| Identification |
|---|
| HMDB Protein ID
| CDBP00740 |
| Secondary Accession Numbers
| Not Available |
| Name
| Glycine dehydrogenase [decarboxylating], mitochondrial |
| Description
| Not Available |
| Synonyms
|
- Glycine cleavage system P protein
- Glycine decarboxylase
|
| Gene Name
| GLDC |
| Protein Type
| Enzyme |
| Biological Properties |
|---|
| General Function
| Involved in lyase activity |
| Specific Function
| The glycine cleavage system catalyzes the degradation of glycine. The P protein binds the alpha-amino group of glycine through its pyridoxal phosphate cofactor; CO(2) is released and the remaining methylamine moiety is then transferred to the lipoamide cofactor of the H protein.
|
| GO Classification
|
| Biological Process |
| glycine catabolic process |
| Cellular Component |
| mitochondrion |
| Function |
| oxidoreductase activity |
| oxidoreductase activity, acting on the ch-nh2 group of donors, disulfide as acceptor |
| glycine dehydrogenase (decarboxylating) activity |
| binding |
| catalytic activity |
| lyase activity |
| oxidoreductase activity, acting on the ch-nh2 group of donors |
| cofactor binding |
| pyridoxal phosphate binding |
| Molecular Function |
| electron carrier activity |
| pyridoxal phosphate binding |
| glycine dehydrogenase (decarboxylating) activity |
| lyase activity |
| Process |
| metabolic process |
| cellular metabolic process |
| serine family amino acid metabolic process |
| glycine metabolic process |
| oxidation reduction |
| cellular amino acid and derivative metabolic process |
| cellular amino acid metabolic process |
|
| Cellular Location
|
- Mitochondrion
|
| Pathways
|
| Name | SMPDB/Pathwhiz | KEGG | | Glycine, serine and threonine metabolism | Not Available | 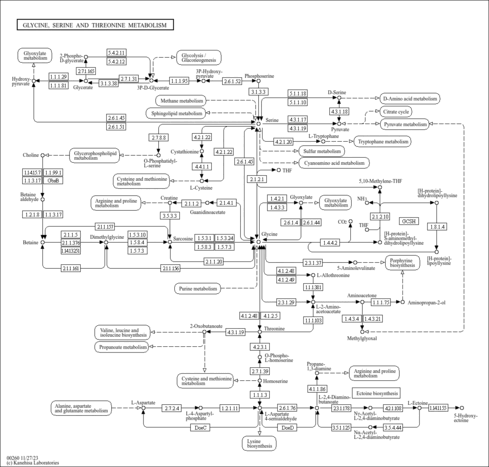 | | Glycine and Serine Metabolism |    | | | Dimethylglycine Dehydrogenase Deficiency | 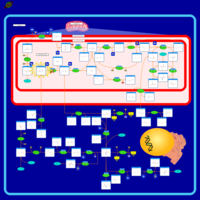 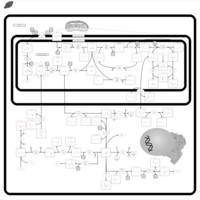  | Not Available | | Dihydropyrimidine Dehydrogenase Deficiency (DHPD) | 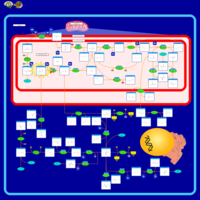 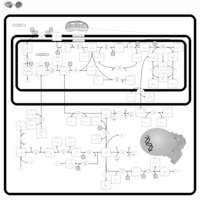  | Not Available | | Sarcosinemia |    | Not Available |
|
| Gene Properties |
|---|
| Chromosome Location
| 9 |
| Locus
| 9p22 |
| SNPs
| GLDC |
| Gene Sequence
|
>3063 bp
ATGCAGTCCTGTGCCAGGGCGTGGGGGCTGCGCCTGGGCCGCGGGGTCGGGGGCGGCCGC
