| Identification |
|---|
| HMDB Protein ID
| CDBP01410 |
| Secondary Accession Numbers
| Not Available |
| Name
| Insulin receptor |
| Description
| Not Available |
| Synonyms
|
- CD220 antigen
- IR
- Insulin receptor subunit alpha
- Insulin receptor subunit beta
|
| Gene Name
| INSR |
| Protein Type
| Enzyme |
| Biological Properties |
|---|
| General Function
| Involved in transmembrane receptor protein tyrosine kinase activity |
| Specific Function
| This receptor binds insulin and has a tyrosine-protein kinase activity. Isoform Short has a higher affinity for insulin. Mediates the metabolic functions of insulin. Binding to insulin stimulates association of the receptor with downstream mediators including IRS1 and phosphatidylinositol 3'-kinase (PI3K). Can activate PI3K either directly by binding to the p85 regulatory subunit, or indirectly via IRS1. When present in a hybrid receptor with IGF1R, binds IGF1. PubMed:12138094 shows that hybrid receptors composed of IGF1R and INSR isoform Long are activated with a high affinity by IGF1, with low affinity by IGF2 and not significantly activated by insulin, and that hybrid receptors composed of IGF1R and INSR isoform Short are activated by IGF1, IGF2 and insulin. In contrast, PubMed:16831875 shows that hybrid receptors composed of IGF1R and INSR isoform Long and hybrid receptors composed of IGF1R and INSR isoform Short have similar binding characteristics, both bind IGF1 and have a low affinity for insulin |
| GO Classification
|
| Component |
| membrane |
| cell part |
| membrane part |
| intrinsic to membrane |
| integral to membrane |
| Function |
| kinase activity |
| nucleoside binding |
| purine nucleoside binding |
| adenyl nucleotide binding |
| adenyl ribonucleotide binding |
| atp binding |
| protein binding |
| protein kinase activity |
| protein tyrosine kinase activity |
| transmembrane receptor protein tyrosine kinase activity |
| binding |
| catalytic activity |
| transferase activity |
| transferase activity, transferring phosphorus-containing groups |
| Process |
| response to endogenous stimulus |
| response to hormone stimulus |
| response to peptide hormone stimulus |
| protein amino acid phosphorylation |
| signaling |
| signaling pathway |
| cell surface receptor linked signaling pathway |
| phosphorylation |
| phosphorus metabolic process |
