Showing Protein Histone acetyltransferase p300 (CDBP00011)
| Identification | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| HMDB Protein ID | CDBP00011 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Secondary Accession Numbers | Not Available | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Name | Histone acetyltransferase p300 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Description | Not Available | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Synonyms |
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Gene Name | EP300 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Protein Type | Enzyme | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Biological Properties | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| General Function | Involved in transcription cofactor activity | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Specific Function | Functions as histone acetyltransferase and regulates transcription via chromatin remodeling. Acetylates all four core histones in nucleosomes. Histone acetylation gives an epigenetic tag for transcriptional activation. Mediates cAMP-gene regulation by binding specifically to phosphorylated CREB protein. Also functions as acetyltransferase for nonhistone targets. Acetylates 'Lys-131' of ALX1 and acts as its coactivator in the presence of CREBBP. Acetylates SIRT2 and is proposed to indirectly increase the transcriptional activity of TP53 through acetylation and subsequent attenuation of SIRT2 deacetylase function. Acetylates HDAC1 leading to its inactivation and modulation of transcription. Acts as a TFAP2A-mediated transcriptional coactivator in presence of CITED2. Plays a role as a coactivator of NEUROD1-dependent transcription of the secretin and p21 genes and controls terminal differentiation of cells in the intestinal epithelium. Promotes cardiac myocyte enlargement. Can also mediate transcriptional repression. Binds to and may be involved in the transforming capacity of the adenovirus E1A protein. In case of HIV-1 infection, it is recruited by the viral protein Tat. Regulates Tat's transactivating activity and may help inducing chromatin remodeling of proviral genes. Acetylates FOXO1 and enhances its transcriptional activity. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| GO Classification |
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Cellular Location |
