGAGTTTTCCAAAGAGAGGGAGAAGGCCAAGGCCCGGGGAGAT
TTCCAGAAGCTGCGGGAGAAGCAGCAGCTAGAAGAGGATCTCAAAGGCTACCTGGATTGG
ATCACTCAGGCCGAAGACATCGATCCTGAGAATGAGGACGAAGGCATGGATGAGGAGAAG
CCCCGAAACATGAGCATGCCCACCAGTGAGACCGAGTCCGTCAACACCGAAAACGTGGCT
GGAGGTGACATCGAGGGAGAAAACTGCGGGGCCAGGCTGGCCCACCGGATCTCCAAGTCA
AAGTTCAGCCGCTACTGGCGCCGGTGGAATCGGTTCTGCAGAAGGAAGTGCCGCGCCGCA
GTCAAGTCTAATGTCTTCTACTGGCTGGTGATTTTCCTGGTGTTCCTCAACACGCTCACC
ATTGCCTCTGAGCACTACAACCAGCCCAACTGGCTCACAGAAGTCCAAGACACGGCAAAC
AAGGCCCTGCTGGCCCTGTTCACGGCAGAGATGCTCCTGAAGATGTACAGCCTGGGCCTG
CAGGCCTACTTCGTGTCCCTCTTCAACCGCTTTGACTGCTTCGTCGTGTGTGGCGGCATC
CTGGAGACCATCCTGGTGGAGACCAAGATCATGTCCCCACTGGGCATCTCCGTGCTCAGA
TGCGTCCGGCTGCTGAGGATTTTCAAGATCACGAGGTACTGGAACTCCTTGAGCAACCTG
GTGGCATCCTTGCTGAACTCTGTGCGCTCCATCGCCTCCCTGCTCCTTCTCCTCTTCCTC
TTCATCATCATCTTCTCCCTCCTGGGGATGCAGCTCTTTGGAGGAAAGTTCAACTTTGAT
GAGATGCAGACCCGGAGGAGCACATTCGATAACTTCCCCCAGTCCCTCCTCACTGTGTTT
CAGATCCTGACCGGGGAGGACTGGAATTCGGTGATGTATGATGGGATCATGGCTTATGGC
GGCCCCTCTTTTCCAGGGATGTTAGTCTGTATTTACTTCATCATCCTCTTCATCTGTGGA
AACTATATCCTACTGAATGTGTTCTTGGCCATTGCTGTGGACAACCTGGCTGATGCTGAG
AGCCTCACATCTGCCCAAAAGGAGGAGGAAGAGGAGAAGGAGAGAAAGAAGCTGGCCAGG
ACTGCCAGCCCAGAGAAGAAACAAGAGTTGGTGGAGAAGCCGGCAGTGGGGGAATCCAAG
GAGGAGAAGATTGAGCTGAAATCCATCACGGCTGACGGAGAGTCTCCACCCGCCACCAAG
ATCAACATGGATGACCTCCAGCCCAATGAAAATGAGGATAAGAGCCCCTACCCCAACCCA
GAAACTACAGGAGAAGAGGATGAGGAGGAGCCAGAGATGCCTGTCGGCCCTCGCCCACGA
CCACTCTCTGAGCTTCACCTTAAGGAAAAGGCAGTGCCCATGCCAGAAGCCAGCGCGTTT
TTCATCTTCAGCTCTAACAACAGGTTTCGCCTCCAGTGCCACCGCATTGTCAATGACACG
ATCTTCACCAACCTGATCCTCTTCTTCATTCTGCTCAGCAGCATTTCCCTGGCTGCTGAG
GACCCGGTCCAGCACACCTCCTTCAGGAACCATATTCTGTTTTATTTTGATATTGTTTTT
ACCACCATTTTCACCATTGAAATTGCTCTGAAGATCCTAGGCAATGCAGACTATGTCTTC
ACTAGTATCTTTACATTAGAAATTATCCTTAAGATGACTGCTTATGGGGCTTTCTTGCAC
AAGGGTTCTTTCTGCCGGAACTACTTCAACATCCTGGACCTGCTGGTGGTCAGCGTGTCC
CTCATCTCCTTTGGCATCCAGTCCAGTGCAATCAATGTCGTGAAGATCTTGCGAGTCCTG
CGAGTACTCAGGCCCCTGAGGGCCATCAACAGGGCCAAGGGGCTAAAGCATGTGGTTCAG
TGTGTGTTTGTCGCCATCCGGACCATCGGGAACATCGTGATTGTCACCACCCTGCTGCAG
TTCATGTTTGCCTGCATCGGGGTCCAGCTCTTCAAGGGAAAGCTGTACACCTGTTCAGAC
AGTTCCAAGCAGACAGAGGCGGAATGCAAGGGCAACTACATCACGTACAAAGACGGGGAG
GTTGACCACCCCATCATCCAACCCCGCAGCTGGGAGAACAGCAAGTTTGACTTTGACAAT