| phosphate metabolic process |
| enzyme linked receptor protein signaling pathway |
| transmembrane receptor protein tyrosine kinase signaling pathway |
| response to stimulus |
| metabolic process |
| protein amino acid autophosphorylation |
| cellular metabolic process |
|
| Cellular Location
|
- Membrane
- Single-pass type I membrane protein
|
| Pathways
|
| Name | SMPDB/Pathwhiz | KEGG | | Insulin Signalling | 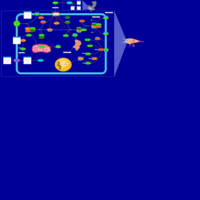 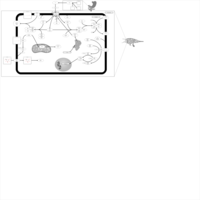 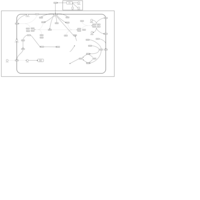 | Not Available | | Leucine Stimulation on Insulin Signaling | 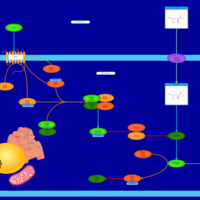  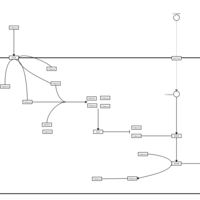 | Not Available |
|
| Gene Properties |
|---|
| Chromosome Location
| Chromosome:1 |
| Locus
| 19p13.3-p13.2 |
| SNPs
| INSR |
| Gene Sequence
|
>4149 bp
ATGGGCACCGGGGGCCGGCGGGGGGCGGCGGCCGCGCCGCTGCTGGTGGCGGTGGCCGCG
CTGCTACTGGGCGCCGCGGGCCACCTGTACCCCGGAGAGGTGTGTCCCGGCATGGATATC
CGGAACAACCTCACTAGGTTGCATGAGCTGGAGAATTGCTCTGTCATCGAAGGACACTTG
CAGATACTCTTGATGTTCAAAACGAGGCCCGAAGATTTCCGAGACCTCAGTTTCCCCAAA
CTCATCATGATCACTGATTACTTGCTGCTCTTCCGGGTCTATGGGCTCGAGAGCCTGAAG
GACCTGTTCCCCAACCTCACGGTCATCCGGGGATCACGACTGTTCTTTAACTACGCGCTG
GTCATCTTCGAGATGGTTCACCTCAAGGAACTCGGCCTCTACAACCTGATGAACATCACC
CGGGGTTCTGTCCGCATCGAGAAGAACAATGAGCTCTGTTACTTGGCCACTATCGACTGG
TCCCGTATCCTGGATTCCGTGGAGGATAATCACATCGTGTTGAACAAAGATGACAACGAG
GAGTGTGGAGACATCTGTCCGGGTACCGCGAAGGGCAAGACCAACTGCCCCGCCACCGTC
ATCAACGGGCAGTTTGTCGAACGATGTTGGACTCATAGTCACTGCCAGAAAGTTTGCCCG
ACCATCTGTAAGTCACACGGCTGCACCGCCGAAGGCCTCTGTTGCCACAGCGAGTGCCTG
GGCAACTGTTCTCAGCCCGACGACCCCACCAAGTGCGTGGCCTGCCGCAACTTCTACCTG
GACGGCAGGTGTGTGGAGACCTGCCCGCCCCCGTACTACCACTTCCAGGACTGGCGCTGT
GTGAACTTCAGCTTCTGCCAGGACCTGCACCACAAATGCAAGAACTCGCGGAGGCAGGGC
TGCCACCAATACGTCATTCACAACAACAAGTGCATCCCTGAGTGTCCCTCCGGGTACACG
ATGAATTCCAGCAACTTGCTGTGCACCCCATGCCTGGGTCCCTGTCCCAAGGTGTGCCAC
CTCCTAGAAGGCGAGAAGACCATCGACTCGGTGACGTCTGCCCAGGAGCTCCGAGGATGC
ACCGTCATCAACGGGAGTCTGATCATCAACATTCGAGGAGGCAACAATCTGGCAGCTGAG
CTAGAAGCCAACCTCGGCCTCATTGAAGAAATTTCAGGGTATCTAAAAATCCGCCGATCC
TACGCTCTGGTGTCACTTTCCTTCTTCCGGAAGTTACGTCTGATTCGAGGAGAGACCTTG
GAAATTGGGAACTACTCCTTCTATGCCTTGGACAACCAGAACCTAAGGCAGCTCTGGGAC
TGGAGCAAACACAACCTCACCACCACTCAGGGGAAACTCTTCTTCCACTATAACCCCAAA
CTCTGCTTGTCAGAAATCCACAAGATGGAAGAAGTTTCAGGAACCAAGGGGCGCCAGGAG
