| Identification |
|---|
| HMDB Protein ID
| CDBP01482 |
| Secondary Accession Numbers
| Not Available |
| Name
| Alpha-N-acetylglucosaminidase |
| Description
| Not Available |
| Synonyms
|
- Alpha-N-acetylglucosaminidase 77 kDa form
- Alpha-N-acetylglucosaminidase 82 kDa form
- N-acetyl-alpha-glucosaminidase
- NAG
|
| Gene Name
| NAGLU |
| Protein Type
| Enzyme |
| Biological Properties |
|---|
| General Function
| Involved in alpha-N-acetylglucosaminidase activity |
| Specific Function
| Involved in the degradation of heparan sulfate.
|
| GO Classification
|
| Biological Process |
| small molecule metabolic process |
| glycosaminoglycan catabolic process |
| nervous system development |
| carbohydrate metabolic process |
| Cellular Component |
| lysosomal lumen |
| Molecular Function |
| alpha-N-acetylglucosaminidase activity |
|
| Cellular Location
|
- Lysosome
|
| Pathways
|
| Name | SMPDB/Pathwhiz | KEGG | | Glycosaminoglycan degradation | Not Available | 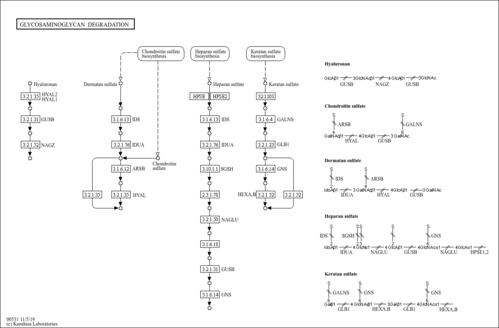 | | Lysosome | Not Available | 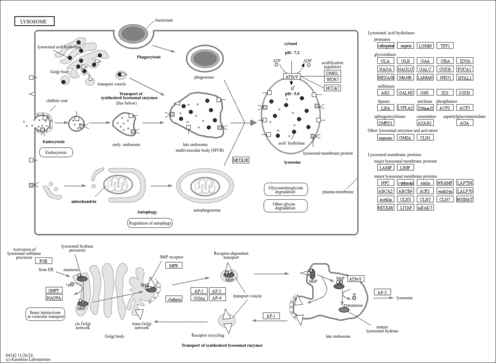 |
|
| Gene Properties |
|---|
| Chromosome Location
| Not Available |
| Locus
| Not Available |
| SNPs
| NAGLU |
| Gene Sequence
|
>2232 bp
ATGGAGGCGGTGGCGGTGGCCGCGGCGGTGGGGGTCCTTCTCCTGGCCGGGGCCGGGGGC
GCGGCAGGCGACGAGGCCCGGGAGGCGGCGGCCGTGCGGGCGCTCGTGGCCCGGCTGCTG
GGGCCAGGCCCCGCGGCCGACTTCTCCGTGTCGGTGGAGCGCGCTCTGGCTGCCAAGCCG
GGCTTGGACACCTACAGCCTGGGCGGCGGCGGCGCGGCGCGCGTGCGGGTGCGCGGCTCC
ACGGGCGTGGCGGCCGCCGCGGGGCTGCACCGCTACCTGCGCGACTTCTGTGGCTGCCAC
GTGGCCTGGTCCGGCTCTCAGCTGCGCCTGCCGCGGCCACTGCCAGCCGTGCCGGGGGAG
CTGACCGAGGCCACGCCCAACAGGTACCGCTATTACCAGAATGTGTGCACGCAAAGCTAC
TCCTTCGTGTGGTGGGACTGGGCCCGCTGGGAGCGAGAGATAGACTGGATGGCGCTGAAT
GGCATCAACCTGGCACTGGCCTGGAGCGGCCAGGAGGCCATCTGGCAGCGGGTGTACCTG
GCCTTGGGCCTGACCCAGGCAGAGATCAATGAGTTCTTTACTGGTCCTGCCTTCCTGGCC
TGGGGGCGAATGGGCAACCTGCACACCTGGGATGGCCCCCTGCCCCCCTCCTGGCACATC
AAGCAGCTTTACCTGCAGCACCGGGTCCTGGACCAGATGCGCTCCTTCGGCATGACCCCA
GTGCTGCCTGCATTCGCGGGGCATGTTCCCGAGGCTGTCACCAGGGTGTTCCCTCAGGTC
AATGTCACGAAGATGGGCAGTTGGGGCCACTTTAACTGTTCCTACTCCTGCTCCTTCCTT
CTGGCTCCGGAAGACCCCATATTCCCCATCATCGGGAGCCTCTTCCTGCGAGAGCTGATC
AAAGAGTTTGGCACAGACCACATCTATGGGGCCGACACTTTCAATGAGATGCAGCCACCT
TCCTCAGAGCCCTCCTACCTTGCCGCAGCCACCACTGCCGTCTATGAGGCCATGACTGCA
GTGGATACTGAGGCTGTGTGGCTGCTCCAAGGCTGGCTCTTCCAGCACCAGCCGCAGTTC
TGGGGGCCCGCCCAGATCAGGGCTGTGCTGGGAGCTGTGCCCCGTGGCCGCCTCCTGGTT
CTGGACCTGTTTGCTGAGAGCCAGCCTGTGTATACCCGCACTGCCTCCTTCCAGGGCCAG