GTTCTGGCAGCCATGATGGCCCTCTTCACCGTCTCCACCTTCGAAGGGTGGCCAGAGCTG
CTGTACCGCTCCATCGACTCCCACACGGAAGACAAGGGCCCCATCTACAACTACCGTGTG
GAGATCTCCATCTTCTTCATCATCTACATCATCATCATCGCCTTCTTCATGATGAACATC
TTCGTGGGCTTCGTCATCGTCACCTTTCAGGAGCAGGGGGAGCAGGAGTACAAGAACTGT
GAGCTGGACAAGAACCAGCGACAGTGCGTGGAATACGCCCTCAAGGCCCGGCCCCTGCGG
AGGTACATCCCCAAGAACCAGCACCAGTACAAAGTGTGGTACGTGGTCAACTCCACCTAC
TTCGAGTACCTGATGTTCGTCCTCATCCTGCTCAACACCATCTGCCTGGCCATGCAGCAC
TACGGCCAGAGCTGCCTGTTCAAAATCGCCATGAACATCCTCAACATGCTCTTCACTGGC
CTCTTCACCGTGGAGATGATCCTGAAGCTCATTGCCTTCAAACCCAAGGGTTACTTTAGT
GATCCCTGGAATGTTTTTGACTTCCTCATCGTAATTGGCAGCATAATTGACGTCATTCTC
AGTGAGACTAATCACTATTTCTGTGATGCATGGAATACATTTGACGCCTTGATTGTTGTG
GGTAGCATTGTTGATATAGCAATCACCGAGGTAAACCCAGCTGAACATACCCAATGCTCT
CCCTCTATGAACGCAGAGGAAAACTCCCGCATCTCCATCACCTTCTTCCGCCTGTTCCGG
GTCATGCGTCTGGTGAAGCTGCTGAGCCGTGGGGAGGGCATCCGGACGCTGCTGTGGACC
TTCATCAAGTCCTTCCAGGCCCTGCCCTATGTGGCCCTCCTGATCGTGATGCTGTTCTTC
ATCTACGCGGTGATCGGGATGCAGGTGTTTGGGAAAATTGCCCTGAATGATACCACAGAG
ATCAACCGGAACAACAACTTTCAGACCTTCCCCCAGGCCGTGCTGCTCCTCTTCAGGTGT
GCCACCGGGGAGGCCTGGCAGGACATCATGCTGGCCTGCATGCCAGGCAAGAAGTGTGCC
CCAGAGTCCGAGCCCAGCAACAGCACGGAGGGTGAAACACCCTGTGGTAGCAGCTTTGCT
GTCTTCTACTTCATCAGCTTCTACATGCTCTGTGCCTTCCTGATCATCAACCTCTTTGTA
GCTGTCATCATGGACAACTTTGACTACCTGACAAGGGACTGGTCCATCCTTGGTCCCCAC
CACCTGGATGAGTTTAAAAGAATCTGGGCAGAGTATGACCCTGAAGCCAAGGGTCGTATC
AAACACCTGGATGTGGTGACCCTCCTCCGGCGGATTCAGCCGCCACTAGGTTTTGGGAAG
CTGTGCCCTCACCGCGTGGCTTGCAAACGCCTGGTCTCCATGAACATGCCTCTGAACAGC
GACGGGACAGTCATGTTCAATGCCACCCTGTTTGCCCTGGTCAGGACGGCCCTGAGGATC
AAAACAGAAGGGAACCTAGAACAAGCCAATGAGGAGCTGCGGGCGATCATCAAGAAGATC
TGGAAGCGGACCAGCATGAAGCTGCTGGACCAGGTGGTGCCCCCTGCAGGTGATGATGAG
GTCACCGTTGGCAAGTTCTACGCCACGTTCCTGATCCAGGAGTACTTCCGGAAGTTCAAG
AAGCGCAAAGAGCAGGGCCTTGTGGGCAAGCCCTCCCAGAGGAACGCGCTGTCTCTGCAG
GCTGGCTTGCGCACACTGCATGACATCGGGCCTGAGATCCGACGGGCCATCTCTGGAGAT
CTCACCGCTGAGGAGGAGCTGGACAAGGCCATGAAGGAGGCTGTGTCCGCTGCTTCTGAA
GATGACATCTTCAGGAGGGCCGGTGGCCTGTTCGGCAACCACGTCAGCTACTACCAAAGC
GACGGCCGGAGCGCCTTCCCCCAGACCTTCACCACTCAGCGCCCGCTGCACATCAACAAG
GCGGGCAGCAGCCAGGGCGACACTGAGTCGCCATCCCACGAGAAGCTGGTGGACTCCACC
TTCACCCCGAGCAGCTACTCGTCCACCGGCTCCAACGCCAACATCAACAACGCCAACAAC
