| Identification |
|---|
| HMDB Protein ID
| CDBP00045 |
| Secondary Accession Numbers
| Not Available |
| Name
| Acetyl-CoA carboxylase 1 |
| Description
| Not Available |
| Synonyms
|
- ACC-alpha
- Biotin carboxylase
- ACC1
|
| Gene Name
| ACACA |
| Protein Type
| Enzyme |
| Biological Properties |
|---|
| General Function
| Involved in acetyl-CoA carboxylase activity |
| Specific Function
| Catalyzes the rate-limiting reaction in the biogenesis of long-chain fatty acids. Carries out three functions: biotin carboxyl carrier protein, biotin carboxylase and carboxyltransferase.
|
| GO Classification
|
| Biological Process |
| fatty acid biosynthetic process |
| lipid homeostasis |
| long-chain fatty-acyl-CoA biosynthetic process |
| malonyl-CoA biosynthetic process |
| multicellular organismal protein metabolic process |
| positive regulation of cellular metabolic process |
| protein homotetramerization |
| response to organic cyclic compound |
| tissue homeostasis |
| triglyceride biosynthetic process |
| response to drug |
| acetyl-CoA metabolic process |
| energy reserve metabolic process |
| Cellular Component |
| cytosol |
| mitochondrion |
| Function |
| adenyl nucleotide binding |
| adenyl ribonucleotide binding |
| atp binding |
| ligase activity |
| vitamin binding |
| biotin binding |
| ligase activity, forming carbon-carbon bonds |
| coa carboxylase activity |
| acetyl-coa carboxylase activity |
| binding |
| catalytic activity |
| nucleoside binding |
| purine nucleoside binding |
| Molecular Function |
| metal ion binding |
| ATP binding |
| acetyl-CoA carboxylase activity |
| biotin binding |
| biotin carboxylase activity |
| Process |
| organic acid metabolic process |
| oxoacid metabolic process |
| carboxylic acid metabolic process |
| monocarboxylic acid metabolic process |
| fatty acid metabolic process |
| fatty acid biosynthetic process |
| metabolic process |
| cellular metabolic process |
|
| Cellular Location
|
- Cytoplasm
|
| Pathways
|
