| Identification |
|---|
| HMDB Protein ID
| CDBP01039 |
| Secondary Accession Numbers
| Not Available |
| Name
| Chondroitin sulfate synthase 1 |
| Description
| Not Available |
| Synonyms
|
- ChSy-1
- Chondroitin glucuronyltransferase 1
- Chondroitin synthase 1
- Glucuronosyl-N-acetylgalactosaminyl-proteoglycan 4-beta-N-acetylgalactosaminyltransferase 1
- N-acetylgalactosaminyl-proteoglycan 3-beta-glucuronosyltransferase 1
- N-acetylgalactosaminyltransferase 1
|
| Gene Name
| CHSY1 |
| Protein Type
| Enzyme |
| Biological Properties |
|---|
| General Function
| Involved in transferase activity, transferring hexosyl groups |
| Specific Function
| Has both beta-1,3-glucuronic acid and beta-1,4-N-acetylgalactosamine transferase activity. Transfers glucuronic acid (GlcUA) from UDP-GlcUA and N-acetylgalactosamine (GalNAc) from UDP-GalNAc to the non-reducing end of the elongating chondroitin polymer. Involved in the negative control of osteogenesis likely through the modulation of NOTCH signaling.
|
| GO Classification
|
| Biological Process |
| chondroitin sulfate biosynthetic process |
| negative regulation of ossification |
| response to nutrient levels |
| carbohydrate metabolic process |
| Cellular Component |
| Golgi membrane |
| Golgi cisterna membrane |
| extracellular region |
| integral to membrane |
| Component |
| golgi membrane |
| membrane |
| cell part |
| organelle membrane |
| golgi cisterna membrane |
| Function |
| catalytic activity |
| transferase activity |
| transferase activity, transferring hexosyl groups |
| transferase activity, transferring glycosyl groups |
| Molecular Function |
| metal ion binding |
| glucuronosyl-N-acetylgalactosaminyl-proteoglycan 4-beta-N-acetylgalactosaminyltransferase activity |
| N-acetylgalactosaminyl-proteoglycan 3-beta-glucuronosyltransferase activity |
|
| Cellular Location
|
- Golgi apparatus
- Golgi stack membrane
- Single-pass type II membrane protein (Probable)
|
| Pathways
|
| Name | SMPDB/Pathwhiz | KEGG | | Glycosaminoglycan biosynthesis - chondroitin sulfate / dermatan sulfate | Not Available | 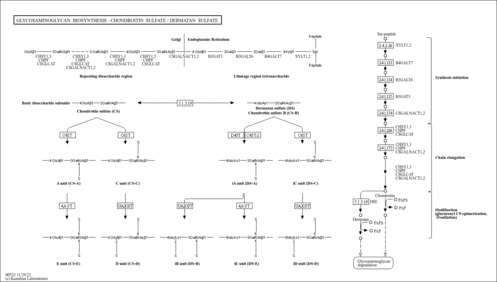 |
|
| Gene Properties |
|---|
| Chromosome Location
| 15 |
| Locus
| 15q26.3 |
| SNPs
| CHSY1 |
| Gene Sequence
|
>2409 bp
ATGGCCGCGCGCGGCCGGCGCGCCTGGCTCAGCGTGCTGCTCGGGCTCGTCCTGGGCTTC
GTGCTGGCCTCGCGGCTCGTCCTGCCCCGGGCTTCCGAGCTGAAGCGAGCGGGCCCACGG
CGCCGCGCCAGCCCCGAGGGCTGCCGGTCCGGGCAGGCGGCGGCTTCCCAGGCCGGCGGG
GCGCGCGGCGATGCGCGCGGGGCGCAGCTCTGGCCGCCCGGCTCGGACCCAGATGGCGGC
CCGCGCGACAGGAACTTTCTCTTCGTGGGAGTCATGACCGCCCAGAAATACCTGCAGACT
CGGGCCGTGGCCGCCTACAGAACATGGTCCAAGACAATTCCTGGGAAAGTTCAGTTCTTC
TCAAGTGAGGGTTCTGACACATCTGTACCAATTCCAGTAGTGCCACTACGGGGTGTGGAC
GACTCCTACCCGCCCCAGAAGAAGTCCTTCATGATGCTCAAGTACATGCACGACCACTAC
TTGGACAAGTATGAATGGTTTATGAGAGCAGATGATGACGTGTACATCAAAGGAGACCGT
CTGGAGAACTTCCTGAGGAGTTTGAACAGCAGCGAGCCCCTCTTTCTTGGGCAGACAGGC
CTGGGCACCACGGAAGAAATGGGAAAACTGGCCCTGGAGCCTGGTGAGAACTTCTGCATG
GGGGGGCCTGGCGTGATCATGAGCCGGGAGGTGCTTCGGAGAATGGTGCCGCACATTGGC
AAGTGTCTCCGGGAGATGTACACCACCCATGAGGACGTGGAGGTGGGAAGGTGTGTCCGG