ACCGCCCTGGGTCGCCTCCCTCGCCCCGCCGGCTACCCCAGCACGGTCAGCACTGTGGAG
GGCCACGGGCCCCCCTTGTCCCCTGCCATCCGGGTGCAGGAGGTGGCGTGGAAGCTCAGC
TCCAACAGGGAAAGGCACGTTCCGATGTGTGAGGATCTGGAGCTCAGGAGGGATTCAGGC
TCAGCAGGGACTCAGGCTCACTGCCTTCTGCTCAGGAAAGCAAACCCCTCTAGGTGCCAC
TCCCGGGAGAGCCAGGCAGCCATGGCGGGTCAGGAGGAGACGTCTCAGGATGAGACCTAT
GAAGTGAAGATGAACCATGACACGGAGGCCTGCAGTGAGCCCAGCCTGCTCTCCACAGAG
ATGCTCTCCTACCAGGATGACGAAAATCGGCAACTGACGCTCCCAGAGGAGGACAAGAGG
GACATCCGGCAATCTCCGAAGAGGGGTTTCCTCCGCTCTGCCTCACTAGGTCGAAGGGCC
TCCTTCCACCTGGAATGTCTGAAGCGACAGAAGGACCGAGGGGGAGACATCTCTCAGAAG
ACAGTCCTGCCCTTGCATCTGGTTCATCATCAGGCATTGGCAGTGGCAGGCCTGAGCCCC
CTCCTCCAGAGAAGCCATTCCCCTGCCTCATTCCCTAGGCCTTTTGCCACCCCACCAGCC
ACACCTGGCAGCCGAGGCTGGCCCCCACAGCCCGTCCCCACCCTGCGGCTTGAGGGGGTC
GAGTCCAGTGAGAAACTCAACAGCAGCTTCCCATCCATCCACTGCGGCTCCTGGGCTGAG
ACCACCCCCGGTGGCGGGGGCAGCAGCGCCGCCCGGAGAGTCCGGCCCGTCTCCCTCATG
GTGCCCAGCCAGGCTGGGGCCCCAGGGAGGCAGTTCCACGGCAGTGCCAGCAGCCTGGTG
GAAGCGGTCTTGATTTCAGAAGGACTGGGGCAGTTTGCTCAAGATCCCAAGTTCATCGAG
GTCACCACCCAGGAGCTGGCCGACGCCTGCGACATGACCATAGAGGAGATGGAGAGCGCG
GCCGACAACATCCTCAGCGGGGGCGCCCCACAGAGCCCCAATGGCGCCCTCTTACCCTTT
GTGAACTGCAGGGACGCGGGGCAGGACCGAGCCGGGGGCGAAGAGGACGCGGGCTGTGTG
CGCGCGCGGGGTCGACCGAGTGAGGAGGAGCTCCAGGACAGCAGGGTCTACGTCAGCAGC
CTGTAG
|
| Protein Properties |
|---|
| Number of Residues
| 2221 |
| Molecular Weight
| 248974.1 |
| Theoretical pI
| 6.74 |
| Pfam Domain Function
|
|
| Signals
|
|
|
Transmembrane Regions
|
- ["125-143", "161-181", "194-212", "233-251", "271-290", "381-405", "525-543", "559-578", "587-605", "616-634", "654-673", "729-753", "901-919", "936-955", "988-1006", "1014-1032", "1052-1071", "1162-1186", "1240-1258", "1274-1293", "1302-1320", "1373-1391", "1411-1430", "1500-1524"]
|
| Protein Sequence
|
>Voltage-dependent L-type calcium channel subunit alpha-1C
MVNENTRMYIPEENHQGSNYGSPRPAHANMNANAAAGLAPEHIPTPGAALSWQAAIDAAR
QAKLMGSAGNATISTVSSTQRKRQQYGKPKKQGSTTATRPPRALLCLTLKNPIRRACISI
VEWKPFEIIILLTIFANCVALAIYIPFPEDDSNATNSNLERVEYLFLIIFTVEAFLKVIA
YGLLFHPNAYLRNGWNLLDFIIVVVGLFSAILEQATKADGANALGGKGAGFDVKALRAFR
VLRPLRLVSGVPSLQVVLNSIIKAMVPLLHIALLVLFVIIIYAIIGLELFMGKMHKTCYN
QEGIADVPAEDDPSPCALETGHGRQCQNGTVCKPGWDGPKHGITNFDNFAFAMLTVFQCI
TMEGWTDVLYWVNDAVGRDWPWIYFVTLIIIGSFFVLNLVLGVLSGEFSKEREKAKARGD