| Name | SMPDB/Pathwhiz | KEGG | | Fatty Acid Biosynthesis | 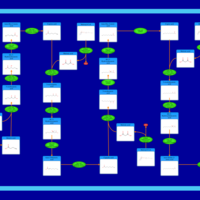 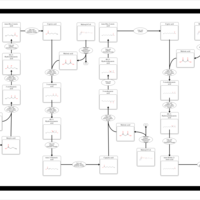 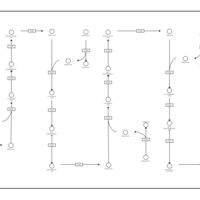 | Not Available | | Propanoate Metabolism |    | 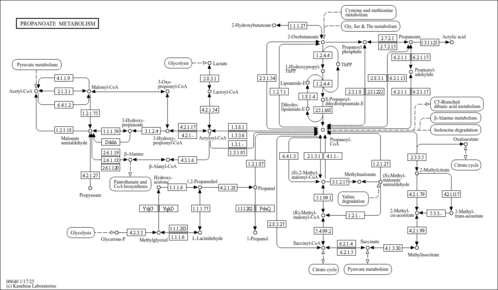 | | Pyruvate Metabolism |    |  | | malonyl-CoA biosynthesis | Not Available | Not Available | | Insulin signaling pathway | Not Available |  |
|
| Gene Properties |
|---|
| Chromosome Location
| 17 |
| Locus
| 17q21 |
| SNPs
| ACACA |
| Gene Sequence
|
>7041 bp
ATGGATGAACCATCTCCCTTGGCCCAACCTCTGGAGCTGAACCAGCACTCTCGATTCATA
ATAGGTTCTGTGTCTGAAGATAACTCAGAGGATGAGATCAGCAACCTGGTGAAGTTGGAC
CTACTGGAGGAGAAGGAGGGCTCCTTGTCACCTGCTTCTGTTGGCTCAGATACACTCTCT
GATTTGGGGATCTCTAGCCTACAGGATGGCTTGGCCTTGCACATAAGGTCCAGCATGTCT
GGCTTGCACCTAGTAAAGCAGGGCCGAGACAGAAAGAAAATAGATTCTCAACGAGATTTC
ACTGTGGCTTCTCCAGCAGAATTTGTTACTCGCTTTGGGGGAAATAAAGTGATTGAGAAG
GTTCTTATTGCTAACAATGGCATTGCAGCAGTGAAATGCATGCGGTCTATCCGTAGGTGG
TCTTATGAAATGTTTCGAAATGAACGTGCAATTAGATTCGTTGTCATGGTCACACCTGAA
GACCTTAAAGCCAATGCAGAATACATTAAGATGGCAGATCACTATGTGCCAGTGCCTGGA
GGACCAAACAACAACAACTATGCAAATGTGGAATTAATTCTTGATATTGCTAAAAGGATC
CCAGTACAAGCAGTGTGGGCTGGCTGGGGTCATGCTTCTGAGAATCCCAAACTACCGGAA
CTTCTCTTGAAAAATGGCATTGCCTTCATGGGTCCTCCAAGCCAGGCCATGTGGGCTTTA
GGGGATAAGATTGCATCTTCCATAGTGGCTCAAACTGCAGGTATCCCAACTCTTCCCTGG
AGCGGCAGTGGTCTTCGTGTGGACTGGCAGGAAAATGATTTTTCAAAACGTATCTTAAAT
GTTCCCCAGGAGCTATATGAAAAAGGTTATGTGAAAGATGTGGATGATGGGCTACAGGCA
GCTGAGGAAGTTGGATATCCAGTAATGATCAAGGCCTCAGAGGGAGGAGGAGGGAAGGGA
ATTAGAAAAGTCAACAATGCAGATGACTTCCCTAATCTCTTCAGACAGGTTCAAGCTGAA
GTTCCTGGATCTCCCATATTTGTGATGAGACTAGCCAAACAATCTCGTCATCTGGAGGTG
CAGATCTTAGCGGACCAATATGGCAATGCTATCTCTTTGTTTGGTCGTGATTGCTCTGTA
CAACGCAGGCATCAGAAGATTATTGAAGAAGCACCTGCTACTATTGCTACTCCAGCAGTA
TTTGAACACATGGAACAGTGTGCGGTGAAACTTGCCAAAATGGTGGGTTATGTGAGTGCT
GGGACTGTGGAATACCTGTACAGCCAGGATGGCAGCTTCTACTTTCTGGAATTGAATCCT
CGGCTGCAGGTAGAGCACCCTTGTACAGAGATGGTGGCTGATGTCAATCTCCCTGCAGCA
CAGCTCCAGATTGCCATGGGGATTCCTCTATATAGAATCAAGGATATCCGTATGATGTAT
GGGGTATCTCCCTGGGGTGATTCTCCCATTGATTTTGAAGATTCTGCACACGTTCCTTGT
CCAAGGGGCCATGTTATTGCTGCTCGGATCACTAGTGAAAATCCAGATGAGGGTTTTAAG
CCCAGCTCAGGAACAGTTCAGGAGCTAAATTTCCGCAGCAATAAGAATGTTTGGGGATAT
TTCAGTGTTGCTGCTGCAGGGGGACTTCATGAATTTGCTGATTCTCAGTTTGGTCACTGC