CGCCTGGCTGGGGGATCGGGGCCGTGCTGGGCGCCGCGGAGCCGGGACAGCAGCAGTGGC
GGCGGGGACAGCGCCGCGGCTGGGGCCTCGCGCCTCCTGGAGCGCCTTCTGCCCAGACAC
GACGACTTCGCTCGGAGGCACATCGGCCCTGGGGACAAAGACCAGAGAGAGATGCTGCAG
ACCTTGGGGCTGGCGAGCATTGATGAATTGATCGAGAAGACGGTCCCTGCCAACATCCGT
TTGAAAAGACCCTTGAAAATGGAAGACCCTGTTTGTGAAAATGAAATCCTTGCAACTCTG
CATGCCATTTCAAGCAAAAACCAGATCTGGAGATCGTATATTGGCATGGGCTATTATAAC
TGCTCAGTGCCACAGACGATTTTGCGGAACTTACTGGAGAACTCAGGATGGATCACCCAG
TATACTCCATACCAGCCTGAGGTGTCTCAGGGGAGGCTGGAGAGTTTACTCAACTACCAG
ACCATGGTGTGTGACATCACAGGCCTGGACATGGCCAATGCATCCCTGCTGGATGAGGGG
ACTGCAGCCGCAGAGGCACTGCAGCTGTGCTACAGACACAACAAGAGGAGGAAATTTCTC
GTTGATCCCCGTTGCCACCCACAGACAATAGCTGTTGTCCAGACTCGAGCCAAATATACT
GGAGTCCTCACTGAGCTGAAGCTACCCTGTGAAATGGACTTCAGTGGAAAAGATGTCAGT
GGAGTGTTGTTCCAGTACCCAGACACGGAGGGGAAGGTGGAAGACTTTACGGAACTCGTG
GAGAGAGCTCATCAGAGTGGGAGCCTGGCCTGCTGTGCTACTGACCTTTTAGCTTTGTGC
ATCTTGAGGCCACCTGGAGAATTTGGGGTAGACATCGCCCTGGGCAGCTCCCAGAGATTT
GGAGTGCCACTGGGCTATGGGGGACCCCATGCAGCATTTTTTGCTGTCCGAGAAAGCTTG
GTGAGAATGATGCCTGGAAGAATGGTGGGGGTAACAAGAGATGCCACTGGGAAAGAAGTG
TATCGTCTTGCTCTTCAAACCAGGGAGCAACACATTCGGAGAGACAAGGCTACCAGCAAC
ATCTGTACAGCTCAGGCCCTCTTGGCGAATATGGCTGCCATGTTTGCAATCTACCATGGT
TCCCATGGGCTGGAGCATATTGCTAGGAGGGTACATAATGCCACTTTGATTTTGTCAGAA
GGTCTCAAGCGAGCAGGGCATCAACTCCAGCATGACCTGTTCTTTGATACCTTGAAGATT
CAGTGTGGCTGCTCAGTGAAGGAGGTCTTGGGCAGGGCCGCTCAGCGGCAGATCAATTTT
CGGCTTTTTGAGGATGGCACACTTGGTATTTCTCTTGATGAAACAGTCAATGAAAAAGAT
CTGGACGATTTGTTGTGGATCTTTGGTTGTGAGTCATCTGCAGAACTGGTTGCTGAAAGC
ATGGGAGAGGAGTGCAGAGGTATTCCAGGGTCTGTGTTCAAGAGGACCAGCCCGTTCCTC
ACCCATCAAGTGTTCAACAGCTACCACTCTGAAACAAACATTGTCCGGTACATGAAGAAA
CTGGAAAATAAAGACATTTCCCTTGTTCACAGCATGATTCCACTGGGATCCTGCACCATG
AAACTGAACAGTTCGTCTGAACTCGCACCTATCACATGGAAAGAATTTGCAAACATCCAC
CCCTTTGTGCCTCTGGATCAAGCTCAAGGATATCAGCAGCTTTTCCGAGAGCTTGAGAAG
GATTTGTGTGAACTCACAGGTTATGACCAGGTCTGTTTCCAGCCAAACAGCGGAGCCCAG
GGAGAATATGCTGGACTGGCCACTATCCGAGCCTACTTAAACCAGAAAGGAGAGGGGCAC
AGAACGGTTTGCCTCATTCCGAAATCAGCACATGGGACCAACCCAGCAAGTGCCCACATG
GCAGGCATGAAGATTCAGCCTGTGGAGGTGGATAAATATGGGAATATCGATGCAGTTCAC
CTCAAGGCCATGGTGGATAAGCACAAGGAGAACCTAGCAGCTATCATGATTACATACCCA
TCCACCAATGGGGTGTTTGAAGAGAACATCAGTGACGTGTGTGACCTCATCCATCAACAT
GGAGGACAGGTCTACCTAGACGGGGCAAATATGAATGCTCAGGTGGGAATCTGTCGCCCT
GGAGACTTCGGGTCTGATGTCTCGCACCTAAATCTTCACAAGACCTTCTGCATTCCCCAC
GGAGGAGGTGGTCCTGGCATGGGGCCCATCGGAGTGAAGAAACATCTCGCCCCGTTTTTG
CCCAATCATCCCGTCATTTCACTAAAGCGGAATGAGGATGCCTGTCCTGTGGGAACCGTC