FQKLREKQQLEEDLKGYLDWITQAEDIDPENEDEGMDEEKPRNMSMPTSETESVNTENVA
GGDIEGENCGARLAHRISKSKFSRYWRRWNRFCRRKCRAAVKSNVFYWLVIFLVFLNTLT
IASEHYNQPNWLTEVQDTANKALLALFTAEMLLKMYSLGLQAYFVSLFNRFDCFVVCGGI
LETILVETKIMSPLGISVLRCVRLLRIFKITRYWNSLSNLVASLLNSVRSIASLLLLLFL
FIIIFSLLGMQLFGGKFNFDEMQTRRSTFDNFPQSLLTVFQILTGEDWNSVMYDGIMAYG
GPSFPGMLVCIYFIILFICGNYILLNVFLAIAVDNLADAESLTSAQKEEEEEKERKKLAR
TASPEKKQELVEKPAVGESKEEKIELKSITADGESPPATKINMDDLQPNENEDKSPYPNP
ETTGEEDEEEPEMPVGPRPRPLSELHLKEKAVPMPEASAFFIFSSNNRFRLQCHRIVNDT
IFTNLILFFILLSSISLAAEDPVQHTSFRNHILFYFDIVFTTIFTIEIALKILGNADYVF
TSIFTLEIILKMTAYGAFLHKGSFCRNYFNILDLLVVSVSLISFGIQSSAINVVKILRVL
RVLRPLRAINRAKGLKHVVQCVFVAIRTIGNIVIVTTLLQFMFACIGVQLFKGKLYTCSD
SSKQTEAECKGNYITYKDGEVDHPIIQPRSWENSKFDFDNVLAAMMALFTVSTFEGWPEL
LYRSIDSHTEDKGPIYNYRVEISIFFIIYIIIIAFFMMNIFVGFVIVTFQEQGEQEYKNC
ELDKNQRQCVEYALKARPLRRYIPKNQHQYKVWYVVNSTYFEYLMFVLILLNTICLAMQH
YGQSCLFKIAMNILNMLFTGLFTVEMILKLIAFKPKGYFSDPWNVFDFLIVIGSIIDVIL
SETNHYFCDAWNTFDALIVVGSIVDIAITEVNPAEHTQCSPSMNAEENSRISITFFRLFR
VMRLVKLLSRGEGIRTLLWTFIKSFQALPYVALLIVMLFFIYAVIGMQVFGKIALNDTTE
INRNNNFQTFPQAVLLLFRCATGEAWQDIMLACMPGKKCAPESEPSNSTEGETPCGSSFA
VFYFISFYMLCAFLIINLFVAVIMDNFDYLTRDWSILGPHHLDEFKRIWAEYDPEAKGRI
KHLDVVTLLRRIQPPLGFGKLCPHRVACKRLVSMNMPLNSDGTVMFNATLFALVRTALRI
KTEGNLEQANEELRAIIKKIWKRTSMKLLDQVVPPAGDDEVTVGKFYATFLIQEYFRKFK
KRKEQGLVGKPSQRNALSLQAGLRTLHDIGPEIRRAISGDLTAEEELDKAMKEAVSAASE
DDIFRRAGGLFGNHVSYYQSDGRSAFPQTFTTQRPLHINKAGSSQGDTESPSHEKLVDST
FTPSSYSSTGSNANINNANNTALGRLPRPAGYPSTVSTVEGHGPPLSPAIRVQEVAWKLS
SNRERHVPMCEDLELRRDSGSAGTQAHCLLLRKANPSRCHSRESQAAMAGQEETSQDETY
EVKMNHDTEACSEPSLLSTEMLSYQDDENRQLTLPEEDKRDIRQSPKRGFLRSASLGRRA
SFHLECLKRQKDRGGDISQKTVLPLHLVHHQALAVAGLSPLLQRSHSPASFPRPFATPPA
TPGSRGWPPQPVPTLRLEGVESSEKLNSSFPSIHCGSWAETTPGGGGSSAARRVRPVSLM
VPSQAGAPGRQFHGSASSLVEAVLISEGLGQFAQDPKFIEVTTQELADACDMTIEEMESA
ADNILSGGAPQSPNGALLPFVNCRDAGQDRAGGEEDAGCVRARGRPSEEELQDSRVYVSS
L
|
| External Links |
|---|
| GenBank ID Protein
| 193788720 |
| UniProtKB/Swiss-Prot ID
| Q13936 |
| UniProtKB/Swiss-Prot Entry Name
| CAC1C_HUMAN |
| PDB IDs
|
|
| GenBank Gene ID
| NM_199460.2 |
| GeneCard ID
| CACNA1C |
| GenAtlas ID
| CACNA1C |
| HGNC ID
| HGNC:1390 |
| References |
|---|
| General References
| Not Available |