TTTTCTTGGGGAGAAAACAGAGAAGAGGCAATTTCAAACATGGTGGTGGCTTTGAAGGAG
CTGTCTATTCGGGGTGACTTTCGAACTACAGTTGAATACCTGATCAAATTGTTAGAGACT
GAAAGCTTTCAGATGAACAGAATTGATACTGGCTGGCTGGACAGACTGATAGCAGAAAAA
GTACAGGCTGAGCGACCTGACACCATGTTGGGGGTTGTGTGTGGTGCCCTCCACGTGGCA
GATGTGAGCCTGCGGAATAGCGTCTCTAACTTCCTTCACTCCTTAGAAAGGGGTCAAGTC
CTTCCTGCTCATACACTTCTGAATACAGTAGATGTTGAACTTATCTATGAGGGAGTCAAG
TATGTACTTAAGGTGACTCGACAGTCCCCCAACTCCTATGTGGTGATCATGAATGGCTCA
TGTGTAGAAGTAGATGTACATCGGCTGAGTGACGGTGGACTGCTCTTGTCCTATGATGGC
AGCAGTTATACTACGTATATGAAAGAGGAAGTGGATAGATATCGCATCACAATTGGCAAT
AAAACCTGTGTGTTTGAGAAGGAAAATGACCCATCGGTGATGCGCTCACCTTCTGCTGGG
AAGTTAATCCAGTACATTGTAGAAGATGGAGGTCATGTGTTTGCCGGCCAGTGCTATGCT
GAGATTGAGGTAATGAAGATGGTAATGACCTTAACAGCTGTGGAGTCTGGCTGTATCCAT
TACGTCAAGCGACCTGGAGCAGCTCTTGACCCTGGCTGTGTACTAGCCAAAATGCAACTG
GACAACCCCAGCAAGGTTCAGCAGGCTGAACTTCACACAGGTAGTCTGCCACGGATCCAG
AGCACGGCACTCAGAGGCGAGAAACTCCATCGAGTGTTCCATTATGTCCTGGATAATCTG
GTCAATGTAATGAATGGATACTGCCTTCCAGATCCTTTCTTTAGCAGCAAGGTAAAAGAC
TGGGTAGAGCGATTGATGAAAACCCTCAGAGATCCCTCCCTGCCTCTCCTAGAATTGCAA
GATATTATGACCAGTGTGTCTGGCCGCATTCCCCCCAATGTGGAGAAGTCTATCAAGAAG
GAAATGGCTCAGTATGCTAGCAACATCACATCAGTCCTCTGTCAGTTTCCCAGCCAGCAG
ATTGCAAACATCCTAGATAGCCATGCAGCTACATTGAACCGGAAATCTGAACGGGAAGTC
TTCTTTATGAATACTCAGAGCATTGTTCAGCTGGTACAGAGGTACCGAAGTGGCATCCGA
GGCCACATGAAGGCTGTGGTGATGGATCTGCTCCGGCAGTACCTGCGAGTAGAGACACAA
TTCCAGAATGGTCACTATGACAAATGTGTATTCGCCCTCCGAGAAGAGAATAAAAGTGAC
ATGAACACTGTACTGAACTACATCTTCTCTCACGCTCAAGTCACCAAGAAGAATCTTCTG
GTCACAATGCTTATTGATCAGTTGTGTGGCCGGGACCCTACTCTCACTGATGAGCTGCTG
AATATTCTCACAGAGCTAACTCAACTCAGTAAGACCACCAATGCCAAAGTAGCACTTCGA
GCACGCCAGGTTCTTATTGCCTCCCATTTGCCATCATATGAGCTTCGCCATAACCAAGTA
GAGTCTATCTTCCTATCAGCTATTGACATGTATGGACATCAATTTTGCATTGAGAACCTG
CAGAAACTCATCCTATCAGAAACATCTATTTTTGATGTCCTACCAAACTTCTTCTATCAC
AGCAACCAAGTAGTGAGGATGGCAGCTCTGGAGGTGTATGTTCGAAGGGCTTATATTGCC
TATGAACTTAACAGCGTACAACACCGCCAGCTTAAGGACAACACCTGTGTGGTGGAATTC
CAGTTCATGCTGCCCACATCTCATCCAAACAGAGGGAACATCCCTACGCTAAACAGAATG
TCCTTCTCCTCCAACCTCAACCACTATGGCATGACCCATGTAGCTAGTGTCAGCGATGTA
CTGTTGGACAACTCATTCACTCCACCTTGTCAGCGGATGGGCGGAATGGTCTCTTTTCGG