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
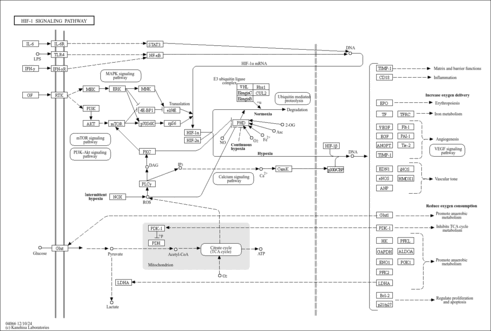
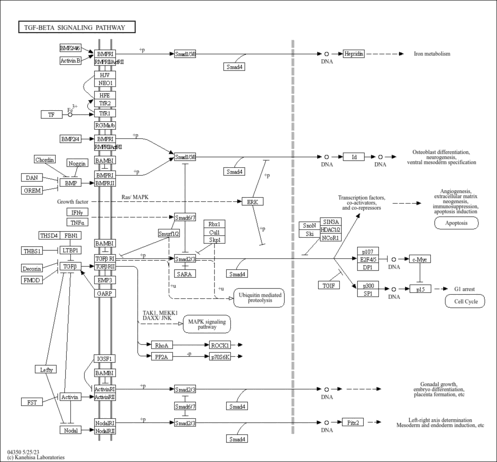
| Pathways |
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Gene Properties | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Chromosome Location | 22 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Locus | 22q13.2 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| SNPs | EP300 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Gene Sequence |
>7245 bp ATGGCCGAGAATGTGGTGGAACCGGGGCCGCCTTCAGCCAAGCGGCCTAAACTCTCATCT CCGGCCCTCTCGGCGTCCGCCAGCGATGGCACAGATTTTGGCTCTCTATTTGACTTGGAG CACGACTTACCAGATGAATTAATCAACTCTACAGAATTGGGACTAACCAATGGTGGTGAT ATTAATCAGCTTCAGACAAGTCTTGGCATGGTACAAGATGCAGCTTCTAAACATAAACAG CTGTCAGAATTGCTGCGATCTGGTAGTTCCCCTAACCTCAATATGGGAGTTGGTGGCCCA GGTCAAGTCATGGCCAGCCAGGCCCAACAGAGCAGTCCTGGATTAGGTTTGATAAATAGC ATGGTCAAAAGCCCAATGACACAGGCAGGCTTGACTTCTCCCAACATGGGGATGGGCACT AGTGGACCAAATCAGGGTCCTACGCAGTCAACAGGTATGATGAACAGTCCAGTAAATCAG CCTGCCATGGGAATGAACACAGGGATGAATGCGGGCATGAATCCTGGAATGTTGGCTGCA GGCAATGGACAAGGGATAATGCCTAATCAAGTCATGAACGGTTCAATTGGAGCAGGCCGA GGGCGACAGAATATGCAGTACCCAAACCCAGGCATGGGAAGTGCTGGCAACTTACTGACT GAGCCTCTTCAGCAGGGCTCTCCCCAGATGGGAGGACAAACAGGATTGAGAGGCCCCCAG CCTCTTAAGATGGGAATGATGAACAACCCCAATCCTTATGGTTCACCATATACTCAGAAT CCTGGACAGCAGATTGGAGCCAGTGGCCTTGGTCTCCAGATTCAGACAAAAACTGTACTA TCAAATAACTTATCTCCATTTGCTATGGACAAAAAGGCAGTTCCTGGTGGAGGAATGCCC AACATGGGTCAACAGCCAGCCCCGCAGGTCCAGCAGCCAGGCCTGGTGACTCCAGTTGCC CAAGGGATGGGTTCTGGAGCACATACAGCTGATCCAGAGAAGCGCAAGCTCATCCAGCAG CAGCTTGTTCTCCTTTTGCATGCTCACAAGTGCCAGCGCCGGGAACAGGCCAATGGGGAA GTGAGGCAGTGCAACCTTCCCCACTGTCGCACAATGAAGAATGTCCTAAACCACATGACA CACTGCCAGTCAGGCAAGTCTTGCCAAGTGGCACACTGTGCATCTTCTCGACAAATCATT TCACACTGGAAGAATTGTACAAGACATGATTGTCCTGTGTGTCTCCCCCTCAAAAATGCT GGTGATAAGAGAAATCAACAGCCAATTTTGACTGGAGCACCCGTTGGACTTGGAAATCCT AGCTCTCTAGGGGTGGGTCAACAGTCTGCCCCCAACCTAAGCACTGTTAGTCAGATTGAT CCCAGCTCCATAGAAAGAGCCTATGCAGCTCTTGGACTACCCTATCAAGTAAATCAGATG CCGACACAACCCCAGGTGCAAGCAAAGAACCAGCAGAATCAGCAGCCTGGGCAGTCTCCC CAAGGCATGCGGCCCATGAGCAACATGAGTGCTAGTCCTATGGGAGTAAATGGAGGTGTA GGAGTTCAAACGCCGAGTCTTCTTTCTGACTCAATGTTGCATTCAGCCATAAATTCTCAA AACCCAATGATGAGTGAAAATGCCAGTGTGCCCTCCCTGGGTCCTATGCCAACAGCAGCT CAACCATCCACTACTGGAATTCGGAAACAGTGGCACGAAGATATTACTCAGGATCTTCGA AATCATCTTGTTCACAAACTCGTCCAAGCCATATTTCCTACGCCGGATCCTGCTGCTTTA