| Identification |
|---|
| HMDB Protein ID
| CDBP00359 |
| Secondary Accession Numbers
| Not Available |
| Name
| Neutral alpha-glucosidase AB |
| Description
| Not Available |
| Synonyms
|
- Alpha-glucosidase 2
- Glucosidase II subunit alpha
|
| Gene Name
| GANAB |
| Protein Type
| Enzyme |
| Biological Properties |
|---|
| General Function
| Involved in catalytic activity |
| Specific Function
| Cleaves sequentially the 2 innermost alpha-1,3-linked glucose residues from the Glc(2)Man(9)GlcNAc(2) oligosaccharide precursor of immature glycoproteins.
|
| GO Classification
|
| Biological Process |
| protein folding |
| post-translational protein modification |
| protein N-linked glycosylation via asparagine |
| Cellular Component |
| melanosome |
| glucosidase II complex |
| endoplasmic reticulum lumen |
| Golgi apparatus |
| Function |
| catalytic activity |
| hydrolase activity |
| hydrolase activity, acting on glycosyl bonds |
| hydrolase activity, hydrolyzing o-glycosyl compounds |
| Molecular Function |
| carbohydrate binding |
| glucan 1,3-alpha-glucosidase activity |
| Process |
| metabolic process |
| primary metabolic process |
| carbohydrate metabolic process |
|
| Cellular Location
|
- Melanosome
- Golgi apparatus
- Endoplasmic reticulum
|
| Pathways
|
| Name | SMPDB/Pathwhiz | KEGG | | N-glycan metabolism | Not Available | Not Available | | N-Glycan biosynthesis | Not Available | 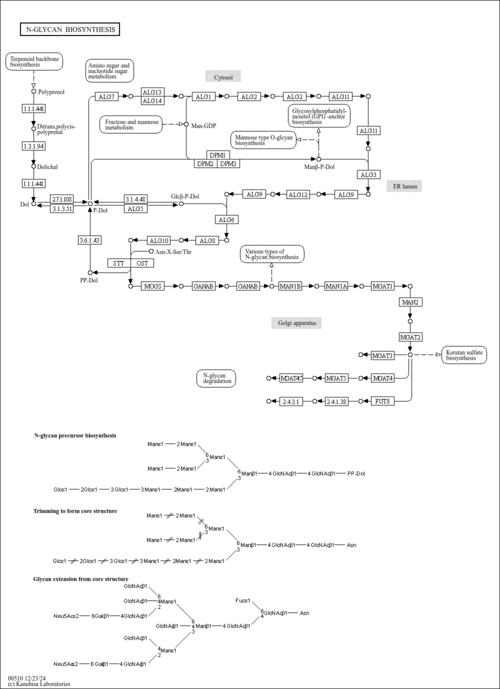 | | Protein processing in endoplasmic reticulum | Not Available | 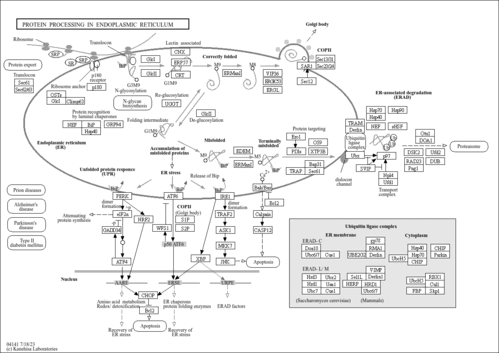 |
|
| Gene Properties |
|---|
| Chromosome Location
| Not Available |
| Locus
| Not Available |
| SNPs
| GANAB |
| Gene Sequence
|
>2835 bp
ATGGCGGCGGTAGCGGCAGTGGCGGCGCGTAGGAGGCGGTCTTGGGCGTCTTTGGTACTG
GCTTTTTTAGGGGTCTGCCTGGGGATTACCCTTGCTGTGGATAGAAGCAACTTTAAGACC
TGTGAAGAGAGTTCTTTCTGCAAGCGACAGAGAAGCATACGGCCAGGCCTCTCTCCATAC
CGAGCCTTGCTGGACTCTCTACAGCTTGGTCCTGATTCCCTCACGGTCCATCTGATCCAT
GAGGTCACCAAGGTGTTGCTGGTGCTAGAGCTTCAGGGGCTTCAAAAGAACATGACTCGG
TTCAGGATTGATGAGCTGGAGCCTCGGCGACCCCGATACCGTGTACCAGATGTTTTGGTG