ACTTTTGAAGATTTTGTCAGGATCTTTGATGAAGTGATGGGCTGCTTCTCTGACTCCCCA
CCCCAGAGTCCCACATTCCCTGAGGCAGGTCACACGTCTCTTTATGATGAGGATAAGGTT
CCCAGGGATGAACCAATTCACATTCTCAATGTGGCTATCAAGACTGACTGTGATATTGAG
GATGACAGGCTGGCAGCTATGTTCAGAGAATTTACCCAGCAAAATAAAGCTACCCTGGTT
GACCATGGGATCCGGCGCCTTACTTTCCTGGTTGCACAAAAGGATTTCAGAAAGCAGGTC
AACTATGAGGTGGATCGGAGATTTCATAGAGAATTCCCTAAATTTTTTACATTCCGAGCA
AGGGATAAGTTTGAGGAGGATCGTATCTATCGTCATCTGGAGCCTGCTCTGGCTTTCCAG
TTAGAGCTGAACCGGATGAGAAATTTTGACCTCACTGCCATTCCATGTGCTAATCACAAG
ATGCACCTGTATCTCGGGGCAGCCAAGGTGGAAGTGGGCACAGAAGTGACAGACTACAGG
TTCTTTGTTCGTGCAATCATCAGGCATTCTGATCTGGTCACCAAGGAAGCTTCTTTTGAA
TATCTGCAAAATGAAGGGGAGCGGCTACTCCTGGAAGCCATGGATGAGTTGGAAGTTGCT
TTTAACAATACAAATGTCCGCACTGACTGTAACCACATCTTCCTCAACTTTGTGCCCACG
GTTATCATGGACCCATCAAAGATTGAGGAATCCGTGCGGAGCATGGTAATGCGGTATGGA
AGTCGCCTGTGGAAATTGCGCGTCCTCCAGGCAGAACTGAAAATCAACATTCGCCTGACG
CCAACTGGAAAAGCAATTCCCATCCGCCTCTTCCTGACAAACGAGTCTGGCTATTACTTG
GATATCAGCCTATACAAGGAAGTGACTGACTCCAGGACAGCACAGATCATGTTTCAGGCA
TATGGAGACAAACAGGGACCACTGCATGGAATGTTAATCAATACTCCATATGTGACCAAA
GACCTGCTGCAATCAAAGAGGTTCCAGGCACAATCCTTAGGGACAACATACATATATGAT
ATCCCAGAGATGTTTCGGCAGTCCCTGATCAAACTCTGGGAGTCTATGTCCACTCAAGCA
TTTCTTCCATCTCCCCCTCTGCCTTCTGACATGCTGACTTACACTGAACTGGTACTGGAT
GATCAAGGTCAGCTGGTCCACATGAACAGGCTTCCAGGAGGAAATGAGATTGGCATGGTA
GCTTGGAAAATGACCTTTAAAAGTCCTGAATATCCAGAAGGCCGAGATATCATTGTTATT
GGCAATGACATCACATACCGAATTGGGTCCTTTGGGCCTCAAGAGGATTTGTTATTTCTC
AGAGCTTCCGAACTTGCTAGGGCAGAAGGTATTCCACGCATCTATGTATCAGCCAACAGT
GGAGCAAGAATCGGACTGGCAGAAGAAATTCGCCATATGTTTCATGTGGCCTGGGTAGAT
CCTGAGGATCCTTACAAGGGATACAGGTATTTATATCTGACTCCTCAAGATTATAAGAGA
GTCAGTGCTCTCAACTCTGTCCATTGTGAACACGTGGAAGATGAAGGAGAATCCAGGTAC
AAGATAACAGATATTATTGGGAAAGAAGAGGGAATTGGACCCGAGAACCTTCGAGGTTCT
GGAATGATTGCTGGAGAATCCTCATTGGCCTATAATGAGATCATTACCATCAGCCTGGTG
ACGTGCCGGGCCATTGGGATTGGGGCTTACCTTGTCCGGCTGGGACAGAGAACCATCCAG
GTTGAGAATTCTCACTTAATTCTAACAGGAGCTGGAGCCCTCAACAAAGTCCTCGGGCGG
GAAGTGTACACCTCCAATAACCAGCTGGGGGGCATCCAGATTATGCACAACAATGGGGTG
ACCCACTGCACTGTGTGTGATGACTTTGAAGGGGTTTTCACTGTCCTGCACTGGCTGTCT
TACATGCCCAAGAGCGTGCACAGTTCAGTTCCTCTTCTGAACTCAAAGGATCCTATAGAC
AGAATCATCGAGTTTGTTCCCACAAAGACCCCATACGATCCTCGATGGATGCTAGCAGGC