AAAGACAGACGGATGGAAAACCTAGTTGCATATGCTCGGAAAGTTGAAGGGGACATGTAT GAATCTGCAAACAATCGAGCGGAATACTACCACCTTCTAGCTGAGAAAATCTATAAGATC CAGAAAGAACTAGAAGAAAAACGAAGGACCAGACTACAGAAGCAGAACATGCTACCAAAT GCTGCAGGCATGGTTCCAGTTTCCATGAATCCAGGGCCTAACATGGGACAGCCGCAACCA GGAATGACTTCTAATGGCCCTCTACCTGACCCAAGTATGATCCGTGGCAGTGTGCCAAAC CAGATGATGCCTCGAATAACTCCACAATCTGGTTTGAATCAATTTGGCCAGATGAGCATG GCCCAGCCCCCTATTGTACCCCGGCAAACCCCTCCTCTTCAGCACCATGGACAGTTGGCT CAACCTGGAGCTCTCAACCCGCCTATGGGCTATGGGCCTCGTATGCAACAGCCTTCCAAC CAGGGCCAGTTCCTTCCTCAGACTCAGTTCCCATCACAGGGAATGAATGTAACAAATATC CCTTTGGCTCCGTCCAGCGGTCAAGCTCCAGTGTCTCAAGCACAAATGTCTAGTTCTTCC TGCCCGGTGAACTCTCCTATAATGCCTCCAGGGTCTCAGGGGAGCCACATTCACTGTCCC CAGCTTCCTCAACCAGCTCTTCATCAGAATTCACCCTCGCCTGTACCTAGTCGTACCCCC ACCCCTCACCATACTCCCCCAAGCATAGGGGCTCAGCAGCCACCAGCAACAACAATTCCA GCCCCTGTTCCTACACCTCCTGCCATGCCACCTGGGCCACAGTCCCAGGCTCTACATCCC CCTCCAAGGCAGACACCTACACCACCAACAACACAACTTCCCCAACAAGTGCAGCCTTCA CTTCCTGCTGCACCTTCTGCTGACCAGCCCCAGCAGCAGCCTCGCTCACAGCAGAGCACA GCAGCGTCTGTTCCTACCCCAACAGCACCGCTGCTTCCTCCGCAGCCTGCAACTCCACTT TCCCAGCCAGCTGTAAGCATTGAAGGACAGGTATCAAATCCTCCATCTACTAGTAGCACA GAAGTGAATTCTCAGGCCATTGCTGAGAAGCAGCCTTCCCAGGAAGTGAAGATGGAGGCC AAAATGGAAGTGGATCAACCAGAACCAGCAGATACTCAGCCGGAGGATATTTCAGAGTCT AAAGTGGAAGACTGTAAAATGGAATCTACCGAAACAGAAGAGAGAAGCACTGAGTTAAAA ACTGAAATAAAAGAGGAGGAAGACCAGCCAAGTACTTCAGCTACCCAGTCATCTCCGGCT CCAGGACAGTCAAAGAAAAAGATTTTCAAACCAGAAGAACTACGACAGGCACTGATGCCA ACTTTGGAGGCACTTTACCGTCAGGATCCAGAATCCCTTCCCTTTCGTCAACCTGTGGAC CCTCAGCTTTTAGGAATCCCTGATTACTTTGATATTGTGAAGAGCCCCATGGATCTTTCT ACCATTAAGAGGAAGTTAGACACTGGACAGTATCAGGAGCCCTGGCAGTATGTCGATGAT ATTTGGCTTATGTTCAATAATGCCTGGTTATATAACCGGAAAACATCACGGGTATACAAA TACTGCTCCAAGCTCTCTGAGGTCTTTGAACAAGAAATTGACCCAGTGATGCAAAGCCTT GGATACTGTTGTGGCAGAAAGTTGGAGTTCTCTCCACAGACACTGTGTTGCTACGGCAAA CAGTTGTGCACAATACCTCGTGATGCCACTTATTACAGTTACCAGAACAGGTATCATTTC TGTGAGAAGTGTTTCAATGAGATCCAAGGGGAGAGCGTTTCTTTGGGGGATGACCCTTCC CAGCCTCAAACTACAATAAATAAAGAACAATTTTCCAAGAGAAAAAATGACACACTGGAT CCTGAACTGTTTGTTGAATGTACAGAGTGCGGAAGAAAGATGCATCAGATCTGTGTCCTT CACCATGAGATCATCTGGCCTGCTGGATTCGTCTGTGATGGCTGTTTAAAGAAAAGTGCA CGAACTAGGAAAGAAAATAAGTTTTCTGCTAAAAGGTTGCCATCTACCAGACTTGGCACC TTTCTAGAGAATCGTGTGAATGACTTTCTGAGGCGACAGAATCACCCTGAGTCAGGAGAG GTCACTGTTAGAGTAGTTCATGCTTCTGACAAAACCGTGGAAGTAAAACCAGGCATGAAA GCAAGGTTTGTGGACAGTGGAGAGATGGCAGAATCCTTTCCATACCGAACCAAAGCCCTC TTTGCCTTTGAAGAAATTGATGGTGTTGACCTGTGCTTCTTTGGCATGCATGTTCAAGAG TATGGCTCTGACTGCCCTCCACCCAACCAGAGGAGAGTATACATATCTTACCTCGATAGT