AGGTTTGCAGGGGTGCAGTGTGTCTGGTCTTATGAGATGCAGCAGCTTTTTTATGAGAAT
TACGAGCAGAACAAAAAGGGGTACATTAGAGATCTCCATAACAGTAAAATTCACCAAGCT
ATCACATTACACCCCAACAAAAACCCACCCTACCAGTACAGGCTCCACAGCTACATGCTG
AGCCGCAAGATATCCGAGCTCCGCCATCGCACAATACAGCTGCACCGCGAAATTGTCCTG
ATGAGCAAATACAGCAACACAGAAATTCATAAAGAGGACCTCCAGCTGGGAATCCCTCCC
TCCTTCATGAGGTTTCAGCCCCGCCAGCGAGAGGAGATTCTGGAATGGGAGTTTCTGACT
GGAAAATACTTGTATTCGGCAGTTGACGGCCAGCCCCCTCGAAGAGGAATGGACTCCGCC
CAGAGGGAAGCCTTGGACGACATTGTCATGCAGGTCATGGAGATGATCAATGCCAACGCC
AAGACCAGAGGGCGCATCATTGACTTCAAAGAGATCCAGTACGGCTACCGCCGGGTGAAC
CCCATGTATGGGGCTGAGTACATCCTGGACCTGCTGCTTCTGTACAAAAAGCACAAAGGG
AAGAAAATGACGGTCCCTGTGAGGAGGCACGCGTATTTACAGCAGACTTTCAGCAAAATC
CAGTTTGTGGAGCATGAGGAGCTGGATGCACAAGAGTTGGCCAAGAGAATCAATCAGGAA
TCTGGATCCTTGTCCTTTCTCTCAAACTCCCTGAAGAAGCTCGTCCCCTTTCAGCTCCCT
GGGTCGAAGAGTGAGCACAAAGAACCCAAAGATAAAAAGATAAACATACTGATTCCTTTG
TCTGGGCGTTTCGACATGTTTGTGAGATTTATGGGAAACTTTGAGAAGACGTGTCTTATC
CCCAATCAGAACGTCAAGCTCGTGGTTCTGCTTTTCAATTCTGACTCCAACCCTGACAAG
GCCAAACAAGTTGAACTGATGAGAGATTACCGCATTAAGTACCCTAAAGCCGACATGCAG
ATTTTGCCTGTGTCTGGAGAGTTTTCAAGAGCCCTGGCCCTGGAAGTAGGATCCTCCCAG
TTTAACAATGAATCTTTGCTCTTCTTCTGCGACGTCGACCTCGTGTTTACTACAGAATTC
CTTCAGCGATGTCGAGCAAATACAGTTCTGGGCCAACAAATATATTTTCCAATCATCTTC
AGCCAGTATGACCCAAAGATTGTTTATAGTGGGAAAGTTCCCAGTGACAACCATTTTGCC
TTTACTCAGAAAACTGGCTTCTGGAGAAACTATGGGTTTGGCATCACGTGTATTTATAAG
GGAGATCTTGTCCGAGTGGGTGGCTTTGATGTTTCCATCCAAGGCTGGGGGCTGGAGGAT
GTGGACCTTTTCAACAAGGTTGTCCAGGCAGGTTTGAAGACGTTTAGGAGCCAGGAAGTA
GGAGTAGTCCACGTCCACCATCCTGTCTTTTGTGATCCCAATCTTGACCCCAAACAGTAC
AAAATGTGCTTGGGGTCCAAAGCATCGACCTATGGGTCCACCCAGCAGCTGGCTGAGATG
TGGCTGGAAAAAAATGATCCAAGTTACAGTAAAAGCAGCAATAATAATGGCTCAGTGAGG
ACAGCCTAA
|
| Protein Properties |
|---|
| Number of Residues
| 802 |
| Molecular Weight
| 91783.785 |
| Theoretical pI
| 9.238 |
| Pfam Domain Function
|
|
| Signals
|
Not Available
|
|
Transmembrane Regions
|
Not Available
|
| Protein Sequence
|
>Chondroitin sulfate synthase 1
MAARGRRAWLSVLLGLVLGFVLASRLVLPRASELKRAGPRRRASPEGCRSGQAAASQAGG
ARGDARGAQLWPPGSDPDGGPRDRNFLFVGVMTAQKYLQTRAVAAYRTWSKTIPGKVQFF
SSEGSDTSVPIPVVPLRGVDDSYPPQKKSFMMLKYMHDHYLDKYEWFMRADDDVYIKGDR
LENFLRSLNSSEPLFLGQTGLGTTEEMGKLALEPGENFCMGGPGVIMSREVLRRMVPHIG
KCLREMYTTHEDVEVGRCVRRFAGVQCVWSYEMQQLFYENYEQNKKGYIRDLHNSKIHQA
ITLHPNKNPPYQYRLHSYMLSRKISELRHRTIQLHREIVLMSKYSNTEIHKEDLQLGIPP
SFMRFQPRQREEILEWEFLTGKYLYSAVDGQPPRRGMDSAQREALDDIVMQVMEMINANA
KTRGRIIDFKEIQYGYRRVNPMYGAEYILDLLLLYKKHKGKKMTVPVRRHAYLQQTFSKI
QFVEHEELDAQELAKRINQESGSLSFLSNSLKKLVPFQLPGSKSEHKEPKDKKINILIPL
SGRFDMFVRFMGNFEKTCLIPNQNVKLVVLLFNSDSNPDKAKQVELMRDYRIKYPKADMQ
ILPVSGEFSRALALEVGSSQFNNESLLFFCDVDLVFTTEFLQRCRANTVLGQQIYFPIIF
SQYDPKIVYSGKVPSDNHFAFTQKTGFWRNYGFGITCIYKGDLVRVGGFDVSIQGWGLED
VDLFNKVVQAGLKTFRSQEVGVVHVHHPVFCDPNLDPKQYKMCLGSKASTYGSTQQLAEM
WLEKNDPSYSKSSNNNGSVRTA
|
| External Links |
|---|
| GenBank ID Protein
| 31542309 |
| UniProtKB/Swiss-Prot ID
| Q86X52 |
| UniProtKB/Swiss-Prot Entry Name
| CHSS1_HUMAN |
| PDB IDs
|
Not Available |
| GenBank Gene ID
| NM_014918.4 |
| GeneCard ID
| CHSY1 |
| GenAtlas ID
| CHSY1 |
| HGNC ID
| HGNC:17198 |
| References |
|---|
| General References
| Not Available |