AGAAACGACATTGCCCTGAAGACCAATGGGGACAAGGCATCCTGTGAAAATGAGTTACTT
AAATTTTCTTACATTCGGACATCTTTTGACAAGATCTTGCTGAGATGGGAGCCGTACTGG
CCCCCCGACTTCCGAGACCTCTTGGGGTTCATGCTGTTCTACAAAGAGGCCCCTTATCAG
AATGTGACGGAGTTCGATGGGCAGGATGCGTGTGGTTCCAACAGTTGGACGGTGGTAGAC
ATTGACCCACCCCTGAGGTCCAACGACCCCAAATCACAGAACCACCCAGGGTGGCTGATG
CGGGGTCTCAAGCCCTGGACCCAGTATGCCATCTTTGTGAAGACCCTGGTCACCTTTTCG
GATGAACGCCGGACCTATGGGGCCAAGAGTGACATCATTTATGTCCAGACAGATGCCACC
AACCCCTCTGTGCCCCTGGATCCAATCTCAGTGTCTAACTCATCATCCCAGATTATTCTG
AAGTGGAAACCACCCTCCGACCCCAATGGCAACATCACCCACTACCTGGTTTTCTGGGAG
AGGCAGGCGGAAGACAGTGAGCTGTTCGAGCTGGATTATTGCCTCAAAGGGCTGAAGCTG
CCCTCGAGGACCTGGTCTCCACCATTCGAGTCTGAAGATTCTCAGAAGCACAACCAGAGT
GAGTATGAGGATTCGGCCGGCGAATGCTGCTCCTGTCCAAAGACAGACTCTCAGATCCTG
AAGGAGCTGGAGGAGTCCTCGTTTAGGAAGACGTTTGAGGATTACCTGCACAACGTGGTT
TTCGTCCCCAGAAAAACCTCTTCAGGCACTGGTGCCGAGGACCCTAGGCCATCTCGGAAA
CGCAGGTCCCTTGGCGATGTTGGGAATGTGACGGTGGCCGTGCCCACGGTGGCAGCTTTC
CCCAACACTTCCTCGACCAGCGTGCCCACGAGTCCGGAGGAGCACAGGCCTTTTGAGAAG
GTGGTGAACAAGGAGTCGCTGGTCATCTCCGGCTTGCGACACTTCACGGGCTATCGCATC
GAGCTGCAGGCTTGCAACCAGGACACCCCTGAGGAACGGTGCAGTGTGGCAGCCTACGTC
AGTGCGAGGACCATGCCTGAAGCCAAGGCTGATGACATTGTTGGCCCTGTGACGCATGAA
ATCTTTGAGAACAACGTCGTCCACTTGATGTGGCAGGAGCCGAAGGAGCCCAATGGTCTG
ATCGTGCTGTATGAAGTGAGTTATCGGCGATATGGTGATGAGGAGCTGCATCTCTGCGTC
TCCCGCAAGCACTTCGCTCTGGAACGGGGCTGCAGGCTGCGTGGGCTGTCACCGGGGAAC
TACAGCGTGCGAATCCGGGCCACCTCCCTTGCGGGCAACGGCTCTTGGACGGAACCCACC
TATTTCTACGTGACAGACTATTTAGACGTCCCGTCAAATATTGCAAAAATTATCATCGGC
CCCCTCATCTTTGTCTTTCTCTTCAGTGTTGTGATTGGAAGTATTTATCTATTCCTGAGA
AAGAGGCAGCCAGATGGGCCGCTGGGACCGCTTTACGCTTCTTCAAACCCTGAGTATCTC
AGTGCCAGTGATGTGTTTCCATGCTCTGTGTACGTGCCGGACGAGTGGGAGGTGTCTCGA
GAGAAGATCACCCTCCTTCGAGAGCTGGGGCAGGGCTCCTTCGGCATGGTGTATGAGGGC
AATGCCAGGGACATCATCAAGGGTGAGGCAGAGACCCGCGTGGCGGTGAAGACGGTCAAC
GAGTCAGCCAGTCTCCGAGAGCGGATTGAGTTCCTCAATGAGGCCTCGGTCATGAAGGGC
TTCACCTGCCATCACGTGGTGCGCCTCCTGGGAGTGGTGTCCAAGGGCCAGCCCACGCTG
GTGGTGATGGAGCTGATGGCTCACGGAGACCTGAAGAGCTACCTCCGTTCTCTGCGGCCA
GAGGCTGAGAATAATCCTGGCCGCCCTCCCCCTACCCTTCAAGAGATGATTCAGATGGCG
GCAGAGATTGCTGACGGGATGGCCTACCTGAACGCCAAGAAGTTTGTGCATCGGGACCTG
GCAGCGAGAAACTGCATGGTCGCCCATGATTTTACTGTCAAAATTGGAGACTTTGGAATG
ACCAGAGACATCTATGAAACGGATTACTACCGGAAAGGGGGCAAGGGTCTGCTCCCTGTA
CGGTGGATGGCACCGGAGTCCCTGAAGGATGGGGTCTTCACCACTTCTTCTGACATGTGG
TCCTTTGGCGTGGTCCTTTGGGAAATCACCAGCTTGGCAGAACAGCCTTACCAAGGCCTG
TCTAATGAACAGGTGTTGAAATTTGTCATGGATGGAGGGTATCTGGATCAACCCGACAAC