GTTCATTTCTTCCGTCCTAAATGCTTGAGGACTGCAGTCTATCATGAAATCCTAATTGGA TATTTAGAATATGTCAAGAAATTAGGTTACACAACAGGGCATATTTGGGCATGTCCACCA AGTGAGGGAGATGATTATATCTTCCATTGCCATCCTCCTGACCAGAAGATACCCAAGCCC AAGCGACTGCAGGAATGGTACAAAAAAATGCTTGACAAGGCTGTATCAGAGCGTATTGTC CATGACTACAAGGATATTTTTAAACAAGCTACTGAAGATAGATTAACAAGTGCAAAGGAA TTGCCTTATTTCGAGGGTGATTTCTGGCCCAATGTTCTGGAAGAAAGCATTAAGGAACTG GAACAGGAGGAAGAAGAGAGAAAACGAGAGGAAAACACCAGCAATGAAAGCACAGATGTG ACCAAGGGAGACAGCAAAAATGCTAAAAAGAAGAATAATAAGAAAACCAGCAAAAATAAG AGCAGCCTGAGTAGGGGCAACAAGAAGAAACCCGGGATGCCCAATGTATCTAACGACCTC TCACAGAAACTATATGCCACCATGGAGAAGCATAAAGAGGTCTTCTTTGTGATCCGCCTC ATTGCTGGCCCTGCTGCCAACTCCCTGCCTCCCATTGTTGATCCTGATCCTCTCATCCCC TGCGATCTGATGGATGGTCGGGATGCGTTTCTCACGCTGGCAAGGGACAAGCACCTGGAG TTCTCTTCACTCCGAAGAGCCCAGTGGTCCACCATGTGCATGCTGGTGGAGCTGCACACG CAGAGCCAGGACCGCTTTGTCTACACCTGCAATGAATGCAAGCACCATGTGGAGACACGC TGGCACTGTACTGTCTGTGAGGATTATGACTTGTGTATCACCTGCTATAACACTAAAAAC CATGACCACAAAATGGAGAAACTAGGCCTTGGCTTAGATGATGAGAGCAACAACCAGCAG GCTGCAGCCACCCAGAGCCCAGGCGATTCTCGCCGCCTGAGTATCCAGCGCTGCATCCAG TCTCTGGTCCATGCTTGCCAGTGTCGGAATGCCAATTGCTCACTGCCATCCTGCCAGAAG ATGAAGCGGGTTGTGCAGCATACCAAGGGTTGCAAACGGAAAACCAATGGCGGGTGCCCC ATCTGCAAGCAGCTCATTGCCCTCTGCTGCTACCATGCCAAGCACTGCCAGGAGAACAAA TGCCCGGTGCCGTTCTGCCTAAACATCAAGCAGAAGCTCCGGCAGCAACAGCTGCAGCAC CGACTACAGCAGGCCCAAATGCTTCGCAGGAGGATGGCCAGCATGCAGCGGACTGGTGTG GTTGGGCAGCAACAGGGCCTCCCTTCCCCCACTCCTGCCACTCCAACGACACCAACTGGC CAACAGCCAACCACCCCGCAGACGCCCCAGCCCACTTCTCAGCCTCAGCCTACCCCTCCC AATAGCATGCCACCCTACTTGCCCAGGACTCAAGCTGCTGGCCCTGTGTCCCAGGGTAAG GCAGCAGGCCAGGTGACCCCTCCAACCCCTCCTCAGACTGCTCAGCCACCCCTTCCAGGG CCCCCACCTGCAGCAGTGGAAATGGCAATGCAGATTCAGAGAGCAGCGGAGACGCAGCGC CAGATGGCCCACGTGCAAATTTTTCAAAGGCCAATCCAACACCAGATGCCCCCGATGACT CCCATGGCCCCCATGGGTATGAACCCACCTCCCATGACCAGAGGTCCCAGTGGGCATTTG GAGCCAGGGATGGGACCGACAGGGATGCAGCAACAGCCACCCTGGAGCCAAGGAGGATTG CCTCAGCCCCAGCAACTACAGTCTGGGATGCCAAGGCCAGCCATGATGTCAGTGGCCCAG CATGGTCAACCTTTGAACATGGCTCCACAACCAGGATTGGGCCAGGTAGGTATCAGCCCA CTCAAACCAGGCACTGTGTCTCAACAAGCCTTACAAAACCTTTTGCGGACTCTCAGGTCT CCCAGCTCTCCCCTGCAGCAGCAACAGGTGCTTAGTATCCTTCACGCCAACCCCCAGCTG TTGGCTGCATTCATCAAGCAGCGGGCTGCCAAGTATGCCAACTCTAATCCACAACCCATC CCTGGGCAGCCTGGCATGCCCCAGGGGCAGCCAGGGCTACAGCCACCTACCATGCCAGGT CAGCAGGGGGTCCACTCCAATCCAGCCATGCAGAACATGAATCCAATGCAGGCGGGCGTT CAGAGGGCTGGCCTGCCCCAGCAGCAACCACAGCAGCAACTCCAGCCACCCATGGGAGGG ATGAGCCCCCAGGCTCAGCAGATGAACATGAACCACAACACCATGCCTTCACAATTCCGA