CGTCCTCACCCAACCCAAAAAGGTCAGTGGTTGAGTGGCTTTTTTGACTATGGATCTTTC
TCAGAGATTATGCAGCCCTGGGCACAGACTGTGGTGGTTGGTAGAGCCAGGCTAGGAGGA
ATACCTGTGGGAGTTGTTGCTGTAGAAACCCGAACAGTAGAACTAAGTATCCCAGCTGAT
CCAGCAAACCTGGATTCTGAAGCCAAGATAATCCAGCAGGCTGGCCAGGTTTGGTTCCCA
GATTCTGCGTTTAAGACGTATCAGGCCATCAAGGACTTCAACCGGGAAGGGCTGCCTCTG
ATGGTCTTTGCCAACTGGAGAGGCTTCTCTGGTGGAATGAAAGATATGTACGACCAAGTG
CTGAAGTTTGGTGCTTACATTGTGGATGGCTTGAGGGAGTGCTGCCAGCCTGTGCTGGTT
TACATTCCTCCCCAGGCTGAGCTGCGGGGTGGCTCCTGGGTGGTGATTGACTCCTCCATC
AACCCCCGGCACATGGAGATGTATGCTGACCGAGAAAGCAGGGGATCTGTTCTGGAGCCA
GAAGGGACAGTAGAAATCAAATTCCGCAGAAAGGATCTGGTGAAAACCATGCGTCGGGTG
GACCCAGTCTACATCCACTTGGCTGAGCGATTGGGGACCCCAGAGCTAAGCACAGCTGAG
CGGAAGGAGTTGGAGAACAAGTTGAAGGAGCGGGAGGAATTCCTAATTCCCATTTACCAT
CAGGTAGCCGTGCAGTTTGCTGACTTGCACGACACACCAGGCCGGATGCAGGAGAAGGGT
GTTATTAGCGATATCCTGGATTGGAAAACATCCCGTACCTTCTTCTACTGGCGGCTGAGG
CGTCTTCTGCTGGAGGACCTGGTCAAGAAGAAAATCCACAATGCCAACCCTGAGCTGACT
GATGGCCAGATTCAAGCCATGTTAAGGCGCTGGTTTGTGGAAGTGGAAGGAACAGTGAAG
GCTTATGTTTGGGACAATAATAAGGATCTGGCGGAGTGGCTAGAGAAACAGCTGACAGAG
GAGGATGGTGTTCACTCGGTAATAGAGGAAAACATCAAATGCATCAGCAGAGACTACGTC
CTCAAGCAAATCCGCAGCTTGGTCCAGGCCAATCCAGAGGTTGCCATGGATTCCATCATC
CATATGACGCAGCACATATCACCCACTCAGCGAGCAGAAGTCATACGGATCCTCTCCACA
ATGGATTCCCCTTCCACGTAG
|
| Protein Properties |
|---|
| Number of Residues
| 2346 |
| Molecular Weight
| 269997.01 |
| Theoretical pI
| 6.521 |
| Pfam Domain Function
|
|
| Signals
|
Not Available
|
|
Transmembrane Regions
|
Not Available
|
| Protein Sequence
|
>Acetyl-CoA carboxylase 1
MDEPSPLAQPLELNQHSRFIIGSVSEDNSEDEISNLVKLDLLEEKEGSLSPASVGSDTLS
DLGISSLQDGLALHIRSSMSGLHLVKQGRDRKKIDSQRDFTVASPAEFVTRFGGNKVIEK
VLIANNGIAAVKCMRSIRRWSYEMFRNERAIRFVVMVTPEDLKANAEYIKMADHYVPVPG
GPNNNNYANVELILDIAKRIPVQAVWAGWGHASENPKLPELLLKNGIAFMGPPSQAMWAL
GDKIASSIVAQTAGIPTLPWSGSGLRVDWQENDFSKRILNVPQELYEKGYVKDVDDGLQA
AEEVGYPVMIKASEGGGGKGIRKVNNADDFPNLFRQVQAEVPGSPIFVMRLAKQSRHLEV
QILADQYGNAISLFGRDCSVQRRHQKIIEEAPATIATPAVFEHMEQCAVKLAKMVGYVSA
GTVEYLYSQDGSFYFLELNPRLQVEHPCTEMVADVNLPAAQLQIAMGIPLYRIKDIRMMY
GVSPWGDSPIDFEDSAHVPCPRGHVIAARITSENPDEGFKPSSGTVQELNFRSNKNVWGY
FSVAAAGGLHEFADSQFGHCFSWGENREEAISNMVVALKELSIRGDFRTTVEYLIKLLET