TGTCCAGAGAGAGTCACTGACCTCATGCGCATGTGCTGGCAATTCAACCCCAAGATGAGG
CCAACCTTCCTGGAGATTGTCAACCTGCTCAAGGACGACCTGCACCCCAGCTTTCCAGAG
GTGTCGTTCTTCCACAGCGAGGAGAACAAGGCTCCCGAGAGTGAGGAGCTGGAGATGGAG
TTTGAGGACATGGAGAATGTGCCCCTGGACCGTTCCTCGCACTGTCAGAGGGAGGAGGCG
GGGGGCCGGGATGGAGGGTCCTCGCTGGGTTTCAAGCGGAGCTACGAGGAACACATCCCT
TACACACACATGAACGGAGGCAAGAAAAACGGGCGGATTCTGACCTTGCCTCGGTCCAAT
CCTTCCTAA
|
| Protein Properties |
|---|
| Number of Residues
| 1382 |
| Molecular Weight
| 156331.5 |
| Theoretical pI
| 6.14 |
| Pfam Domain Function
|
|
| Signals
|
|
|
Transmembrane Regions
|
|
| Protein Sequence
|
>Insulin receptor
MATGGRRGAAAAPLLVAVAALLLGAAGHLYPGEVCPGMDIRNNLTRLHELENCSVIEGHL
QILLMFKTRPEDFRDLSFPKLIMITDYLLLFRVYGLESLKDLFPNLTVIRGSRLFFNYAL
VIFEMVHLKELGLYNLMNITRGSVRIEKNNELCYLATIDWSRILDSVEDNYIVLNKDDNE
ECGDICPGTAKGKTNCPATVINGQFVERCWTHSHCQKVCPTICKSHGCTAEGLCCHSECL
GNCSQPDDPTKCVACRNFYLDGRCVETCPPPYYHFQDWRCVNFSFCQDLHHKCKNSRRQG
CHQYVIHNNKCIPECPSGYTMNSSNLLCTPCLGPCPKVCHLLEGEKTIDSVTSAQELRGC
TVINGSLIINIRGGNNLAAELEANLGLIEEISGYLKIRRSYALVSLSFFRKLRLIRGETL
EIGNYSFYALDNQNLRQLWDWSKHNLTITQGKLFFHYNPKLCLSEIHKMEEVSGTKGRQE
RNDIALKTNGDQASCENELLKFSYIRTSFDKILLRWEPYWPPDFRDLLGFMLFYKEAPYQ
NVTEFDGQDACGSNSWTVVDIDPPLRSNDPKSQNHPGWLMRGLKPWTQYAIFVKTLVTFS
DERRTYGAKSDIIYVQTDATNPSVPLDPISVSNSSSQIILKWKPPSDPNGNITHYLVFWE
RQAEDSELFELDYCLKGLKLPSRTWSPPFESEDSQKHNQSEYEDSAGECCSCPKTDSQIL
KELEESSFRKTFEDYLHNVVFVPRKTSSGTGAEDPRPSRKRRSLGDVGNVTVAVPTVAAF
PNTSSTSVPTSPEEHRPFEKVVNKESLVISGLRHFTGYRIELQACNQDTPEERCSVAAYV
SARTMPEAKADDIVGPVTHEIFENNVVHLMWQEPKEPNGLIVLYEVSYRRYGDEELHLCV
SRKHFALERGCRLRGLSPGNYSVRIRATSLAGNGSWTEPTYFYVTDYLDVPSNIAKIIIG
PLIFVFLFSVVIGSIYLFLRKRQPDGPLGPLYASSNPEYLSASDVFPCSVYVPDEWEVSR
EKITLLRELGQGSFGMVYEGNARDIIKGEAETRVAVKTVNESASLRERIEFLNEASVMKG
FTCHHVVRLLGVVSKGQPTLVVMELMAHGDLKSYLRSLRPEAENNPGRPPPTLQEMIQMA
AEIADGMAYLNAKKFVHRDLAARNCMVAHDFTVKIGDFGMTRDIYETDYYRKGGKGLLPV
RWMAPESLKDGVFTTSSDMWSFGVVLWEITSLAEQPYQGLSNEQVLKFVMDGGYLDQPDN
CPERVTDLMRMCWQFNPKMRPTFLEIVNLLKDDLHPSFPEVSFFHSEENKAPESEELEME
FEDMENVPLDRSSHCQREEAGGRDGGSSLGFKRSYEEHIPYTHMNGGKKNGRILTLPRSN
PS
|
| External Links |
|---|
| GenBank ID Protein
| 307070 |
| UniProtKB/Swiss-Prot ID
| P06213 |
| UniProtKB/Swiss-Prot Entry Name
| INSR_HUMAN |
| PDB IDs
|
|
| GenBank Gene ID
| M10051 |
| GeneCard ID
| INSR |
| GenAtlas ID
| INSR |
| HGNC ID
| HGNC:6091 |
| References |
|---|
| General References
| Not Available |