GACATCTTGAGACGACAGCAAATGATGCAACAGCAGCAGCAACAGGGAGCAGGGCCAGGA ATAGGCCCTGGAATGGCCAACCATAACCAGTTCCAGCAACCCCAAGGAGTTGGCTACCCA CCACAGCAGCAGCAGCGGATGCAGCATCACATGCAACAGATGCAACAAGGAAATATGGGA CAGATAGGCCAGCTTCCCCAGGCCTTGGGAGCAGAGGCAGGTGCCAGTCTACAGGCCTAT CAGCAGCGACTCCTTCAGCAACAGATGGGGTCCCCTGTTCAGCCCAACCCCATGAGCCCC CAGCAGCATATGCTCCCAAATCAGGCCCAGTCCCCACACCTACAAGGCCAGCAGATCCCT AATTCTCTCTCCAATCAAGTGCGCTCTCCCCAGCCTGTCCCTTCTCCACGGCCACAGTCC CAGCCCCCCCACTCCAGTCCTTCCCCAAGGATGCAGCCTCAGCCTTCTCCACACCACGTT TCCCCACAGACAAGTTCCCCACATCCTGGACTGGTAGCTGCCCAGGCCAACCCCATGGAA CAAGGGCATTTTGCCAGCCCGGACCAGAATTCAATGCTTTCTCAGCTTGCTAGCAATCCA GGCATGGCAAACCTCCATGGTGCAAGCGCCACGGACCTGGGACTCAGCACCGATAACTCA GACTTGAATTCAAACCTCTCACAGAGTACACTAGACATACACTAG |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Protein Properties | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Number of Residues | 2414 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Molecular Weight | 264159.725 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Theoretical pI | 8.493 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Pfam Domain Function | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Signals | Not Available | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Transmembrane Regions | Not Available | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Protein Sequence |
>Histone acetyltransferase p300 MAENVVEPGPPSAKRPKLSSPALSASASDGTDFGSLFDLEHDLPDELINSTELGLTNGGD INQLQTSLGMVQDAASKHKQLSELLRSGSSPNLNMGVGGPGQVMASQAQQSSPGLGLINS MVKSPMTQAGLTSPNMGMGTSGPNQGPTQSTGMMNSPVNQPAMGMNTGMNAGMNPGMLAA GNGQGIMPNQVMNGSIGAGRGRQNMQYPNPGMGSAGNLLTEPLQQGSPQMGGQTGLRGPQ PLKMGMMNNPNPYGSPYTQNPGQQIGASGLGLQIQTKTVLSNNLSPFAMDKKAVPGGGMP NMGQQPAPQVQQPGLVTPVAQGMGSGAHTADPEKRKLIQQQLVLLLHAHKCQRREQANGE VRQCNLPHCRTMKNVLNHMTHCQSGKSCQVAHCASSRQIISHWKNCTRHDCPVCLPLKNA GDKRNQQPILTGAPVGLGNPSSLGVGQQSAPNLSTVSQIDPSSIERAYAALGLPYQVNQM PTQPQVQAKNQQNQQPGQSPQGMRPMSNMSASPMGVNGGVGVQTPSLLSDSMLHSAINSQ NPMMSENASVPSLGPMPTAAQPSTTGIRKQWHEDITQDLRNHLVHKLVQAIFPTPDPAAL KDRRMENLVAYARKVEGDMYESANNRAEYYHLLAEKIYKIQKELEEKRRTRLQKQNMLPN AAGMVPVSMNPGPNMGQPQPGMTSNGPLPDPSMIRGSVPNQMMPRITPQSGLNQFGQMSM AQPPIVPRQTPPLQHHGQLAQPGALNPPMGYGPRMQQPSNQGQFLPQTQFPSQGMNVTNI PLAPSSGQAPVSQAQMSSSSCPVNSPIMPPGSQGSHIHCPQLPQPALHQNSPSPVPSRTP TPHHTPPSIGAQQPPATTIPAPVPTPPAMPPGPQSQALHPPPRQTPTPPTTQLPQQVQPS LPAAPSADQPQQQPRSQQSTAASVPTPTAPLLPPQPATPLSQPAVSIEGQVSNPPSTSST