AGTGCGGCCCCATGGGGCTCCAGTTCCATCTTGCCCATTTCCTGGGCTTATATCAAGATG
ATGGGAGGCAAGGGTCTTAAACAAGCCACGGAAACTGCGATATTAAATGCCAACTACATG
GCCAAGCGATTAGAAACACACTACAGAATTCTTTTCAGGGGTGCAAGAGGTTATGTGGGT
CATGAATTTATTTTGGACACGAGACCCTTCAAAAAGTCTGCAAATATTGAGGCTGTGGAT
GTGGCCAAGAGACTCCAGGATTATGGATTTCACGCCCCTACCATGTCCTGGCCTGTGGCA
GGGACCCTCATGGTGGAGCCCACTGAGTCGGAGGACAAGGCAGAGCTGGACAGATTCTGT
GATGCCATGATCAGCATTCGGCAGGAAATTGCTGACATTGAGGAGGGCCGCATCGACCCC
AGGGTCAATCCGCTGAAGATGTCTCCACACTCCCTGACCTGCGTTACATCTTCCCACTGG
GACCGGCCTTATTCCAGAGAGGTGGCAGCATTCCCACTCCCCTTCGTGAAACCAGAGAAC
AAATTCTGGCCAACGATTGCCCGGATTGATGACATATATGGAGATCAGCACCTGGTTTGT
ACCTGCCCACCCATGGAAGTTTATGAGTCTCCATTTTCTGAACAAAAGAGGGCGTCTTCT
TAG
|
| Protein Properties |
|---|
| Number of Residues
| 1020 |
| Molecular Weight
| 112728.805 |
| Theoretical pI
| 7.111 |
| Pfam Domain Function
|
|
| Signals
|
Not Available
|
|
Transmembrane Regions
|
Not Available
|
| Protein Sequence
|
>Glycine dehydrogenase [decarboxylating], mitochondrial
MQSCARAWGLRLGRGVGGGRRLAGGSGPCWAPRSRDSSSGGGDSAAAGASRLLERLLPRH
DDFARRHIGPGDKDQREMLQTLGLASIDELIEKTVPANIRLKRPLKMEDPVCENEILATL
HAISSKNQIWRSYIGMGYYNCSVPQTILRNLLENSGWITQYTPYQPEVSQGRLESLLNYQ
TMVCDITGLDMANASLLDEGTAAAEALQLCYRHNKRRKFLVDPRCHPQTIAVVQTRAKYT
GVLTELKLPCEMDFSGKDVSGVLFQYPDTEGKVEDFTELVERAHQSGSLACCATDLLALC
ILRPPGEFGVDIALGSSQRFGVPLGYGGPHAAFFAVRESLVRMMPGRMVGVTRDATGKEV
YRLALQTREQHIRRDKATSNICTAQALLANMAAMFAIYHGSHGLEHIARRVHNATLILSE
GLKRAGHQLQHDLFFDTLKIQCGCSVKEVLGRAAQRQINFRLFEDGTLGISLDETVNEKD
LDDLLWIFGCESSAELVAESMGEECRGIPGSVFKRTSPFLTHQVFNSYHSETNIVRYMKK
LENKDISLVHSMIPLGSCTMKLNSSSELAPITWKEFANIHPFVPLDQAQGYQQLFRELEK
DLCELTGYDQVCFQPNSGAQGEYAGLATIRAYLNQKGEGHRTVCLIPKSAHGTNPASAHM
AGMKIQPVEVDKYGNIDAVHLKAMVDKHKENLAAIMITYPSTNGVFEENISDVCDLIHQH
GGQVYLDGANMNAQVGICRPGDFGSDVSHLNLHKTFCIPHGGGGPGMGPIGVKKHLAPFL
PNHPVISLKRNEDACPVGTVSAAPWGSSSILPISWAYIKMMGGKGLKQATETAILNANYM
AKRLETHYRILFRGARGYVGHEFILDTRPFKKSANIEAVDVAKRLQDYGFHAPTMSWPVA
GTLMVEPTESEDKAELDRFCDAMISIRQEIADIEEGRIDPRVNPLKMSPHSLTCVTSSHW
DRPYSREVAAFPLPFVKPENKFWPTIARIDDIYGDQHLVCTCPPMEVYESPFSEQKRASS
|
| External Links |
|---|
| GenBank ID Protein
| 189054321 |
| UniProtKB/Swiss-Prot ID
| P23378 |
| UniProtKB/Swiss-Prot Entry Name
| GCSP_HUMAN |
| PDB IDs
|
Not Available |
| GenBank Gene ID
| AK314156 |
| GeneCard ID
| GLDC |
| GenAtlas ID
| GLDC |
| HGNC ID
| HGNC:4313 |
| References |
|---|
| General References
| Not Available |