CCCTTCATCTGGTGCATGCTGCACAACTTTGGGGGAAACCATGGTCTTTTTGGAGCCCTA
GAGGCTGTGAACGGAGGCCCAGAAGCTGCCCGCCTCTTCCCCAACTCCACCATGGTAGGC
ACGGGCATGGCCCCCGAGGGCATCAGCCAGAACGAAGTGGTCTATTCCCTCATGGCTGAG
CTGGGCTGGCGAAAGGACCCAGTGCCAGATTTGGCAGCCTGGGTGACCAGCTTTGCCGCC
CGGCGGTATGGGGTCTCCCACCCGGACGCAGGGGCAGCGTGGAGGCTACTGCTCCGGAGT
GTGTACAACTGCTCCGGGGAGGCCTGCAGGGGCCACAATCGTAGCCCGCTGGTCAGGCGG
CCGTCCCTACAGATGAATACCAGCATCTGGTACAACCGATCTGATGTGTTTGAGGCCTGG
CGGCTGCTGCTCACATCTGCTCCCTCCCTGGCCACCAGCCCCGCCTTCCGCTACGACCTG
CTGGACCTCACTCGGCAGGCAGTGCAGGAGCTGGTCAGCTTGTACTATGAGGAGGCAAGA
AGCGCCTACCTGAGCAAGGAGCTGGCCTCCCTGTTGAGGGCTGGAGGCGTCCTGGCCTAT
GAGCTGCTGCCGGCACTGGACGAGGTGCTGGCTAGTGACAGCCGCTTCTTGCTGGGCAGC
TGGCTAGAGCAGGCCCGAGCAGCGGCAGTCAGTGAGGCCGAGGCCGATTTCTACGAGCAG
AACAGCCGCTACCAGCTGACCTTGTGGGGGCCAGAAGGCAACATCCTGGACTATGCCAAC
AAGCAGCTGGCGGGGTTGGTGGCCAACTACTACACCCCTCGCTGGCGGCTTTTCCTGGAG
GCGCTGGTTGACAGTGTGGCCCAGGGCATCCCTTTCCAACAGCACCAGTTTGACAAAAAT
GTCTTCCAACTGGAGCAGGCCTTCGTTCTCAGCAAGCAGAGGTACCCCAGCCAGCCGCGA
GGAGACACTGTGGACCTGGCCAAGAAGATCTTCCTCAAATATTACCCCGGCTGGGTGGCC
GGCTCTTGGTGA
|
| Protein Properties |
|---|
| Number of Residues
| 743 |
| Molecular Weight
| Not Available |
| Theoretical pI
| Not Available |
| Pfam Domain Function
|
|
| Signals
|
Not Available
|
|
Transmembrane Regions
|
Not Available
|
| Protein Sequence
|
>Alpha-N-acetylglucosaminidase
MEAVAVAAAVGVLLLAGAGGAAGDEAREAAAVRALVARLLGPGPAADFSVSVERALAAKP
GLDTYSLGGGGAARVRVRGSTGVAAAAGLHRYLRDFCGCHVAWSGSQLRLPRPLPAVPGE
LTEATPNRYRYYQNVCTQSYSFVWWDWARWEREIDWMALNGINLALAWSGQEAIWQRVYL
ALGLTQAEINEFFTGPAFLAWGRMGNLHTWDGPLPPSWHIKQLYLQHRVLDQMRSFGMTP
VLPAFAGHVPEAVTRVFPQVNVTKMGSWGHFNCSYSCSFLLAPEDPIFPIIGSLFLRELI
KEFGTDHIYGADTFNEMQPPSSEPSYLAAATTAVYEAMTAVDTEAVWLLQGWLFQHQPQF
WGPAQIRAVLGAVPRGRLLVLDLFAESQPVYTRTASFQGQPFIWCMLHNFGGNHGLFGAL
EAVNGGPEAARLFPNSTMVGTGMAPEGISQNEVVYSLMAELGWRKDPVPDLAAWVTSFAA
RRYGVSHPDAGAAWRLLLRSVYNCSGEACRGHNRSPLVRRPSLQMNTSIWYNRSDVFEAW
RLLLTSAPSLATSPAFRYDLLDLTRQAVQELVSLYYEEARSAYLSKELASLLRAGGVLAY
ELLPALDEVLASDSRFLLGSWLEQARAAAVSEAEADFYEQNSRYQLTLWGPEGNILDYAN
KQLAGLVANYYTPRWRLFLEALVDSVAQGIPFQQHQFDKNVFQLEQAFVLSKQRYPSQPR
GDTVDLAKKIFLKYYPGWVAGSW
|
| External Links |
|---|
| GenBank ID Protein
| 1171231 |
| UniProtKB/Swiss-Prot ID
| P54802 |
| UniProtKB/Swiss-Prot Entry Name
| ANAG_HUMAN |
| PDB IDs
|
Not Available |
| GenBank Gene ID
| U43573 |
| GeneCard ID
| NAGLU |
| GenAtlas ID
| NAGLU |
| HGNC ID
| HGNC:7632 |
| References |
|---|
| General References
| Not Available |