GCTGATCCACCAATAGCCCGGCTTTCTGTCTCTGGTCGTGATGAGAACAGTGTGGAGTTA
ACCATGGCTGAGGGACCCTACAAGATCATCTTGACAGCACGGCCATTCCGCCTTGACCTA
CTAGAGGACCGAAGTCTTTTGCTTAGTGTCAATGCCCGAGGACTCTTGGAGTTTGAGCAT
CAGAGGGCCCCTAGGGTCTCGCAAGGATCAAAAGACCCAGCTGAGGGCGATGGGGCCCAG
CCTGAGGAAACACCCAGGGATGGCGACAAGCCAGAGGAGACTCAGGGGAAGGCAGAGAAA
GATGAGCCAGGAGCCTGGGAGGAGACATTCAAAACTCACTCTGACAGCAAGCCGTATGGC
CCCATGTCTGTGGGTTTGGACTTCTCTCTGCCAGGCATGGAGCATGTCTATGGGATCCCT
GAGCATGCAGACAACCTGAGGCTGAAGGTCACTGAGGGTGGGGAGCCATATCGCCTCTAC
AATTTGGATGTGTTCCAGTATGAGCTGTACAACCCAATGGCCTTGTATGGGTCTGTGCCT
GTGCTCCTGGCACACAACCCTCATCGCGACTTGGGCATCTTCTGGCTCAATGCTGCAGAG
ACCTGGGTTGATATATCTTCCAACACTGCCGGGAAGACCCTGTTTGGGAAGATGATGGAC
TACCTGCAGGGCTCTGGGGAGACCCCACAGACAGATGTTCGCTGGATGTCAGAGACTGGC
ATCATTGACGTCTTCCTGCTGCTGGGGCCCTCCATCTCTGATGTTTTCCGGCAATATGCT
AGTCTCACAGGAACCCAGGCGTTGCCCCCACTCTTCTCCCTCGGCTACCACCAGAGCCGT
TGGAACTACCGGGACGAGGCTGATGTGCTGGAAGTGGATCAGGGCTTTGATGATCACAAC
CTGCCCTGTGATGTCATCTGGCTAGACATTGAACATGCTGATGGCAAGCGGTATTTCACC
TGGGACCCCAGTCGCTTCCCTCAGCCCCGCACCATGCTTGAGCGCTTGGCTTCTAAGAGG
CGGAAGCTGGTGGCCATCGTAGACCCCCACATCAAGGTGGACTCCGGCTACCGAGTTCAC
GAGGAGCTGCGGAACCTGGGGCTGTATGTTAAAACCCGGGATGGCTCTGACTATGAGGGC
TGGTGCTGGCCAGGCTCAGCTGGTTACCCTGACTTCACTAATCCCACGATGAGGGCCTGG
TGGGCTAACATGTTCAGCTATGACAATTATGAGGGCTCAGCTCCCAACCTCTTTGTCTGG
AATGACATGAACGAACCATCTGTGTTCAATGGTCCTGAGGTCACCATGCTCAAGGATGCC
CAGCATTATGGGGGCTGGGAGCACCGGGATGTGCATAACATCTATGGCCTTTATGTGCAC
ATGGCGACTGCTGATGGGCTGAGACAGCGCTCTGGGGGCATGGAACGCCCCTTTGTCCTG
GCCAGGGCCTTCTTCGCTGGCTCCCAGCGCTTTGGAGCCGTGTGGACAGGGGACAACACT
GCCGAGTGGGACCATTTGAAGATCTCTATTCCTATGTGTCTCAGCTTGGGGCTGGTGGGA
CTTTCCTTCTGTGGGGCGGATGTGGGTGGCTTCTTCAAAAACCCAGAGCCAGAGCTGCTT
GTGCGCTGGTACCAGATGGGTGCTTACCAGCCATTCTTCCGGGCACATGCCCACTTGGAC
ACTGGGCGACGAGAGCCATGGCTGTTACCATCTCAGCACAATGATATAATCCGAGATGCC
TTGGGCCAGCGATATTCTTTGCTGCCCTTCTGGTACACCCTCTTATATCAGGCCCATCGG
GAAGGCATTCCTGTCATGAGGCCCCTGTGGGTGCAGTACCCTCAGGATGTGACTACCTTC
AATATAGATGATCAGTACTTGCTTGGGGATGCGTTGCTGGTTCACCCTGTATCAGACTCT
GGAGCCCATGGTGTCCAGGTCTATCTGCCTGGCCAAGGGGAGGTGTGGTATGACATTCAA