ESFQMNRIDTGWLDRLIAEKVQAERPDTMLGVVCGALHVADVSLRNSVSNFLHSLERGQV
LPAHTLLNTVDVELIYEGVKYVLKVTRQSPNSYVVIMNGSCVEVDVHRLSDGGLLLSYDG
SSYTTYMKEEVDRYRITIGNKTCVFEKENDPSVMRSPSAGKLIQYIVEDGGHVFAGQCYA
EIEVMKMVMTLTAVESGCIHYVKRPGAALDPGCVLAKMQLDNPSKVQQAELHTGSLPRIQ
STALRGEKLHRVFHYVLDNLVNVMNGYCLPDPFFSSKVKDWVERLMKTLRDPSLPLLELQ
DIMTSVSGRIPPNVEKSIKKEMAQYASNITSVLCQFPSQQIANILDSHAATLNRKSEREV
FFMNTQSIVQLVQRYRSGIRGHMKAVVMDLLRQYLRVETQFQNGHYDKCVFALREENKSD
MNTVLNYIFSHAQVTKKNLLVTMLIDQLCGRDPTLTDELLNILTELTQLSKTTNAKVALR
ARQVLIASHLPSYELRHNQVESIFLSAIDMYGHQFCIENLQKLILSETSIFDVLPNFFYH
SNQVVRMAALEVYVRRAYIAYELNSVQHRQLKDNTCVVEFQFMLPTSHPNRGNIPTLNRM
SFSSNLNHYGMTHVASVSDVLLDNSFTPPCQRMGGMVSFRTFEDFVRIFDEVMGCFSDSP
PQSPTFPEAGHTSLYDEDKVPRDEPIHILNVAIKTDCDIEDDRLAAMFREFTQQNKATLV
DHGIRRLTFLVAQKDFRKQVNYEVDRRFHREFPKFFTFRARDKFEEDRIYRHLEPALAFQ
LELNRMRNFDLTAIPCANHKMHLYLGAAKVEVGTEVTDYRFFVRAIIRHSDLVTKEASFE
YLQNEGERLLLEAMDELEVAFNNTNVRTDCNHIFLNFVPTVIMDPSKIEESVRSMVMRYG
SRLWKLRVLQAELKINIRLTPTGKAIPIRLFLTNESGYYLDISLYKEVTDSRTAQIMFQA
YGDKQGPLHGMLINTPYVTKDLLQSKRFQAQSLGTTYIYDIPEMFRQSLIKLWESMSTQA
FLPSPPLPSDMLTYTELVLDDQGQLVHMNRLPGGNEIGMVAWKMTFKSPEYPEGRDIIVI
GNDITYRIGSFGPQEDLLFLRASELARAEGIPRIYVSANSGARIGLAEEIRHMFHVAWVD
PEDPYKGYRYLYLTPQDYKRVSALNSVHCEHVEDEGESRYKITDIIGKEEGIGPENLRGS
GMIAGESSLAYNEIITISLVTCRAIGIGAYLVRLGQRTIQVENSHLILTGAGALNKVLGR
EVYTSNNQLGGIQIMHNNGVTHCTVCDDFEGVFTVLHWLSYMPKSVHSSVPLLNSKDPID
RIIEFVPTKTPYDPRWMLAGRPHPTQKGQWLSGFFDYGSFSEIMQPWAQTVVVGRARLGG
IPVGVVAVETRTVELSIPADPANLDSEAKIIQQAGQVWFPDSAFKTYQAIKDFNREGLPL
MVFANWRGFSGGMKDMYDQVLKFGAYIVDGLRECCQPVLVYIPPQAELRGGSWVVIDSSI
NPRHMEMYADRESRGSVLEPEGTVEIKFRRKDLVKTMRRVDPVYIHLAERLGTPELSTAE
RKELENKLKEREEFLIPIYHQVAVQFADLHDTPGRMQEKGVISDILDWKTSRTFFYWRLR
RLLLEDLVKKKIHNANPELTDGQIQAMLRRWFVEVEGTVKAYVWDNNKDLAEWLEKQLTE
EDGVHSVIEENIKCISRDYVLKQIRSLVQANPEVAMDSIIHMTQHISPTQRAEVIRILST
MDSPST
|
| External Links |
|---|
| GenBank ID Protein
| 38679967 |
| UniProtKB/Swiss-Prot ID
| Q13085 |
| UniProtKB/Swiss-Prot Entry Name
| ACACA_HUMAN |
| PDB IDs
|
|
| GenBank Gene ID
| NM_198836.1 |
| GeneCard ID
| ACACA |
| GenAtlas ID
| ACACA |
| HGNC ID
| HGNC:84 |
| References |
|---|
| General References
| Not Available |