EVNSQAIAEKQPSQEVKMEAKMEVDQPEPADTQPEDISESKVEDCKMESTETEERSTELK TEIKEEEDQPSTSATQSSPAPGQSKKKIFKPEELRQALMPTLEALYRQDPESLPFRQPVD PQLLGIPDYFDIVKSPMDLSTIKRKLDTGQYQEPWQYVDDIWLMFNNAWLYNRKTSRVYK YCSKLSEVFEQEIDPVMQSLGYCCGRKLEFSPQTLCCYGKQLCTIPRDATYYSYQNRYHF CEKCFNEIQGESVSLGDDPSQPQTTINKEQFSKRKNDTLDPELFVECTECGRKMHQICVL HHEIIWPAGFVCDGCLKKSARTRKENKFSAKRLPSTRLGTFLENRVNDFLRRQNHPESGE VTVRVVHASDKTVEVKPGMKARFVDSGEMAESFPYRTKALFAFEEIDGVDLCFFGMHVQE YGSDCPPPNQRRVYISYLDSVHFFRPKCLRTAVYHEILIGYLEYVKKLGYTTGHIWACPP SEGDDYIFHCHPPDQKIPKPKRLQEWYKKMLDKAVSERIVHDYKDIFKQATEDRLTSAKE LPYFEGDFWPNVLEESIKELEQEEEERKREENTSNESTDVTKGDSKNAKKKNNKKTSKNK SSLSRGNKKKPGMPNVSNDLSQKLYATMEKHKEVFFVIRLIAGPAANSLPPIVDPDPLIP CDLMDGRDAFLTLARDKHLEFSSLRRAQWSTMCMLVELHTQSQDRFVYTCNECKHHVETR WHCTVCEDYDLCITCYNTKNHDHKMEKLGLGLDDESNNQQAAATQSPGDSRRLSIQRCIQ SLVHACQCRNANCSLPSCQKMKRVVQHTKGCKRKTNGGCPICKQLIALCCYHAKHCQENK CPVPFCLNIKQKLRQQQLQHRLQQAQMLRRRMASMQRTGVVGQQQGLPSPTPATPTTPTG QQPTTPQTPQPTSQPQPTPPNSMPPYLPRTQAAGPVSQGKAAGQVTPPTPPQTAQPPLPG PPPAAVEMAMQIQRAAETQRQMAHVQIFQRPIQHQMPPMTPMAPMGMNPPPMTRGPSGHL EPGMGPTGMQQQPPWSQGGLPQPQQLQSGMPRPAMMSVAQHGQPLNMAPQPGLGQVGISP LKPGTVSQQALQNLLRTLRSPSSPLQQQQVLSILHANPQLLAAFIKQRAAKYANSNPQPI PGQPGMPQGQPGLQPPTMPGQQGVHSNPAMQNMNPMQAGVQRAGLPQQQPQQQLQPPMGG MSPQAQQMNMNHNTMPSQFRDILRRQQMMQQQQQQGAGPGIGPGMANHNQFQQPQGVGYP PQQQQRMQHHMQQMQQGNMGQIGQLPQALGAEAGASLQAYQQRLLQQQMGSPVQPNPMSP QQHMLPNQAQSPHLQGQQIPNSLSNQVRSPQPVPSPRPQSQPPHSSPSPRMQPQPSPHHV SPQTSSPHPGLVAAQANPMEQGHFASPDQNSMLSQLASNPGMANLHGASATDLGLSTDNS DLNSNLSQSTLDIH |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| External Links | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| GenBank ID Protein | 56202870 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| UniProtKB/Swiss-Prot ID | Q09472 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| UniProtKB/Swiss-Prot Entry Name | EP300_HUMAN | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| PDB IDs | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| GenBank Gene ID | AL035658 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| GeneCard ID | EP300 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| GenAtlas ID | EP300 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| HGNC ID | HGNC:3373 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| References | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| General References | Not Available | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||