AGCTACCAGAAGCATCATGGTCCCCAGACCCTGTACCTGCCTGTAACTCTAAGCAGTATC
CCTGTGTTCCAGCGTGGAGGGACAATCGTGCCTCGATGGATGCGAGTGCGGCGGTCTTCA
GAATGTATGAAGGATGACCCCATCACTCTCTTTGTTGCACTTAGCCCTCAGGGTACAGCT
CAAGGAGAGCTCTTTCTGGATGATGGGCACACGTTCAACTATCAGACTCGCCAAGAGTTC
CTGCTGCGTCGATTCTCATTCTCTGGCAACACCCTTGTCTCCAGCTCAGCAGACCCTGAA
GGACACTTTGAGACACCAATCTGGATTGAGCGGGTGGTGATAATAGGGGCTGGAAAGCCA
GCAGCTGTGGTACTCCAGACAAAAGGATCTCCAGAAAGCCGCCTGTCCTTCCAGCATGAC
CCTGAGACCTCTGTGTTGGTCCTGCGCAAGCCTGGCATCAATGTGGCATCTGATTGGAGT
ATTCACCTGCGATAA
|
| Protein Properties |
|---|
| Number of Residues
| 944 |
| Molecular Weight
| Not Available |
| Theoretical pI
| Not Available |
| Pfam Domain Function
|
|
| Signals
|
Not Available
|
|
Transmembrane Regions
|
Not Available
|
| Protein Sequence
|
>Neutral alpha-glucosidase AB
MAAVAAVAARRRRSWASLVLAFLGVCLGITLAVDRSNFKTCEESSFCKRQRSIRPGLSPY
RALLDSLQLGPDSLTVHLIHEVTKVLLVLELQGLQKNMTRFRIDELEPRRPRYRVPDVLV
ADPPIARLSVSGRDENSVELTMAEGPYKIILTARPFRLDLLEDRSLLLSVNARGLLEFEH
QRAPRVSQGSKDPAEGDGAQPEETPRDGDKPEETQGKAEKDEPGAWEETFKTHSDSKPYG
PMSVGLDFSLPGMEHVYGIPEHADNLRLKVTEGGEPYRLYNLDVFQYELYNPMALYGSVP
VLLAHNPHRDLGIFWLNAAETWVDISSNTAGKTLFGKMMDYLQGSGETPQTDVRWMSETG
IIDVFLLLGPSISDVFRQYASLTGTQALPPLFSLGYHQSRWNYRDEADVLEVDQGFDDHN
LPCDVIWLDIEHADGKRYFTWDPSRFPQPRTMLERLASKRRKLVAIVDPHIKVDSGYRVH
EELRNLGLYVKTRDGSDYEGWCWPGSAGYPDFTNPTMRAWWANMFSYDNYEGSAPNLFVW
NDMNEPSVFNGPEVTMLKDAQHYGGWEHRDVHNIYGLYVHMATADGLRQRSGGMERPFVL
ARAFFAGSQRFGAVWTGDNTAEWDHLKISIPMCLSLGLVGLSFCGADVGGFFKNPEPELL
VRWYQMGAYQPFFRAHAHLDTGRREPWLLPSQHNDIIRDALGQRYSLLPFWYTLLYQAHR
EGIPVMRPLWVQYPQDVTTFNIDDQYLLGDALLVHPVSDSGAHGVQVYLPGQGEVWYDIQ
SYQKHHGPQTLYLPVTLSSIPVFQRGGTIVPRWMRVRRSSECMKDDPITLFVALSPQGTA
QGELFLDDGHTFNYQTRQEFLLRRFSFSGNTLVSSSADPEGHFETPIWIERVVIIGAGKP
AAVVLQTKGSPESRLSFQHDPETSVLVLRKPGINVASDWSIHLR
|
| External Links |
|---|
| GenBank ID Protein
| 38202257 |
| UniProtKB/Swiss-Prot ID
| Q14697 |
| UniProtKB/Swiss-Prot Entry Name
| GANAB_HUMAN |
| PDB IDs
|
Not Available |
| GenBank Gene ID
| NM_198334.1 |
| GeneCard ID
| GANAB |
| GenAtlas ID
| GANAB |
| HGNC ID
| HGNC:4138 |
| References |
|---|
| General References
| Not Available |